







引用类型是在垃圾回收托管堆上分配的对象,默认情况下,当使用相等性测试的时候(==,!=)如果引用类型指向内存中的相同对象则返回true。
字符串是不可变的!所谓的改变只是返回了一个副本!
string s1 = "old string";
s1 = "new string";通过查看代码生成的CIL可以得出:多次调用了ldstr(加载字符串),oldstring的内存会被回收。
从中得出:一旦滥用string可能导致低效和代码膨胀!所以为了处理大量使用文本数据的情况,应该使用新的string结构。
StringBuilder
在System.Text这个相对较小的命名空间中,提供了StringBuilder类。StringBuilder可以直接修改字符串内部的内容,而不是获取一个修改后的副本,因此更高效。
默认情况下stringbuilder只能保存16个字符以下的字符串们,但是可以通过构造函数改变这个初始值(其实也可以自动扩展):
StringBuilder sb = new StringBuilder("this is a very lager string more than 16 character",256);宽化:
隐式向上转换,例如short->int,char->int;并且不会丢失数据
窄化:
显示强制转换,如果不显示强制转换会报错!和宽化相对,但是这个要保证的确能转换,而且不能保证数据精度。
var:
隐式类型定义使用的var严格意义上来说并不是C#的关键字,所以var可以作为变量名或者参数名等,而且编译器也不会报错,但是当用于数据类型的时候,编译器会根据语境将其视为关键字。
var不仅能定义内置类型,而且还能定义自定义类型。
好处那么多,所以限制也是一大堆的:
只能用于方法或属性范围内的本地变量,用var定义返回值、参数或字段(就是类的变量)数据都是不合法的。
必须初始化!而且不能为null
别人阅读你的代码产生了困难
针对不能定义返回值,看下面的两个实例:
public var add(var x,var y)
{
return x+y;
}//不能用于定义返回值和参数!
public int add(int x,int y)
{
var z = x + y;
return z;
}//没问题通过以上的限制可以知道,其实就是var能马上获知自己是什么类型,或许在内置类型的时候不明显,但是在我不关心要获得什么类型的时候作用非常大,比如说LINQ:
static void Ling QueryOverInts()
{
int[] numbers = {10,20,30};
//LINQ查询
var subset = from i in numbers where i < 10 select i;
foreach(var i in subset)
{
Console.Write(i);
}
}上面的程序我们并不关心获得了什么类型,只是单纯的想要将获得的值赋给一个隐式的本地变量。
C#提供的switch可以判断string、枚举了,我们知道C/C++中是只能判断整形数值的。
静态方法可以直接被调用而不用创建类的实例
我们看到:
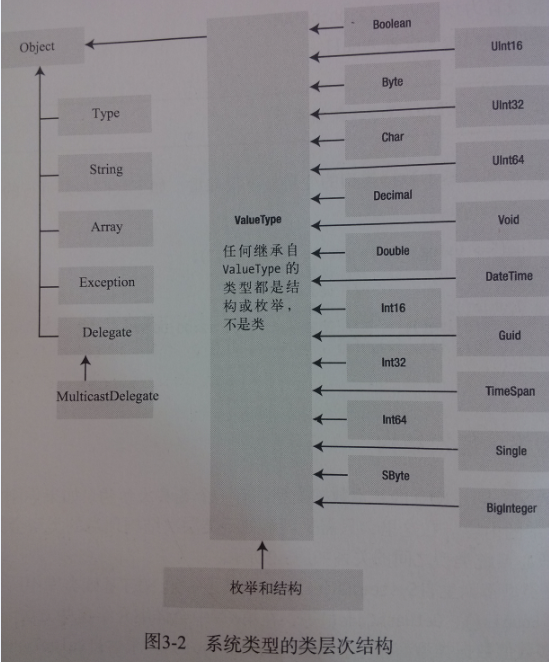
所有的数据类型都是继承自object,而一些是继承自ValueType,继承自ValueType的都会自动的在栈上分配(其他的则是在垃圾回收堆上分配),有一个可预期的生命周期,非常高效,可以调用object中预定义的所有类型都具有的方法(GetHashCode、Equals、ToString……)。
CS允许给方法的参数以下几种修饰:
1.空
按值传递,获得的是一个副本
2.out
输出传递,调用者必须也要使用out,必须给这个值赋值,调用者可以不用给这个值赋值。这是引用。
3.ref
引用传递,调用者必须也要使用ref,必须先初始化,这是引用。
2、3的例子:
public static void ChangeOne(string a,out string b)
{
a = "really";
b = "world!";
}
public static void SwapString(ref string a, ref string b)
{
string temp = a;
a = b;
b = temp;
}
static void Main(string[] args)
{
string a = "hello";
string b = "world";
Console.WriteLine(a+b);
ChangeOne(a,out b);
Console.WriteLine(a+b);
SwapString(ref a,ref b);
Console.WriteLine(a+b);
}输出:
helloworld
helloworld!
