






从上手到使用,差不多经历过了一段时间,我有一个学习习惯,那就是学习的时候通过需求驱动,先把要完成的任务完成了,有什么问题整理下来,之后再一次性解决,这样能保证周期性的工作效率,不至于拖到ddl,还是少废话了…ORZ
(本文参考自博主博客)
- 1、MapReduce简介
- 2、MapReduce有哪些角色?各自的作用是什么?
- 3、MapReduce程序执行流程
- 4、MapReduce工作原理
- 5、MapReduce中Shuffle过程
- 6、MapReduce编程主要组件
- 7、针对MapReduce的缺点,YARN解决了什么?
1、MapReduce简介
MapReduce是一种并行可扩展计算模型,并且有较好的容错性,主要解决海量离线数据的批处理。实现下面目标
★ 易于编程
★ 良好的扩展性
★ 高容错性
2、MapReduce有哪些角色?各自的作用是什么?
MapReduce由JobTracker和TaskTracker组成。JobTracker负责资源管理和作业控制,TaskTracker负责任务的运行。
3、MapReduce程序执行流程
程序执行流程图如下:
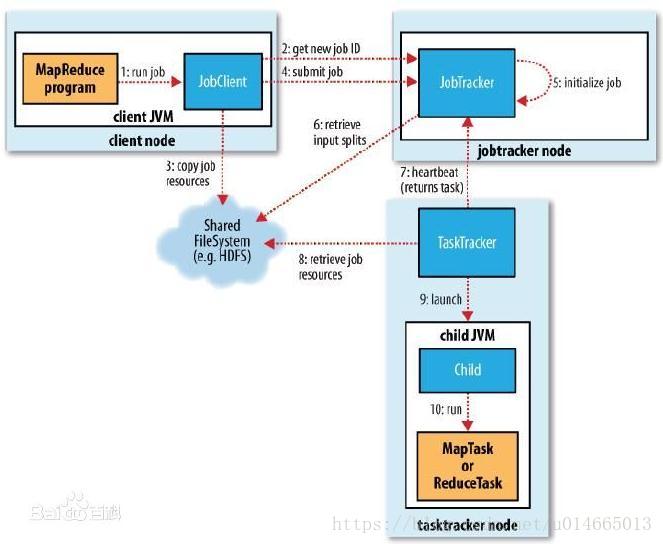
(1) 开发人员编写好MapReduce program,将程序打包运行。
(2) JobClient向JobTracker申请可用Job,JobTracker返回JobClient一个可用Job ID。
(3) JobClient得到Job ID后,将运行Job所需要的资源拷贝到共享文件系统HDFS中。
(4) 资源准备完备后,JobClient向JobTracker提交Job。
(5) JobTracker收到提交的Job后,初始化Job。
(6) 初始化完成后,JobTracker从HDFS中获取输入splits(作业可以该启动多少Mapper任务)。
(7) 与此同时,TaskTracker不断地向JobTracker汇报心跳信息,并且返回要执行的任务。
(8) TaskTracker得到JobTracker分配(尽量满足数据本地化)的任务后,向HDFS获取Job资源(若数据是本地的,不需拷贝数据)。
(9) 获取资源后,TaskTracker会开启JVM子进程运行任务。
注:
(3)中资源具体指什么?主要包含:
● 程序jar包、作业配置文件xml
● 输入划分信息,决定作业该启动多少个map任务
● 本地文件,包含依赖的第三方jar包(-libjars)、依赖的归档文件(-archives)和普通文件(-files),如果已经上传,则不需上传
4、MapReduce工作原理
工作原理图如下:
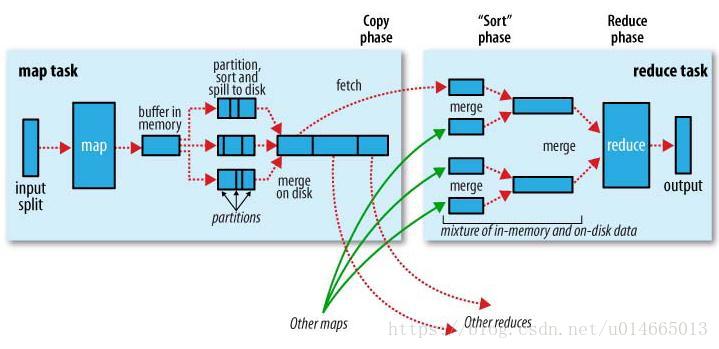
map task
程序会根据InputFormat将输入文件分割成splits,每个split会作为一个map task的输入,每个map task会有一个内存缓冲区,输入数据经过map阶段处理后的中间结果会写入内存缓冲区,并且决定数据写入到哪个partitioner,当写入的数据到达内存缓冲区的的阀值(默认是0.8),会启动一个线程将内存中的数据溢写入磁盘,同时不影响map中间结果继续写入缓冲区。在溢写过程中,MapReduce框架会对key进行排序,如果中间结果比较大,会形成多个溢写文件,最后的缓冲区数据也会全部溢写入磁盘形成一个溢写文件(最少有一个溢写文件),如果是多个溢写文件,则最后合并所有的溢写文件为一个文件。
