







 本文详细介绍了一款基于Python的百度图片爬虫程序设计,包括界面设计、URL编码、图片地址解析与下载等核心步骤,实现了关键词搜索、图片批量下载及自定义下载数量和页数的功能。
本文详细介绍了一款基于Python的百度图片爬虫程序设计,包括界面设计、URL编码、图片地址解析与下载等核心步骤,实现了关键词搜索、图片批量下载及自定义下载数量和页数的功能。
我们之前写的两个小项目,都是对文字的处理和存储,而且没有与我们的动态交互,写的代码是啥就只能爬取啥内容,那么接下来我们就用百度图片讲解一下图片的下载及最简单的键入关键字搜索内容;
我们还是先分析一下我们每搜索一个内容,它的网址是怎么变化的,肯定是有所规律的,我们来总结一下:
# 我们来对比下这两个网址有什么区别
https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E6%B5%B7%E8%B4%BC%E7%8E%8B&pn=0&gsm=&ct=&ic=0&lm=-1&width=0&height=0
https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E7%81%AB%E5%BD%B1%E5%BF%8D%E8%80%85&pn=0&gsm=&ct=&ic=0&lm=-1&width=0&height=0
# 我们将word的值删掉,发现他们是完全相同的,所以唯一的变量是word
https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=&pn=0&gsm=&ct=&ic=0&lm=-1&width=0&height=0
https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=&pn=0&gsm=&ct=&ic=0&lm=-1&width=0&height=0那么带百分号的十六进制数字是什么意思呢?
我们用URL解码工具将其解码,发现 %e6%b5%b7%e8%b4%bc%e7%8e%8b 就是海贼王,这是因为为了让含有中文的URL可以正常使用,或者说加强其兼容性,我们需要对其进行一步编码;
