







数据包嗅探工具如tcpdump是普遍用于实时数据包转储,需要设定一些过滤规则,只捕获HTTP流量,即便如此,它的输出内容很难理解,需要一定的协议基础知识。实时的Web服务器日志分析工具如ngxtop提供了可读的实时网络流量的痕迹,但仅适用于具有完全访问过的Web服务器的日志。
有没有一款功能强大且又只针对HTTP流量的工具呢?那就是httpry,HTTP数据包嗅探工具。捕获HTTP数据包,并显示可读格式的HTTP协议层面的内容。
安装httpry
在基于debian系统如Ubuntu,httpry没有包含在基础仓库中。
$ sudo apt-get install gcc make git libpcap0.8-dev
$ git clone https://github.com/jbittel/httpry.git
$ cd httpry
$ make
$ sudo make installFedora、centos、RHEL系统需要安装EPEL源
$ sudo yum install httpry也可以源码编译
$ sudo yum install gcc make git libpcap-devel
$ git clone https://github.com/jbittel/httpry.git
$ cd httpry
$ make
$ sudo make installhttpry基本用法
$ sudo httpry -i <network-interface>
httpry监听在指定的网卡下,实时捕获并显示HTTP请求与响应的包
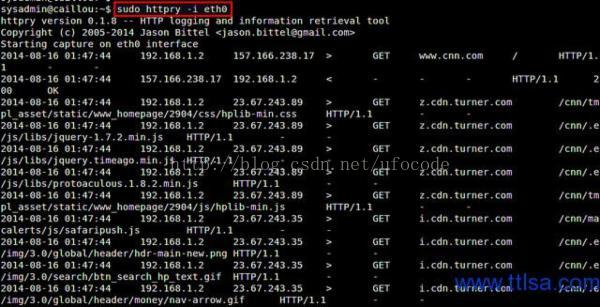
在大多数情况下,输出滚动非常快的,需要保存捕获的HTTP数据包进行离线分析。可以使用-b或-o选项。“-b”选项将原始的HTTP数据包保存到一个二进制文件,然后可以用httpry进行重播。 “-o”选项保存可读的输出到文本文件。
保存到二进制文件中:
$ sudo httpry -i eth0 -b output.dump重放:
$ httpry -r output.dump保存到文本文件:
$ sudo httpry -i eth0 -o output.txthttpry高级用法
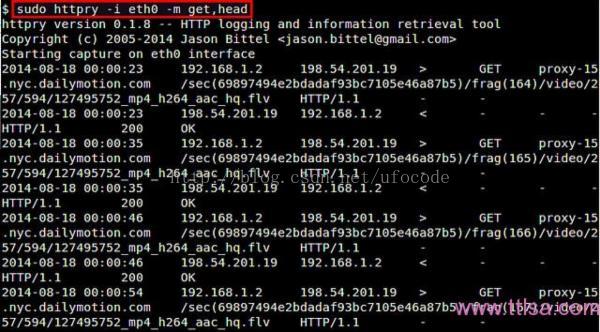
如果你要捕获特定的HTTP方法,如GET、POST、PUT、HEAD、CONNECT等等,可以使用‘-m’选项:
$ sudo httpry -i eth0 -m get,head
如果你下载httpry源码,在源码目录下,有一个perl脚本来帮助我们分析httpry输出。该脚本在httpry/scripts/plugins目录下。 如果你想编写一个httpry输出的定制解析器,这些脚本是个很好的例子。功能有:
- hostname : 显示一些列唯一主机名
- find_proxies:检测web代理
- search_terms:查找并计算在搜索服务中输入搜索词
- content_analysis:查找包含特定关键字的URI
- xml_output:以xml格式输出
- log_summary:生成日志摘要
- db_dump:将日志转存到mysql数据库中
在使用这些脚本前,先使用’-o’选项运行一段时间。一旦得到输出,运行这些脚本分析:
$ cd httpry/scripts
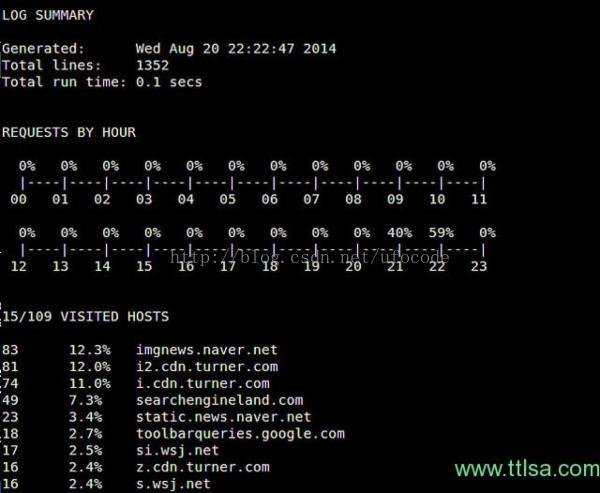
$ perl parse_log.pl -d ./plugins <httpry-output-file>parse_log.pl执行完后,会在httpry/scripts目录下生成一些分析结果文件(*.txt/xml)。例如,log_summary.txt看起来像下面这样:















 5249
5249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









