









先上福利,caiyong同学收集了3000fps和SDM的相关资源,点这里
3000fps和之前的[ESR][1]使用了同样的cascade的方式,把整个alignment过程分几个stage来做,每一个stage的alignment都依赖上一个stage得到的alignment shape.
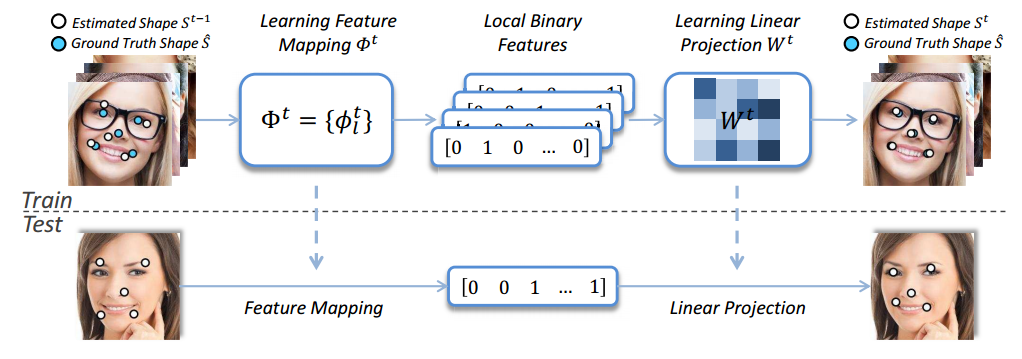
每个stage所做的工作一样,可以分为三个过程
- 提取特征(shape index feature)
- LBF编码(learning local binary feature)
- 获取shape 增量(learning global linear regression)
shape index feature
shape index feature 也就是特征和现有的一系列标定点是相关的,3000fps的做法是在landmark周围随机出两个偏移量,形成两个点,用这两个点的像素差作为特征。

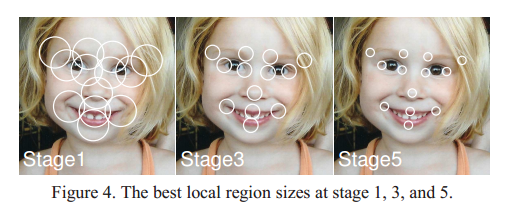
红色的点表示landmark,蓝色的框框表示随机取样特征的半径,两个绿色的点表示随机出来的特征点位置,用两个绿色的点的差值作为特征。
刚开始的时候,shape和ground truth差距太大,因此需要取样特征的半径大一些,最后的shape和ground truth已经很接近了,半径要小一些。
learning local binary feature
3000fps使用随机森林来做回归,每个Stage 有K棵树,每棵树的深度为D,内部节点分裂准则是最大方差减小。
内部结点的分裂过程如下:
input: 特征矩阵X,大小m*n(由于是像素差值特征,因此X中所有元素取值范围为[-255, 255]);regression target
ΔS
output: 最佳分裂属性(id,val)
- 随机p组属性(id, val)
- 每个样本id位置的属性值都和val比较,小于val的样本划到左子结点,大于val的样本划归右子结点。然后计算,按该属性划分的方差减小(在这里用到了target
ΔS
)
- 从P组属性中选出方差减小最多的属性(id, val)作为分裂属性
依照这样的方法建立一棵深度为D的树,然后再重复K次,建立起完成的森林
3000fps并没有使用随机森林的输出作为shape的增量,而是进行了编码:
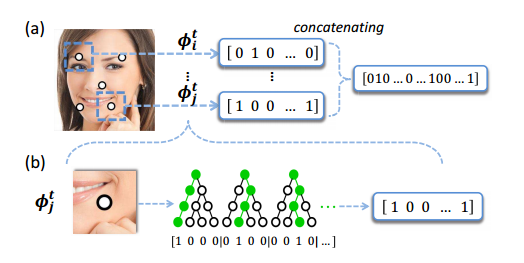
如果每棵树有leafNum个叶子结点,所有叶子结点形成一个leafNum维的向量;
训练样本通过一棵树,最终总会落在其中一个叶子结点,样本落在那个叶子结点就把相应的位置置1,其它位置置0;待训练样本通过所有的k棵树后,把K个leafNum维的向量连接起来,形成最终的K*leafNum维的特征向量,可以看到,这样的特征向量是非常稀疏的,只有很少的位置是1.
learning global linear regression
上边求出的lbf特征为所有的landmark公用,通过求解下边的式子,得到weight W:
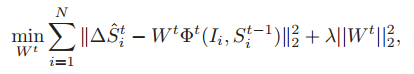
以求解其中一个landmark的
Δx
为例:
input: lbf特征,所有样本的
Δx
组成的regression target vector
output: w
借助LibLinear求解系数向量w;
测试的时候,先对一幅图像提取shape index feature, 然后使用随机森林进行编码,最后使用w估计shape 增量。
求解
Δy
的过程一样,只是regression target vector换了而已
按照上边的方法对所有landmark进行global regression
最后得到权重矩阵W。
[1]: Face Alignment by Explicit Shape Regression;
[2]: Face Alignment at 3000 FPS via Regressing Local Binary Features















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