但是我们好像发现,我们在这里直接键入中文,好像对访问结果没有什么影响,这一点我们随后论证;那么我们现在知道网址的奥秘了,那么其他的参数是什么意思呢?这点我们先不管,我们先将第一个页面的图片获取到;
ok,我们先来分析一下我们需要做哪些事情:
- 设计界面
- 获取搜索对象,并且合成网址
- 获得访问对象的网页源码
- 分析图片资源的下载地址
- 下载图片
第一步,我们先用Tkinter设计窗体界面,这一步不赘述,不会使用Tkinter的自行百度或者看我其他相关tkinter的文章: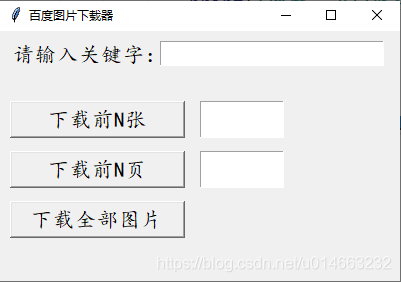
from tkinter import *
window = Tk()
window.geometry('400x250')
window.title('百度图片下载器')
Label(window,text='请输入关键字:',font=('楷体',16)).place(x=10,y=10)
keyword = Entry(window,width=20,font=('楷体',16))
keyword.place(x=160,y=10)
input_num = Entry(window,width=5,font=('楷体',24))
input_num.place(x=200,y=70)
def download_num():
print('占位')
Button(window,text='下载前N张',command=download_num,font=('楷体',16),width=15).place(x=10,y=70)
input_page = Entry(window,width=5,font=('楷体',24))
input_page.place(x=200,y=120)
def download_page():
print('占位')
Button(window,text='下载前N页',command=download_page,font=('楷体',16),width=15).place(x=10,y=120)
