







推荐算法种类繁多,分支很多,创新性强,往往一个算法能分支创新出很多新的推荐算法,下图给出了几种有代表性的推荐算法,并在后面做详细解释。
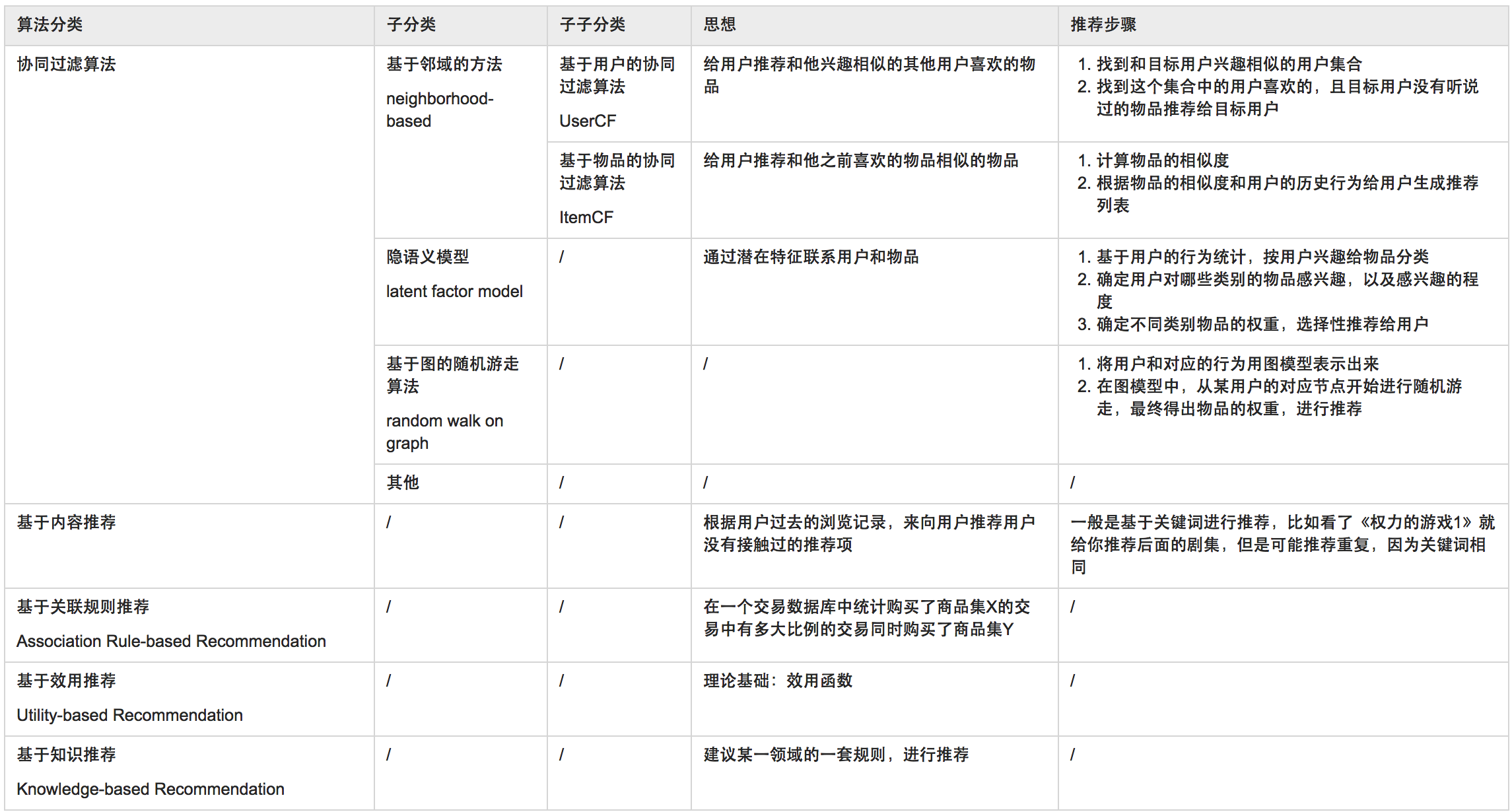
******************************协同过滤算法***********************************************
1. 协同过滤的简介
关于协同过滤的一个最经典的例子就是看电影,有时候不知道哪一部电影是我们喜欢的或者评分比较高的,那
么通常的做法就是问问周围的朋友,看看最近有什么好的电影推荐。在问的时候,都习惯于问跟自己口味差不
多的朋友,这就是协同过滤的核心思想。
协同过滤是在海量数据中挖掘出小部分与你品味类似的用户,在协同过滤中,这些用户成为邻居,然后根据他
们喜欢的东西组织成一个排序的目录推荐给你。所以就有如下两个核心问题
(1)如何确定一个用户是否与你有相似的品味?
(2)如何将邻居们的喜好组织成一个排序目录?