reduce task
当所有的map task完成后,每个map task会形成一个最终文件,并且该文件按区划分。reduce任务启动之前,一个map task完成后,就会启动线程来拉取map结果数据到相应的reduce task,不断地合并数据,为reduce的数据输入做准备,当所有的map tesk完成后,
数据也拉取合并完毕后,reduce task 启动,最终将输出输出结果存入HDFS上。
5、MapReduce中Shuffle过程
Shuffle的过程:描述数据从map task输出到reduce task输入的这段过程。
我们对Shuffle过程的期望是:
★ 完整地从map task端拉取数据到reduce task端
★ 跨界点拉取数据时,尽量减少对带宽的不必要消耗
★ 减小磁盘IO对task执行的影响
先看map端:
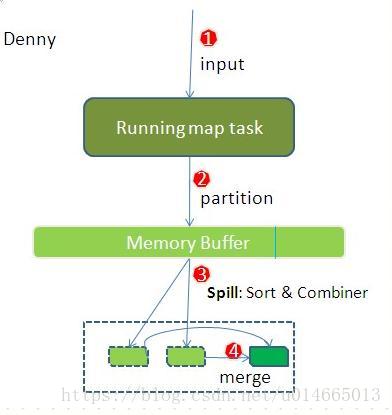
split被送入map task后,程序库决定数据结果数据属于哪个partitioner,写入到内存缓冲区,到达阀值,开启溢写过程,进行key排序,
如果有combiner步骤,则会对相同的key做归并处理,最终多个溢写文件合并为一个文件。
再看reduce端:
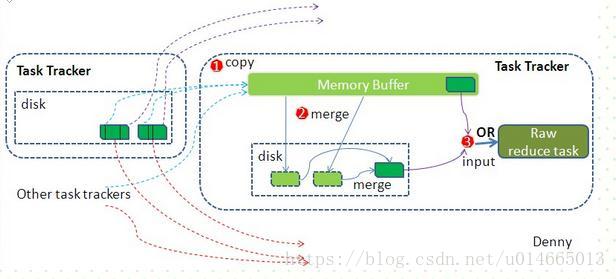
多个map task形成的最终文件的对应partitioner会被对应的reduce task拉取至内存缓冲区,对可能形成多个溢写文件合并,最终
作为resuce task的数据输入 。
6、MapReduce编程主要组件
InputFormat类:分割成多个splits和每行怎么解析。
Mapper类:对输入的每对
public static void main(String[] args)throws IOException {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(Mapper.class);
job.setCombinerClass(null);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(Reducer.class);
job.setOutputFormatClass(TextOutFormat.class);
}
}7、针对MapReduce的缺点,YARN解决了什么?
MapReduce由以下缺点:
★ JobTracker挂掉,整个作业挂掉,存在单点故障
★ JobTracker既负责资源管理又负责作业控制,当作业增多时,JobTracker内存是扩展的瓶颈
★ map task全部完成后才能执行reduce task,造成资源空闲浪费
YARN设计考虑以上缺点,对MapReduce重新设计:
★ 将JobTracker职责分离,ResouceManager全局资源管理,ApplicationMaster管理作业的调度
★ 对ResouceManager做了HA设计
★ 设计了更细粒度的抽象资源容器Container














 1535
1535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