def download_all():
print('占位')
Button(window,text='下载全部图片',command=download_all,font=('楷体',16),width=15).place(x=10,y=170)
window.mainloop()第二步,我们需要从输入框获取关键字,合成网址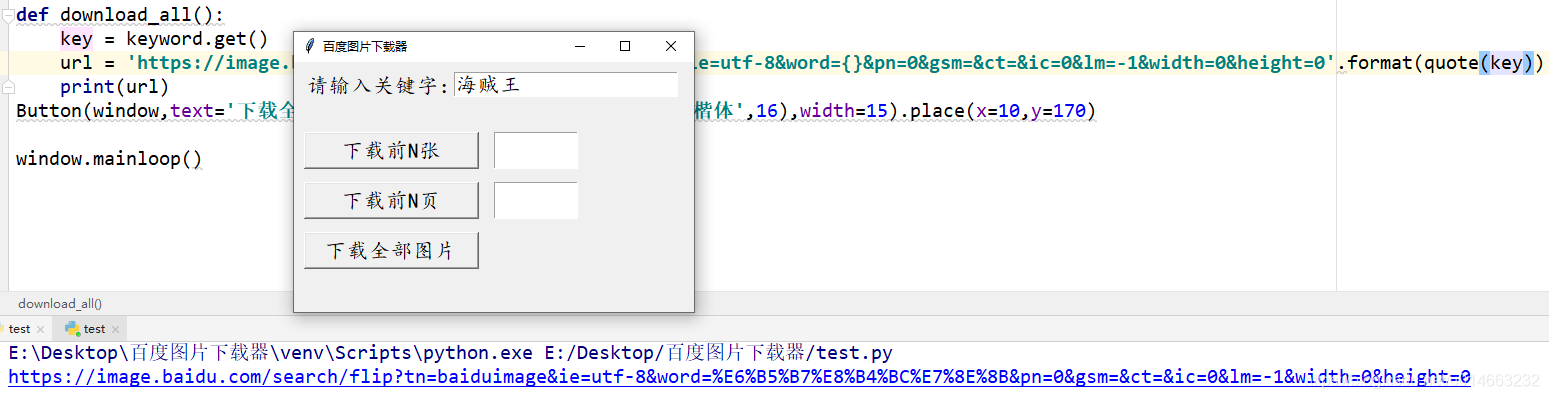
这一步其实很简单通过get()方法获取输入框的值,然后用quote()方法对其进行编码,最后合成就是我们需要的网址了,注意:quote()方法是urllib中的一个方法,这个库是自带的,不需要我们安装,我们直接导入使用就好 from urllib.request import quote ;
第三步,我们就要获取网页源码了: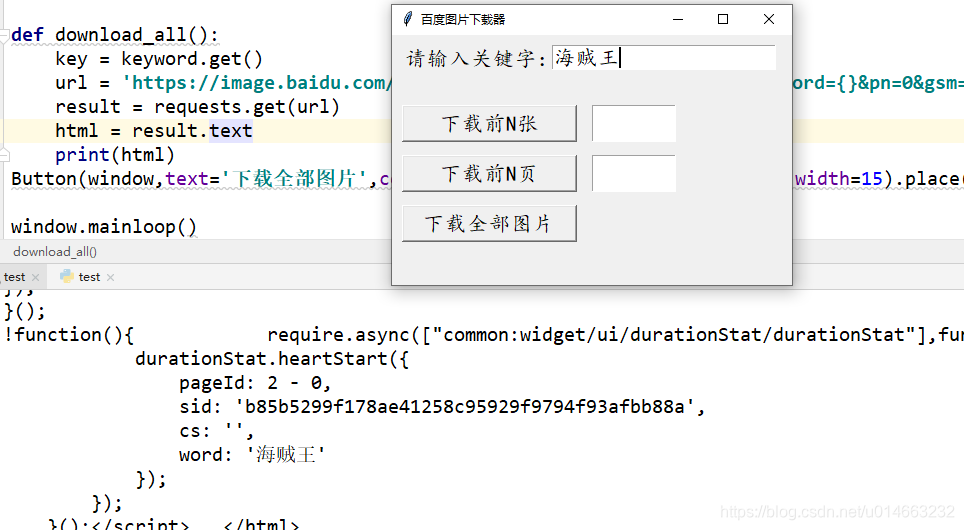
def download_all():
key = keyword.get()
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={}&pn=0&gsm=&ct=&ic=0&lm=-1&width=0&height=0'.format(quote(key))
result = requests.get(url)
html = result.text
print(html)
Button(window,text='下载全部图片',command=download_all,font=('楷体',16),width=15).place(x=10,y=170)第四步,现在源码我们已经有了,接下来就是要分析图片的下载地址了:
我们按照惯例,直接检查查看对应源码,发现确实找到了地址,但是思考一个问题,这个图片是不是相当于缩略图,就是给我们看一下的,就是说是小图,这个分辨率是肯定不行的,下载下来也没有什么意思,那么我们就要找图片的真实下载地址在哪里了:
我们搜索一下源码中所有的 ".jpg",发现下最后面部分有这么一坨东西,我们看下这一坨分别代表什么意思
