







所谓Image Caption,是指从图片中自动生成一段描述性文字,类似于“看图说话”。
本章主要介绍2个内容:
1)Image Caption的技术原理;
2)Image Caption在Tensorflow中的实现;
一、Image Caption综述
本节总结了3篇论文中Image Caption的核心思想。
(一)Show and Tell:A Neural Image Caption Generator。
该篇论文中,Image Caption采用了Encoder - Decoder 模型的思想,区别在于:其Encoder采用CNN(Inception V3)来提取图像特征,Decoder采用LSTM来输出文字,其具体结构如下:
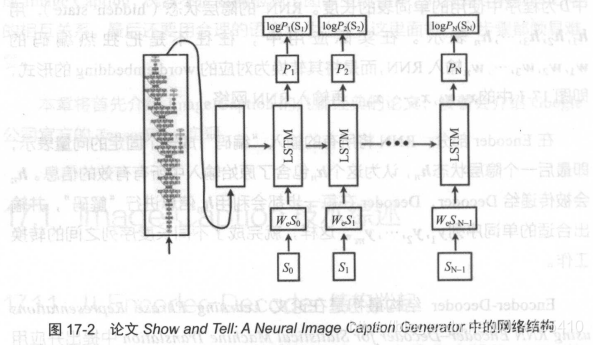
该论文中,只是简单的利用Encoder-Decoder模型的结构,设计了一个Image Caption模型,并没有其他额外的改进。
(二)Show,Attend and Tell:Neural Image Caption Generation with vision attention。
与第一篇文章相比,该论文中引入了“注意力机制”,其核心思想如下:
在第一篇论文中,利用CNN提取了Image固定长度的向量特征;而在本篇论文中,利用CNN提取了image不同部位的向量特征,假设image=(14,14,256),则其位置个数=1414,我们可以利用CNN来提取这1414个位置的向量特征,记为:{a1,a2,…,aL},L=14*14,为每个位置的向量特征均赋予一个权重ati(代表:Decoder中第t阶段的context与Encoder中第i个位置的向量特征之间的关联程度),假设zt为Decoder的context,则有下列关系式: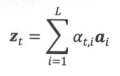 ,这与“机器翻译中的注意力机制”类似。
,这与“机器翻译中的注意力机制”类似。
在这里,at,i只与Decoder中的ht-1和Encoder中的第i个向量特征有关,其计算公式如下: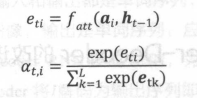
可以利用权重ati,了解Decoder生成word的时候,模型关注了图片的哪一部分,以下为生成某一单词时,模型的关注点示意图:

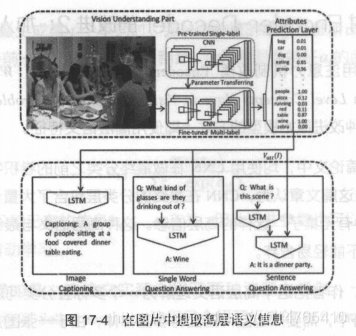
(三)What value do explicit high level concepts have in vision to language problems?
前2篇论文均是将CNN中分类的layer省去,而直接用之前的卷积层作为“向量特征”,本篇论文认为:CNN最后的分类layer含有大量的语义信息(即:image中含有那些物体的信息),不能轻易舍弃。
实际上,该篇论文把“高层语义”理解为一个“多分类问题”,因此,保留CNN中最后的softmax层,假设一个image中有c个物体,则CNN应该有c个softmax层。这里,假设第i个image的标签yi = {yi1,yi2,…yic},yic={0:没有c物体,1:有c物体},pi={pi1,pi2,…,pic}表示image中是否有物体c的概率,则该CNN的损失函数可以表示为: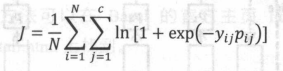 ,通过训练该CNN,将CNN softmax层的输出作为“高层语义表达向量Vatt(l)”,输入Decoder输出各个阶段的word,其结构如下图所示:
,通过训练该CNN,将CNN softmax层的输出作为“高层语义表达向量Vatt(l)”,输入Decoder输出各个阶段的word,其结构如下图所示:
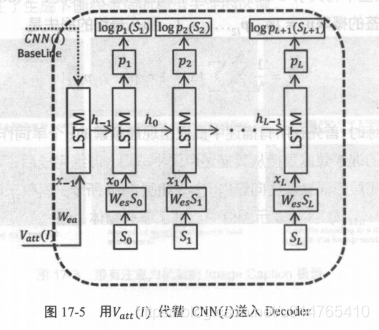
实验证明,使用Vatt(l)代替CNN(I),可以大幅度提高Image Caption模型的效果,下图所示为本片论文模型结构:
其中,左上方的虚线代表前2篇论文使用的CNN(I)特征向量,左下方的实线则为本篇论文Encoder之后输出的context:Vatt(I)。
二、在Tensorflow中实现Image Caption
源码有时间在详读,解析!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











