










【问题描述】:
需求:对员工信息进行聚合分析
1.先对员工按照国家country分组,然后再按入职年限join_date进行分组,分组后在计算组内平均薪资
员工数据如下:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 5,
"max_score": 1,
"hits": [
{
"_index": "company",
"_type": "employee",
"_id": "5",
"_score": 1,
"_source": {
"name": "mike",
"age": 37,
"position": "finance manager",
"country": "usa",
"join_date": "2015-01-01",
"salary": 15000
}
},
{
"_index": "company",
"_type": "employee",
"_id": "2",
"_score": 1,
"_source": {
"name": "marry",
"age": 35,
"position": "technique manager",
"country": "china",
"join_date": "2017-01-01",
"salary": 12000
}
},
{
"_index": "company",
"_type": "employee",
"_id": "4",
"_score": 1,
"_source": {
"name": "jen",
"age": 25,
"position": "junior finance",
"country": "usa",
"join_date": "2016-01-01",
"salary": 7000
}
},
{
"_index": "company",
"_type": "employee",
"_id": "1",
"_score": 1,
"_source": {
"name": "jack",
"age": 27,
"position": "technique",
"country": "china",
"join_date": "2017-01-01",
"salary": 10000
}
},
{
"_index": "company",
"_type": "employee",
"_id": "3",
"_score": 1,
"_source": {
"name": "tom",
"age": 32,
"position": "senior technique software",
"country": "china",
"join_date": "2016-01-01",
"salary": 11000
}
}
]
}
}
《图1》
no modules loaded
loaded plugin [org.elasticsearch.index.reindex.ReindexPlugin]
loaded plugin [org.elasticsearch.join.ParentJoinPlugin]
loaded plugin [org.elasticsearch.percolator.PercolatorPlugin]
loaded plugin [org.elasticsearch.script.mustache.MustachePlugin]
loaded plugin [org.elasticsearch.transport.Netty4Plugin]
Exception in thread "main" Failed to execute phase [query], all shards failed; shardFailures {[yWbGC_XwQsyJXKZD3kIDgQ][company][0]: RemoteTransportException[[yWbGC_X][127.0.0.1:9300][indices:data/read/search[phase/query]]]; nested: IllegalArgumentException[Fielddata is disabled on text fields by default. Set fielddata=true on [country] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.]; }{[yWbGC_XwQsyJXKZD3kIDgQ][company][1]: RemoteTransportException[[yWbGC_X][127.0.0.1:9300][indices:data/read/search[phase/query]]]; nested: IllegalArgumentException[Fielddata is disabled on text fields by default. Set fielddata=true on [country] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.]; }{[yWbGC_XwQsyJXKZD3kIDgQ][company][2]: RemoteTransportException[[yWbGC_X][127.0.0.1:9300][indices:data/read/search[phase/query]]]; nested: IllegalArgumentException[Fielddata is disabled on text fields by default. Set fielddata=true on [country] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.]; }{[yWbGC_XwQsyJXKZD3kIDgQ][company][3]: RemoteTransportException[[yWbGC_X][127.0.0.1:9300][indices:data/read/search[phase/query]]]; nested: IllegalArgumentException[Fielddata is disabled on text fields by default. Set fielddata=true on [country] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.]; }{[yWbGC_XwQsyJXKZD3kIDgQ][company][4]: RemoteTransportException[[yWbGC_X][127.0.0.1:9300][indices:data/read/search[phase/query]]]; nested: IllegalArgumentException[Fielddata is disabled on text fields by default. Set fielddata=true on [country] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.]; }
at org.elasticsearch.action.search.AbstractSearchAsyncAction.onPhaseFailure(AbstractSearchAsyncAction.java:274)
at org.elasticsearch.action.search.AbstractSearchAsyncAction.executeNextPhase(AbstractSearchAsyncAction.java:132)
at org.elasticsearch.action.search.AbstractSearchAsyncAction.onPhaseDone(AbstractSearchAsyncAction.java:243)
at org.elasticsearch.action.search.InitialSearchPhase.onShardFailure(InitialSearchPhase.java:107)
at org.elasticsearch.action.search.InitialSearchPhase.access$100(InitialSearchPhase.java:49)
at org.elasticsearch.action.search.InitialSearchPhase$2.lambda$onFailure$1(InitialSearchPhase.java:217)