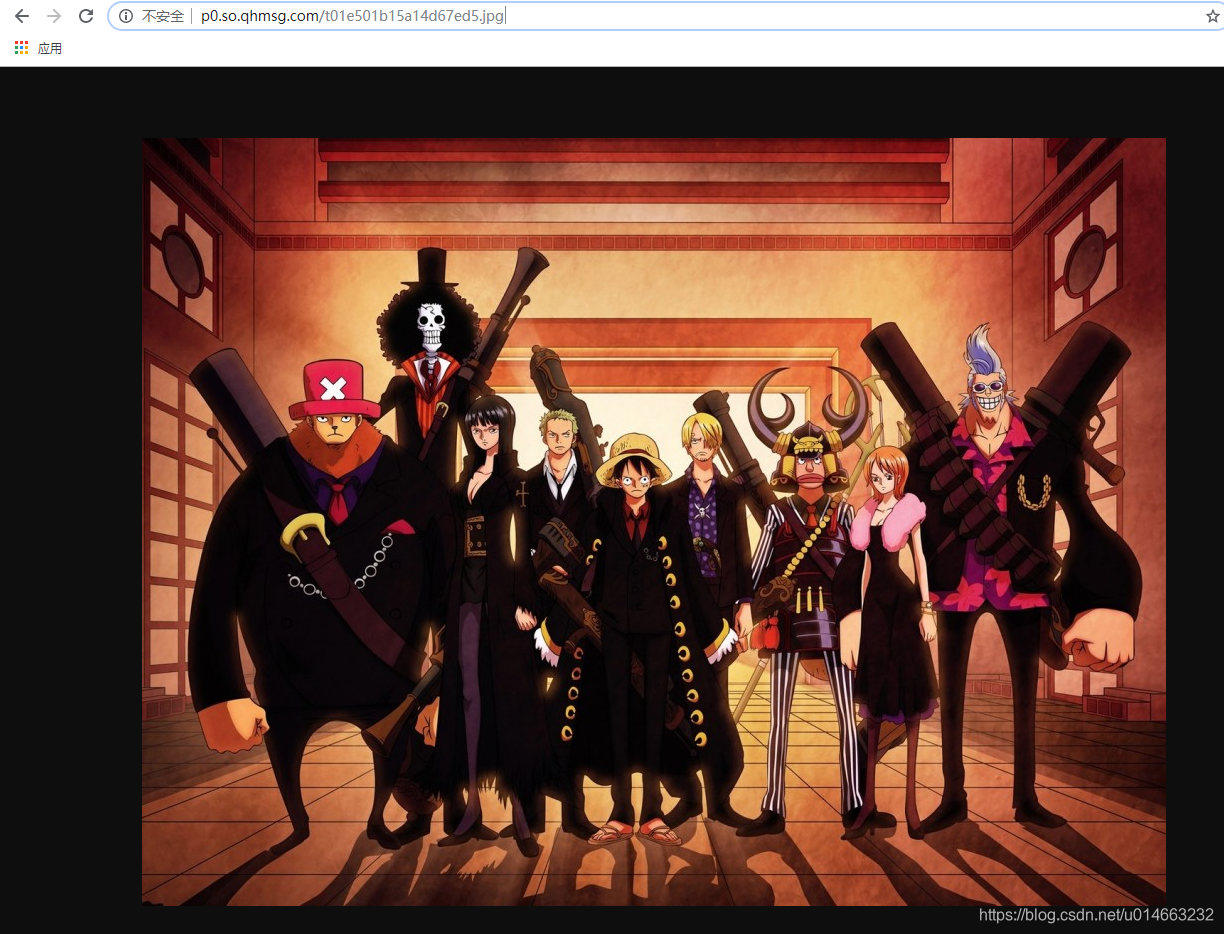
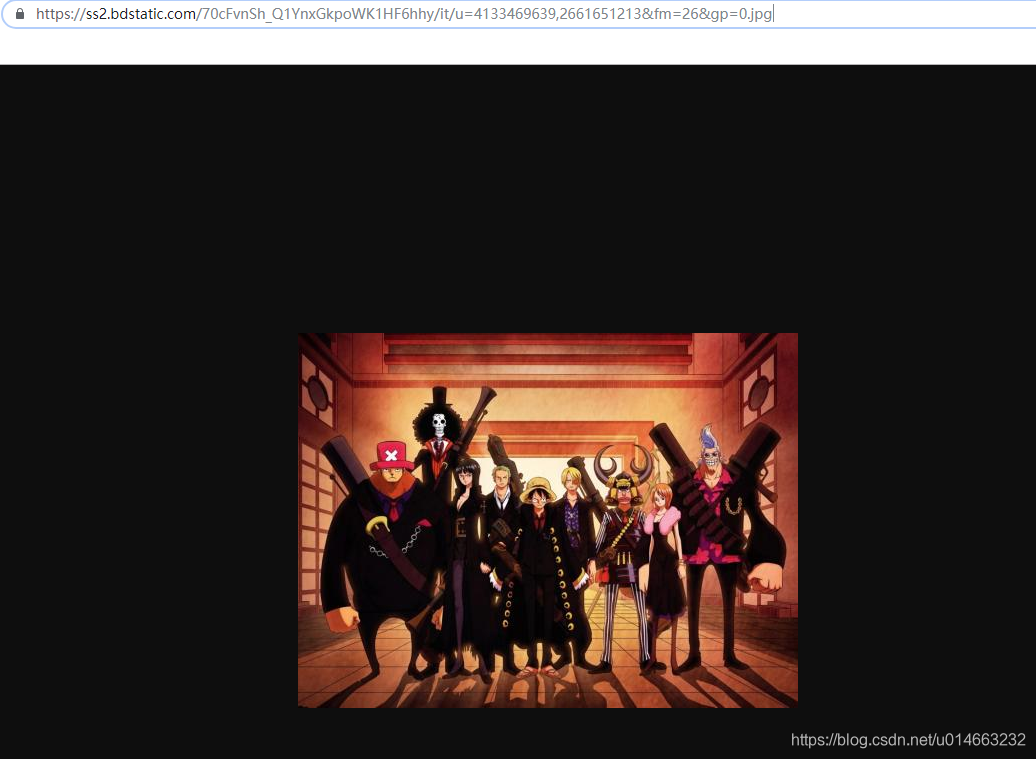
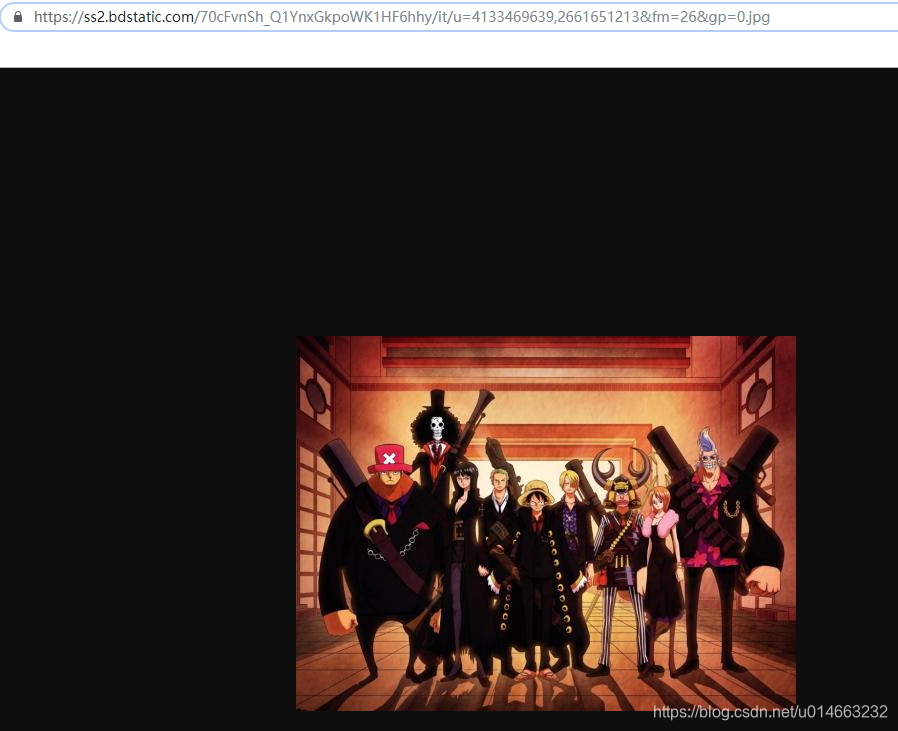
我这边只放三个,我们会发现这一块代码指向的都是同一张图片,只是图片的大小不一样,那么对应的就是图片的原链接,图片的小图,当鼠标移上去显示的图片等等等等,这个可以自行百度,所以我们需要找到最大的那一张,就是 "objURL" 所保存的,那么我们匹配的也就是这个;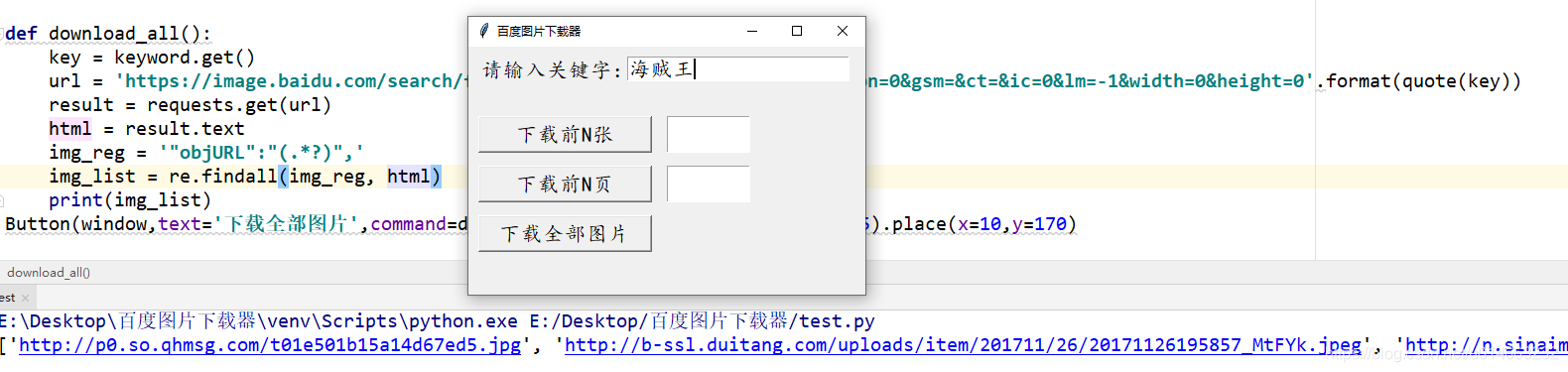
第五步,我们就需要将这些图片都下载下载: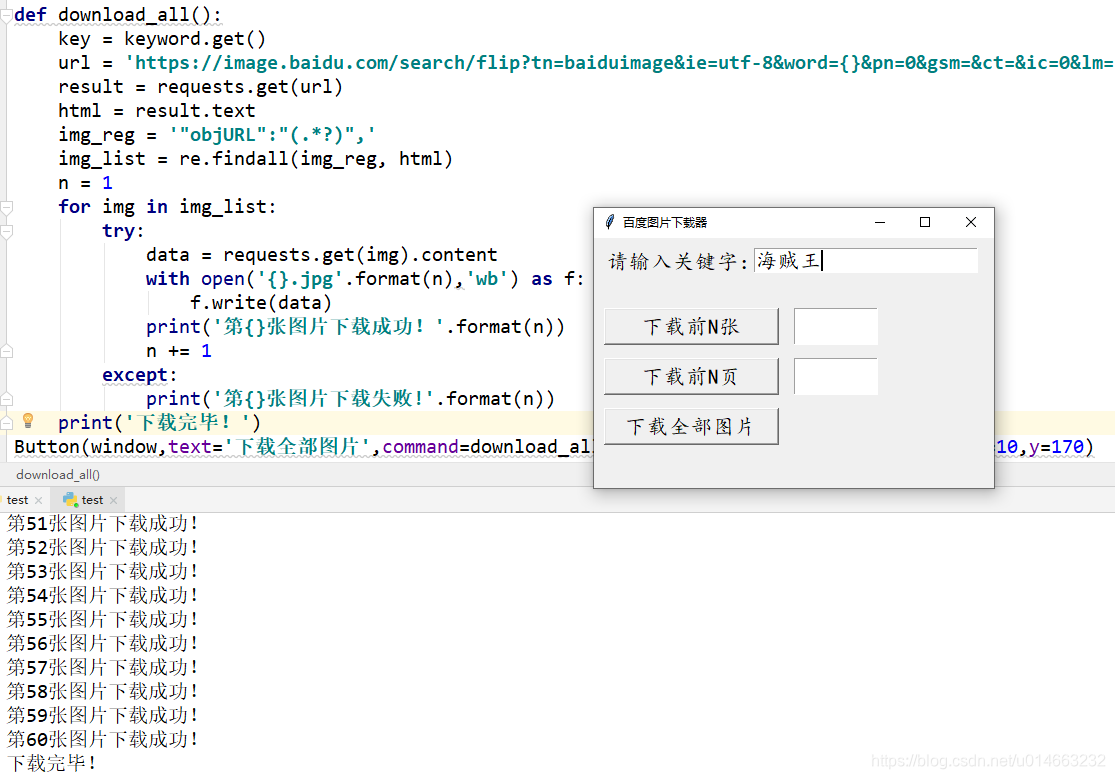
那么到现在为止,我们已经实现了图片的搜索、地址提取和下载保存,那么这只是一个页面的,我们怎么怎么实现下载所有的图片呢?
我们之前的项目都是通过拼接地址实现的效果,但是这里我们就不知道每个关键字能够搜索到多少页数据了,那么我们可以通过 “下一页” 来实现,每次获取下一页的地址,直到没有 “下一页” 那么就是最后一页了:
from tkinter import *
from urllib.request import quote # 导入模块,对url中文部分进行编码
import requests
window = Tk()
window.geometry('400x250')
window.title('百度图片下载器')
Label(window,text='请输入关键字:',font=('楷体',16)).place(x=10,y=10)
keyword = Entry(window,width=20,font=('楷体',16))
keyword.place(x=160,y=10)
def img_add(url): # 定义获取图片地址的方法
result = requests.get(url) # 发出请求
html = result.text # 获得源码