协同过滤算法的出现标志着推荐系统的产生,协同过滤算法包括基于用户和基于物品的协同过滤算法。
2. 协同过滤的核心
要实现协同过滤,需要进行如下几个步骤
(1)收集用户偏好
(2)找到相似的用户或者物品
(3)计算并推荐
一, 收集用户偏好
从用户的行为和偏好中发现规律,并基于此进行推荐,所以如何收集用户的偏好信息成为系统推荐效果最基础
的决定因素。用户有很多种方式向系统提供自己的偏好信息,比如:评分,投票,转发,保存书签,购买,点
击流,页面停留时间等等。
以上的用户行为都是通用的,在实际推荐引擎设计中可以自己多添加一些特定的用户行为,并用它们表示用户
对物品的喜好程度。通常情况下,在一个推荐系统中,用户行为都会多于一种,那么如何组合这些不同的用户
行为呢 ?基本上有如下两种方式
(1)将不同的行为分组
一般可以分为查看和购买,然后基于不同的用户行为,计算不同用户或者物品的相似度。类似与当当网或者
亚马逊给出的“购买了该书的人还购买了”,“查看了该书的人还查看了”等等。
(2)不同行为产生的用户喜好对它们进行加权
对不同行为产生的用户喜好进行加权,然后求出用户对物品的总体喜好。
好了,当我们收集好用户的行为数据后,还要对数据进行预处理,最核心的工作就是减噪和归一化。
减噪: 因为用户数据在使用过程中可能存在大量噪音和误操作,所以需要过滤掉这些噪音。
归一化:不同行为数据的取值相差可能很好,例如用户的查看数据肯定比购买数据大得多。通过归一化,才能
使数据更加准确。
通过上述步骤的处理,就得到了一张二维表,其中一维是用户列表,另一维是商品列表,值是用户对商品的喜
好。还是以电影推荐为例,如下表
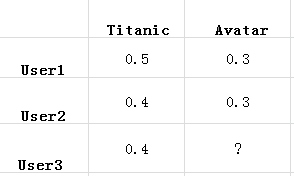
二, 找到相似的用户或物品
对用户的行为分析得到用户的喜好后,可以根据用户的喜好计算相似用户和物品,然后可以基于相似用户或物
品进行推荐。这就是协同过滤中的两个分支了,基于用户的和基于物品的协同过滤。
关于相似度的计算有很多种方法,比如常用的余弦夹角,欧几里德距离度量,皮尔逊相关系数等等。而如果采
用欧几里德度量,那么可以用如下公式来表示相似度
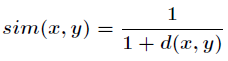
在计算用户之间的相似度时,是将一个用户对所有物品的偏好作为一个向量,而在计算物品之间的相似度时,
是将所有用户对某个物品的偏好作为一个向量。求出相似度后,接下来可以求相似邻居了。
计算用户之间相似度:可以使用余项公式,比如有A,B,C三个用户,要找到与D用户最相近的,只需将D用户正
反馈
的物品和A用户正反馈物品求交集N,在除以A,D两个用户物品集合(保证每个物品不重复)U,以N/U做评
判标准,找到最相近的用户。当然,这避免不了一些热门物品,比如卫生纸,这种人人都会买的,但<<数据挖
掘导论>>并不是人人都买,因此可以加大对冷门物品的权重,减少热门物品的权重。
计算物品之间的相似度:
计算物品之间的相似度,这里并不采用基于内容的相似性,而是去计算在喜欢物品i的用户中有多少是喜欢物品j的,这样计算的前提是用户的兴趣爱好一般是比较确定的,不容易变,那么当一个用户对两个物品都喜欢的时候,我们往往可以认为这两个物品可能属于同一分类。令N(i)表示购买物品i的用户数,则物品i和物品j的相似度可以用wij = |N(i)&N(j)|/N(i)来计算。
时间复杂度的改进方法:和UserCF类似,我们可以建立一张用户-物品的倒查表,这样每次去计算一个用户有过行为的那些物品间的相似度,能够保证计算的相似度都是有用的,而不用花大的计算量在那些0上面(肯定是个稀疏矩阵)
相似度的改进方法1:若根据上面的公式来计算相似度,你会发现,物品i跟流行物品j的相似度很高,因为流行读高,所以基本人人都会买,这样的话流行度高的物品就比较没有区分度,所以我们需要惩罚流行物品j的权重wij = |N(i)&N(j)|/sqrt(N(i)*N(j))
相似度的改进方法2:需要惩罚用户的活跃度。若用户活跃度比较低,只买了有限的几本书,那么这几本书很有可能在一个或者两个兴趣范围内,对计算物品相似度比较有用,但是如果说一书店卖家趁着打折把亚马逊90%的书都买了然后赚差价,那么该用户的行为对计算物品相似度就没什么作用,因为90%的书肯定会覆盖很多范围,故应该像改进方法一中惩罚用户的活跃度。