at org.elasticsearch.action.search.InitialSearchPhase.maybeFork(InitialSearchPhase.java:171)
at org.elasticsearch.action.search.InitialSearchPhase.access$000(InitialSearchPhase.java:49)
at org.elasticsearch.action.search.InitialSearchPhase$2.onFailure(InitialSearchPhase.java:217)
at org.elasticsearch.action.search.SearchExecutionStatsCollector.onFailure(SearchExecutionStatsCollector.java:73)
at org.elasticsearch.action.ActionListenerResponseHandler.handleException(ActionListenerResponseHandler.java:51)
at org.elasticsearch.action.search.SearchTransportService$ConnectionCountingHandler.handleException(SearchTransportService.java:527)
at org.elasticsearch.transport.TransportService$ContextRestoreResponseHandler.handleException(TransportService.java:1098)
at org.elasticsearch.transport.TransportService$DirectResponseChannel.processException(TransportService.java:1191)
at org.elasticsearch.transport.TransportService$DirectResponseChannel.sendResponse(TransportService.java:1175)
at org.elasticsearch.transport.TaskTransportChannel.sendResponse(TaskTransportChannel.java:66)
at org.elasticsearch.action.search.SearchTransportService$6$1.onFailure(SearchTransportService.java:385)
at org.elasticsearch.search.SearchService$2.onFailure(SearchService.java:324)
at org.elasticsearch.search.SearchService$2.onResponse(SearchService.java:318)
at org.elasticsearch.search.SearchService$2.onResponse(SearchService.java:312)
at org.elasticsearch.search.SearchService$3.doRun(SearchService.java:1002)
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:672)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37)
at org.elasticsearch.common.util.concurrent.TimedRunnable.doRun(TimedRunnable.java:41)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: NotSerializableExceptionWrapper[: Fielddata is disabled on text fields by default. Set fielddata=true on [country] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.]; nested: IllegalArgumentException[Fielddata is disabled on text fields by default. Set fielddata=true on [country] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.];
at org.elasticsearch.ElasticsearchException.guessRootCauses(ElasticsearchException.java:619)
at org.elasticsearch.action.search.SearchPhaseExecutionException.guessRootCauses(SearchPhaseExecutionException.java:170)
at org.elasticsearch.action.search.SearchPhaseExecutionException.getCause(SearchPhaseExecutionException.java:111)
at org.elasticsearch.ElasticsearchException.writeTo(ElasticsearchException.java:286)
at org.elasticsearch.action.search.SearchPhaseExecutionException.writeTo(SearchPhaseExecutionException.java:61)
at org.elasticsearch.common.io.stream.StreamOutput.writeException(StreamOutput.java:864)
at org.elasticsearch.ElasticsearchException.writeTo(ElasticsearchException.java:286)
at org.elasticsearch.transport.ActionTransportException.writeTo(ActionTransportException.java:59)
at org.elasticsearch.common.io.stream.StreamOutput.writeException(StreamOutput.java:864)
at org.elasticsearch.transport.TcpTransport.sendErrorResponse(TcpTransport.java:1151)
at org.elasticsearch.transport.TcpTransportChannel.sendResponse(TcpTransportChannel.java:71)
at org.elasticsearch.transport.TaskTransportChannel.sendResponse(TaskTransportChannel.java:66)
at org.elasticsearch.action.support.HandledTransportAction$TransportHandler$1.onFailure(HandledTransportAction.java:92)
at org.elasticsearch.action.search.AbstractSearchAsyncAction.raisePhaseFailure(AbstractSearchAsyncAction.java:222)
... 28 more
Caused by: java.lang.IllegalArgumentException: Fielddata is disabled on text fields by default. Set fielddata=true on [country] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.