img_reg = '"objURL":"(.*?)",' # 定义匹配的规则
img_list = re.findall(img_reg,html) # 匹配图片地址
next_reg = '<a href="(.*?)" class="n">下一页</a>' # 定义下一页的匹配规则
next_url = re.findall(next_reg,html) # 匹配下一页的地址
return img_list,next_url # 返回结果
def download_all():
key = keyword.get() # 获取输入框的关键字
n = 1 # 记录下载到了第几张
if key != '': # 判断输入框是否为空
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={}&pn=0&gsm=&ct=&ic=0&lm=-1&width=0&height=0'.format(quote(key)) # 合成地址
while True: # 无限循环下载
img_list, l_url = img_add(url) # 获取图片地址和下一页地址
for img in img_list: # 遍历循环图片列表
try:
data = requests.get(img).content # 以二进制形式获取地址信息,即为图片数据
print('正在下载第{}张图片'.format(n)) # 输出现在是第几张了
with open('./image/{}.jpg'.format(n), 'wb') as f: # 保存数据
f.write(data)
n += 1 # 张数加1
except: # 如果访问或者保存错误,那么输出错误信息
print('抱歉,第{}张图片下载失败!'.format(n))
if l_url != []: # 如果下一页不是空的,那么就拼接地址
url = 'https://image.baidu.com/' + l_url[0]
else: # 反之就是说是最后一页了,跳出循环
break
print('下载完毕!')