相似度的改进方法3:物品相似度的归一话。归一化不仅仅能提高推荐的准确度,还可以提高推荐的覆盖率和多样性。比如亚马逊上,用户的兴趣爱好肯定是分成几类的,很少说爱好集中在一类。假设有两类A和B,A类之间的相似度为0.5, B类之间的相似度为0.8,A和B之间的相似度为0.2, 当用户买了5本A类的书和5本B类的书后,我们要给用户来推荐书,如果按照之前的方法,最后按照相似度排序,那么推荐的应该都会是B类物品,就算B类中排名比较低,但照样比A类要高阿,所以应该根据类别进行相似度的归一话,这样一来A的相似度为1,B的相似度也为1,这样的话排序后的推荐A,B类商品都有,就大大提高了准确度,覆盖率和多样性。
三, 计算并推荐
在上面,我们求出了相邻用户和相邻物品,接下来就应该进行推荐了。当然从这一步开始,分为两方面,分别
是基于用户的协同过滤和基于物品的协同过滤。我会分别介绍它们的原理
(1)基于用户的协同过滤算法
在上面求相似邻居的时候,通常是求出TOP K邻居,然后根据邻居的相似度权重以及它们对物品的偏好,
预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表进行推荐。
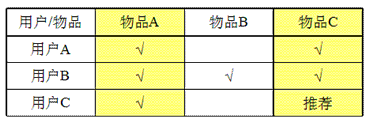
(2)基于物品的协同过滤算法
跟上述的基于用户的协同过滤算法类似,但它从物品本身,而不是用户角度。比如喜欢物品A的用户都喜
欢物品C,那么可以知道物品A与物品C的相似度很高,而用户C喜欢物品A,那么可以推断出用户C也可能
喜欢物品C。如下图
上面的相似度权重有时候需要加入惩罚因子,举个例子,在日常生活中,我们每个人购买卫生纸的的频率比
较高,但是不能说明这些用户的兴趣点相似,但是如果它们都买了照相机,那么就可以大致推出它们都是摄
影爱好者。所以像卫生纸这样的物品在计算时,相似度权重需要加上惩罚因子或者干脆直接去掉这类数据。
适用场景
对于一个在线网站,用户的数量往往超过物品的数量,同时物品数据相对稳定,因此计算物品的相似度不但
计算量小,同时不必频繁更新。但是这种情况只适用于电子商务类型的网站,像新闻类,博客等这类网站的
系统推荐,情况往往是相反的,物品数量是海量的,而且频繁更新。所以从算法复杂度角度来说,两种算法
各有优势。关于协同过滤的文章,可以参考这里:http://www.tuicool.com/articles/6vqyYfR
协同过滤的优势:
a 它不需要对物品或者用户进行严格的建模,而且不要求物品的描述是机器可理解的,所以这种方法也是领域无关的。
b 这种方法计算出来的推荐是开放的,可以共用他人的经验,很好的支持用户发现潜在的兴趣偏好
不足:
a 方法的核心是基于历史数据,所以对新物品和新用户都有“冷启动”的问题。
b 推荐的效果依赖于用户历史偏好数据的多少和准确性。
c 在大部分的实现中,用户历史偏好是用稀疏矩阵进行存储的,而稀疏矩阵上的计算有些明显的问题,包括可能少部分人的错误偏好会对推荐的准确度有很大的影响等等。
d 对于一些特殊品味的用户不能给予很好的推荐。
e 由于以历史数据为基础,抓取和建模用户的偏好后,很难修改或者根据用户的使用演变,从而导致这个方法不够灵活。
****************************基于内容的推荐******************************
与上面的方法相类似,只不过这次的中心转到了物品本身。使用物品本身的相似度而不是用户的相似度。
系统首先对物品(图中举电影的例子)的属性进行建模,图中用类型作为属性。在实际应用中,只根据类型显然过于粗糙,还需要考虑演员,导演等更多信息。通过相似度计算,发现电影A和C相似度较高,因为他们都属于爱情类。系统还会发现用户A喜欢电影A,由此得出结论,用户A很可能对电影C也感兴趣。于是将电影C推荐给A。
优势:
对用户兴趣可以很好的建模,并通过对物品属性维度的增加,获得更好的推荐精度
不足:
a 物品的属性有限,很难有效的得到更多数据
b 物品相似度的衡量标准只考虑到了物品本身,有一定的片面性
c 需要用户的物品的历史数据,有冷启动的问题
***************************基于人口统计学的推荐*************************
这是最为简单的一种推荐算法,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户。
系统首先会根据用户的属性建模,比如用户的年龄,性别,兴趣等信息。根据这些特征计算用户间的相似度。比如系统通过计算发现用户A和C比较相似。就会把A喜欢的物品推荐给C。
优势:
a 不需要历史数据,没有冷启动问题
b 不依赖于物品的属性,因此其他领域的问题都可无缝接入。
不足:
算法比较粗糙,效果很难令人满意,只适合简单的推荐















 3558
3558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