at org.elasticsearch.index.mapper.TextFieldMapper$TextFieldType.fielddataBuilder(TextFieldMapper.java:301)
at org.elasticsearch.index.fielddata.IndexFieldDataService.getForField(IndexFieldDataService.java:115)
at org.elasticsearch.index.query.QueryShardContext.getForField(QueryShardContext.java:165)
at org.elasticsearch.search.aggregations.support.ValuesSourceConfig.resolve(ValuesSourceConfig.java:96)
at org.elasticsearch.search.aggregations.support.ValuesSourceAggregationBuilder.resolveConfig(ValuesSourceAggregationBuilder.java:294)
at org.elasticsearch.search.aggregations.support.ValuesSourceAggregationBuilder.doBuild(ValuesSourceAggregationBuilder.java:287)
at org.elasticsearch.search.aggregations.support.ValuesSourceAggregationBuilder.doBuild(ValuesSourceAggregationBuilder.java:36)
at org.elasticsearch.search.aggregations.AbstractAggregationBuilder.build(AbstractAggregationBuilder.java:132)
at org.elasticsearch.search.aggregations.AggregatorFactories$Builder.build(AggregatorFactories.java:329)
at org.elasticsearch.search.SearchService.parseSource(SearchService.java:749)
at org.elasticsearch.search.SearchService.createContext(SearchService.java:558)
at org.elasticsearch.search.SearchService.createAndPutContext(SearchService.java:534)
at org.elasticsearch.search.SearchService.executeQueryPhase(SearchService.java:330)
at org.elasticsearch.search.SearchService$2.onResponse(SearchService.java:316)
... 9 more
Process finished with exit code 1
《日志1》
【定为分析】:
1.报错信息如《图1》,考虑原因:a.导错包,b.es版本不兼容
a.比对后导包正常
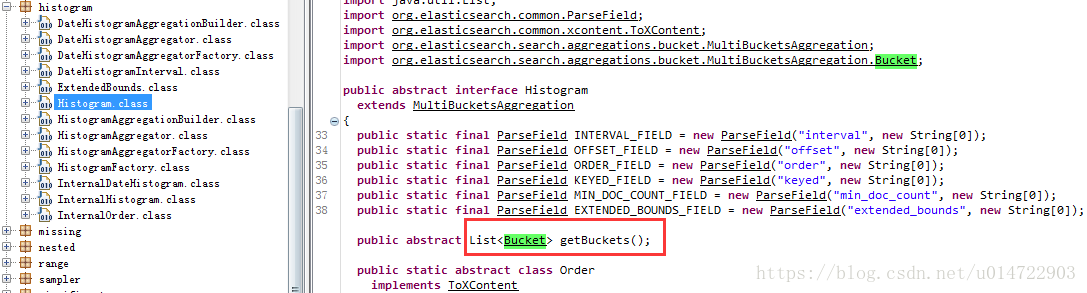
b.查看es的jar包源码如下:
elasticsearch-5.2.2.jar如下图

而elasticsearch-6.0.1.jar如下图:
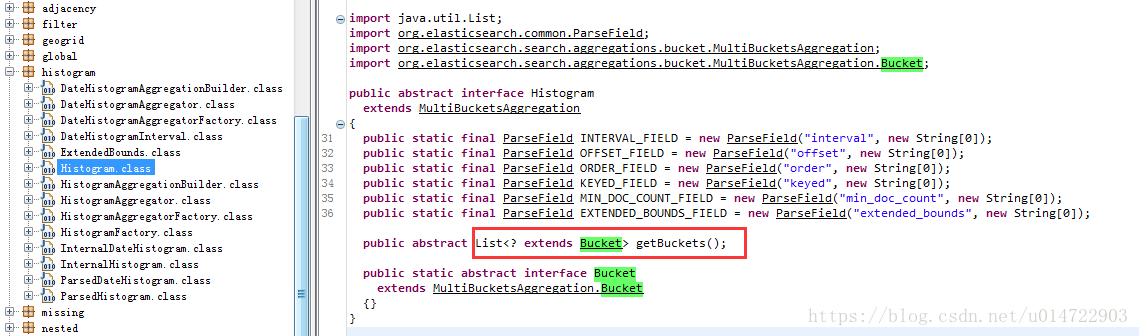
getBuckets方法在6.x版本中获取的集合对象为Bucket的子类,使用强转将类型转化;
while(groupByCountryBucketInterator.hasNext()) {
StringTerms.Bucket groupByCountryBucket = groupByCountryBucketInterator.next();
System.out.println(groupByCountryBucket.getKey()+":"+groupByCountryBucket.getDocCount());
Histogram groupByJoinDate = (Histogram)groupByCountryBucket.getAggregations().asMap().get("group_by_join_date");