Button(window,text='下载全部图片',command=download_all,font=('楷体',16),width=15).place(x=10,y=170)
window.mainloop()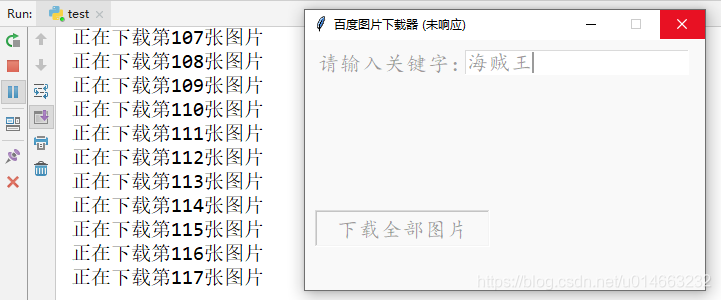
现在有一个问题,就是我们每次下载的路径都是同一个目录,很难看,而且下次下载别的图片就会替换掉之前的,理想的情况就是,每次下载都创建一个文件夹,然后将文件保存在文件夹里面,那么这张整理好,下次想要用就直接打开文件夹就好了: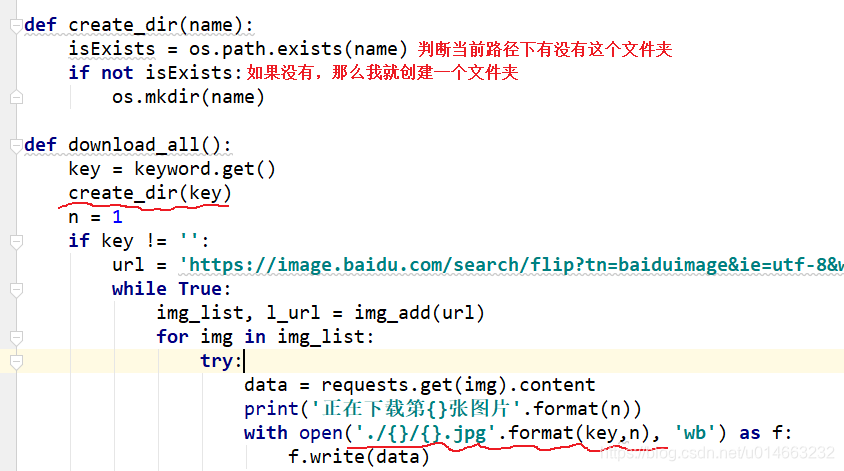
那么我的第一个功能写好了,接下来就是完成下载页和下载张数的功能了,其实都是一样的,下面直接上代码:
from tkinter import *
from urllib.request import quote
import requests
import os
window = Tk()
window.geometry('400x250')
window.title('百度图片下载器')
Label(window,text='请输入关键字:',font=('楷体',16)).place(x=10,y=10)
keyword = Entry(window,width=20,font=('楷体',16))
keyword.place(x=160,y=10)
def img_add(url):
result = requests.get(url)
html = result.text
img_reg = '"objURL":"(.*?)",'
img_list = re.findall(img_reg,html)
next_reg = '<a href="(.*?)" class="n">下一页</a>'
next_url = re.findall(next_reg,html)
return img_list,next_url
def create_dir(name):
isExists = os.path.exists(name)
if not isExists:
os.mkdir(name)
input_num = Entry(window,width=5,font=('楷体',24))
input_num.place(x=200,y=70)
def download_num():
key = keyword.get()
create_dir(key)
d_num = int(input_num.get())
n = 1
switch = True # 下载的开关
if key != '':
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={}&pn=0'.format(key)
while switch:
img_list, l_url = img_add(url)
for img in img_list:
try:
data = requests.get(img).content
print('正在下载第{}张图片'.format(n))
with open('./{}/{}.jpg'.format(key,n), 'wb') as f:
f.write(data)
n += 1
if n > d_num: # 如果下载的张数超过了设置的张数,那么关闭开关
switch = False
break
except:
print('抱歉,第{}张图片下载失败!'.format(n))
if l_url != []: # 判断是否是最后一页了
url = 'https://image.baidu.com/' + l_url[0] # 如果不是那么就拼接地址
else: # 反之就是最后一页么
if n < d_num: # 如果张数没有达到预期设置
print('抱歉,我只搜索到{}张图片'.format(n)) # 输出信息
break # 跳出循环
print('下载完毕!')
Button(window,text='下载前N张',command=download_num,font=('楷体',16),width=15).place(x=10,y=70)
input_page = Entry(window,width=5,font=('楷体',24))
input_page.place(x=200,y=120)
def download_page():
key = keyword.get()
create_dir(key)
d_page = int(input_page.get())
n_page = 0 # 存储页数
n = 1
if key != '' and key != '0':
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={}&pn=0'.format(key)
while True:
img_list, l_url = img_add(url)
for img in img_list:
try:
data = requests.get(img).content
print('正在下载第{}张图片'.format(n))
with open('./{}/{}.jpg'.format(key,n), 'wb') as f:
f.write(data)
n += 1
except:
print('抱歉,第{}张图片下载失败!'.format(n))
n_page += 1
if l_url != []:
if n_page >= d_page:
break
url = 'https://image.baidu.com/' + l_url[0]
else:
if n_page < d_page:
print('抱歉,我只搜索到{}页图片'.format(n_page))
break
print('下载完毕!')
Button(window,text='下载前N页',command=download_page,font=('楷体',16),width=15).place(x=10,y=120)
def download_all():
key = keyword.get()
create_dir(key)
n = 1
if key != '':
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={}&pn=0&gsm=&ct=&ic=0&lm=-1&width=0&height=0'.format(quote(key))
while True:
img_list, l_url = img_add(url)
for img in img_list:
try:
data = requests.get(img).content
print('正在下载第{}张图片'.format(n))
with open('./{}/{}.jpg'.format(key,n), 'wb') as f:
f.write(data)
n += 1
except:
print('抱歉,第{}张图片下载失败!'.format(n))
if l_url != []:
url = 'https://image.baidu.com/' + l_url[0]
else:
break
print('下载完毕')
Button(window,text='下载全部图片',command=download_all,font=('楷体',16),width=15).place(x=10,y=170)
window.mainloop()最后一步,我们既然已经把程序写好了,想要运行每次都得打开程序,那么我们能否像应用程序一样打包生成exe文件,下次想要用直接运行软件就好了;(如何打包,看另外一篇文章)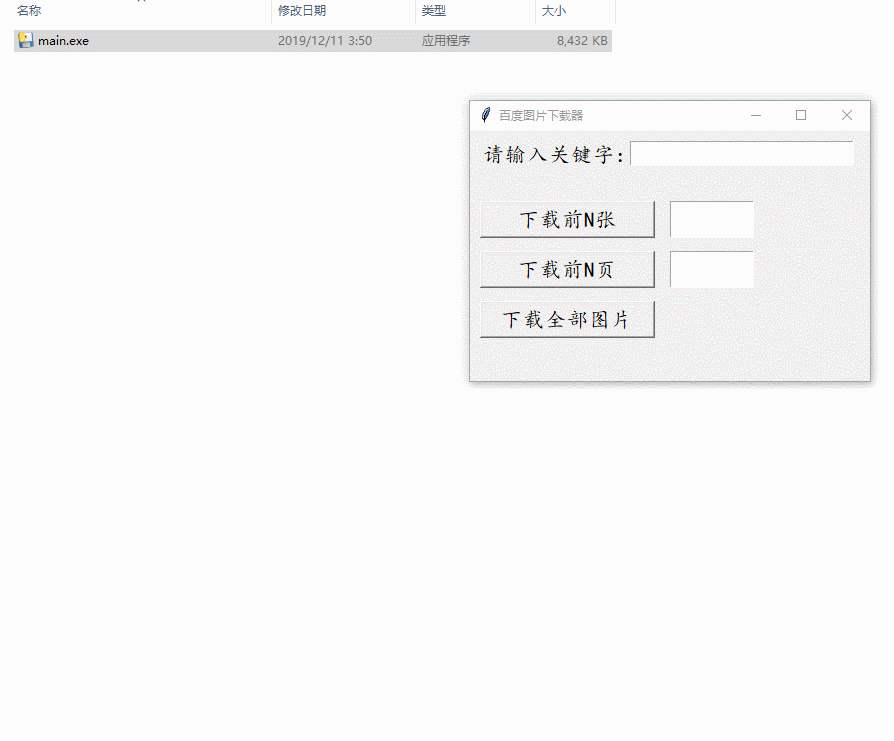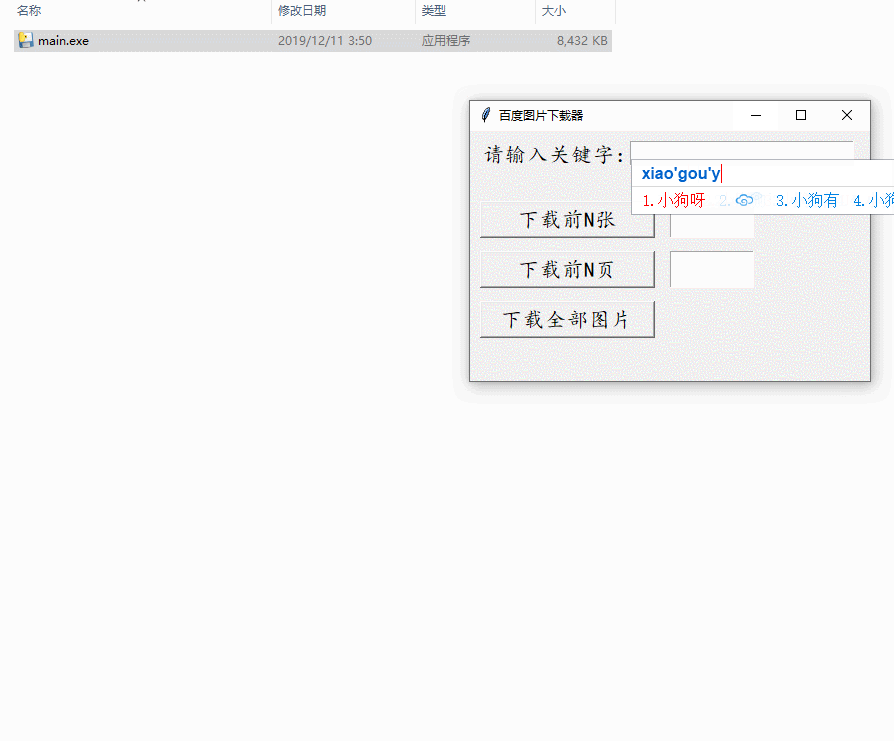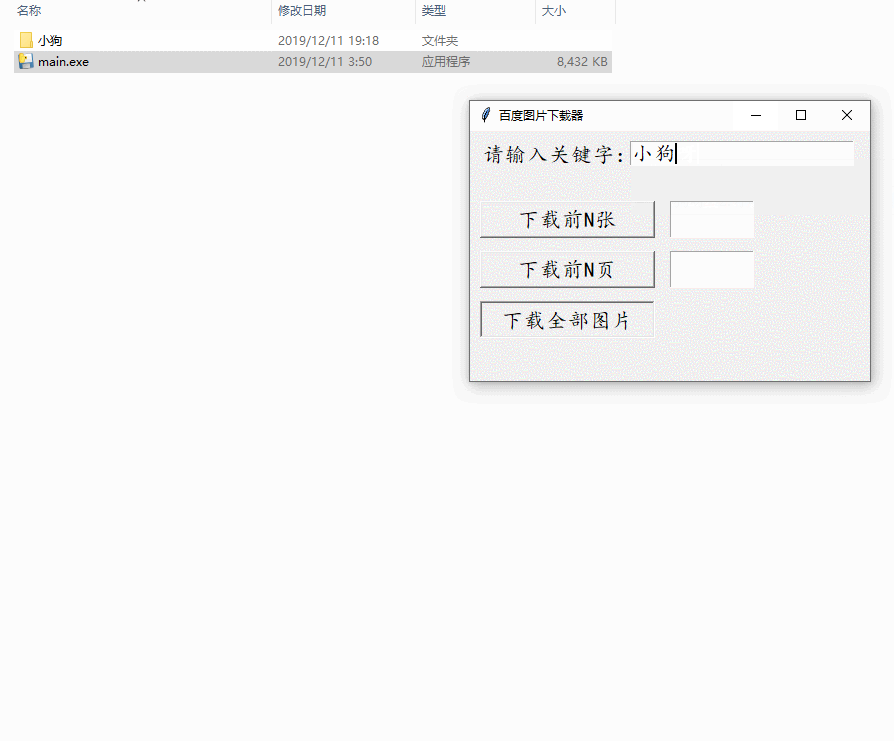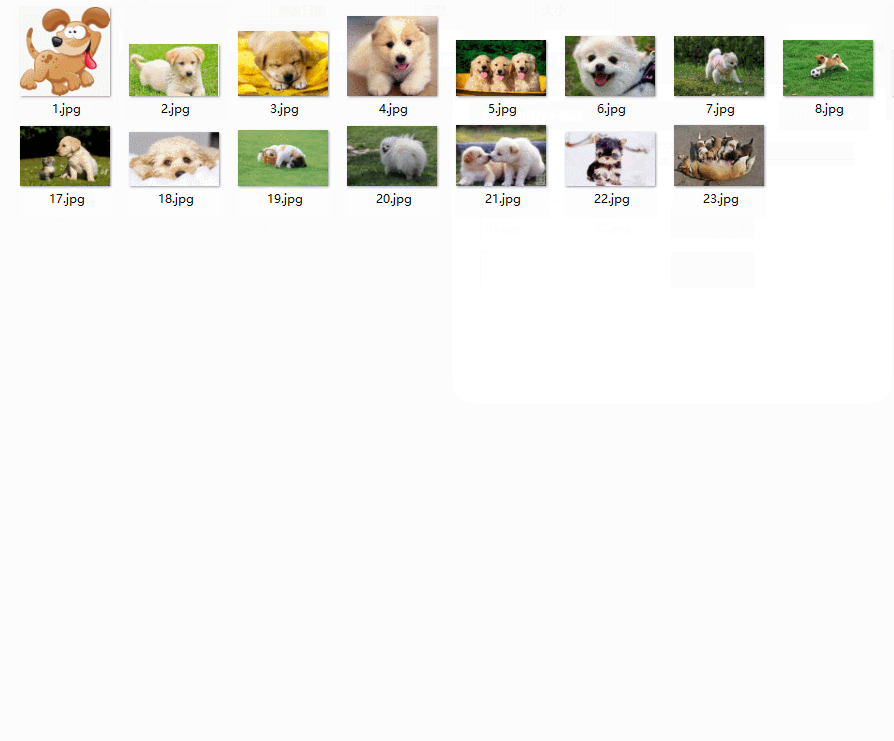

















 1746
1746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