// Iterator<org.elasticsearch.search.aggregations.bucket.histogram.Histogram.Bucket> groupByJoinDateBucketIterator = groupByJoinDate.getBuckets().iterator();
Iterator<Histogram.Bucket> groupByJoinDateBucketIterator = (Iterator<Histogram.Bucket>)groupByJoinDate.getBuckets().iterator();
while(groupByJoinDateBucketIterator.hasNext()) {
Histogram.Bucket groupByJoinDateBucket = groupByJoinDateBucketIterator.next();
System.out.println(groupByJoinDateBucket.getKey() + ":" +groupByJoinDateBucket.getDocCount());
Avg avg = (Avg) groupByJoinDateBucket.getAggregations().asMap().get("avg_salary");
System.out.println(avg.getValue());
}
}b.2 编译通过后,运行程序,报错日志如【问题描述】中的《日志1》:
text类型的数据会按照倒排索引的方式进行分词,官方文档解释该字段会被加载到堆中,消耗大量的堆空间,导致用户体验延迟,所以默认情况下禁用fielddata字段,默认值为false;
但是对此文本字段上的脚本进行排序、聚合或访问值时会出现:Fielddata is disabled on text fields by default 异常
即若使用聚合,需设置此字段的fielddata值为true;
在5.2版本的es中mapping创建后,不能修改_mapping的fielddata值。在6.x版本中可以进行修改,方式如下:
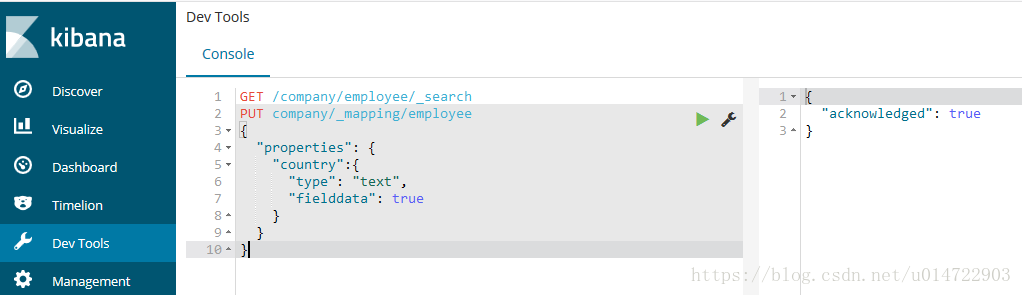
【问题根因】:
1.es的jar包版本不一样,api差异;
2.es版本差异;
【解决方案】:
getBuckets方法在6.x版本中获取的集合对象为Bucket的子类,使用强转将类型转化;
while(groupByCountryBucketInterator.hasNext()) {
StringTerms.Bucket groupByCountryBucket = groupByCountryBucketInterator.next();
System.out.println(groupByCountryBucket.getKey()+":"+groupByCountryBucket.getDocCount());
Histogram groupByJoinDate = (Histogram)groupByCountryBucket.getAggregations().asMap().get("group_by_join_date");
// Iterator<org.elasticsearch.search.aggregations.bucket.histogram.Histogram.Bucket> groupByJoinDateBucketIterator = groupByJoinDate.getBuckets().iterator();
Iterator<Histogram.Bucket> groupByJoinDateBucketIterator = (Iterator<Histogram.Bucket>)groupByJoinDate.getBuckets().iterator();
while(groupByJoinDateBucketIterator.hasNext()) {
Histogram.Bucket groupByJoinDateBucket = groupByJoinDateBucketIterator.next();
System.out.println(groupByJoinDateBucket.getKey() + ":" +groupByJoinDateBucket.getDocCount());
Avg avg = (Avg) groupByJoinDateBucket.getAggregations().asMap().get("avg_salary");
System.out.println(avg.getValue());
}
}设置country字段的fielddata值为true;
【归纳总结】:
es版本之间的差异较大,在语法及应用时需根据当前版本随机应变,了解各个版本为解决哪些问题做了哪些修改;














 2550
2550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