world!hello4.params
不定参数,允许任意参数,但是参数的值必须在编译的时候就能确定而不是运行时。例如我想要获得一组数据的平均值,当然可以传递一个数组过去,但是用params后可以直接传递数值。
public static int Ave(params int[] data)
{
int sum = 0;
for (int i = 0; i < data.Length; ++i)
sum += data[i];
return sum / data.Length;
}
static void Main(string[] args)
{
int[] numbers = { 1,2,3,4,5};
Console.WriteLine(Ave(1,2,3,4,5));
Console.WriteLine(Ave(numbers));
}多维数组:
1.矩形数组
每行都有相同列数
int[,] data = new int[2,5];2.交错数组
int[][] data = new int[2][];
for(int i=0;i <2;++ i)
{
data[i] = new int[i+3];
}一般二维至多维都是不推荐使用的,但是一维的效率非常高推荐使用。尽管定义的是int或者继承自ValueType的类型,但是这个数组仍然是分配在托管堆上的。
枚举类型可以是byte、short、int或者long其中的一种:
enum enumType : byte
{
hello, world
}!C# 结构体不能有默认构造函数! ,不允许结构体字段初始化.
结构体的赋值运算符是拷贝了一个副本,因为struct是值类型,而class是引用类型,所以类
的赋值运算符是指向而不是赋值。
出于上述,现有下面的问题:
如果一个值类型中包含了一个引用类型调用赋值运算符会怎么样?
class A
{
...
}
struct B
{
private A x1,x2;
private int b;
...
}
static void main(string[] args)
{
B b1 = new B(...),b2;
b2 = b1;
}上述就是一个struct(值类型)中包含看一个class(引用类型),当b2赋值给b1的时候回发生什么?
答:默认情况下,当值类型包含其他引用类型时,赋值将产生一个引用的副本。这样就有两个独立的结构,每一个都包含指向内存中同一个对象的引用(浅拷贝)。当想执行一个“深拷贝”,即将内部引用的状态完全复制到一个新对象中时,需要实现ICloneable接口。
按值传递引用类型:
这时候copy的是指向调用者对象的引用,所以和C++中的常量指针一样,可以改值,但是不能更改指针的方向:
static void ChangePerson(Person P)
{
P.Age = 100;
P = new Person("hello",99);
}最终传递过来的P的年纪会改变成100,但是后面的重新赋值就不行。可能就是想引用吧,对这个别名的数据操作等价于对源数据的操作,但是不能重新起别名,也就是常量指针的意思。
按引用传递引用类型:
全部可变
综合上述:
值传递是绑定了调用者对象,除了不能改变对象,值可以变(限定于传递引用类型!值类型是一个拷贝)
引用传递完全可以改变
这里看一下值类型和引用类型的区别:

关于可空类型:
对于关系型数据库打交道来说,可能会遇到没有输入的情况,而不能单纯的表示为true/false。所以可以允许有null。但是可空类型只能应用于值类型,而不能是引用类型。
int? a = 10;
int?[] b = new int?[10];
Nullable<int> aa = 10;
Nullable<int>[] bb = new int?[10];代码中上面的?等价于下面的实现接口。
下面介绍一种简便运算符??:
??会判断为null马上赋值
int? a = null;
int b = a ?? 100; 这样b就会输出100,否则是a;
编译器会保证类的字段先全部正确初始化, 并且和声明顺序无关! C/C++类中的变量初始化和声明顺序有关,因为C/C++在编译的时候按照声明顺序确定了初始化列表,或者说在内存的位置。然后按照这个顺序初始化,所以即使在一个变量后声明的变量先初始化了,然后在用这个变量去初始化先声明的变量是没有用的。
对于C#和Java,其共同点都是先静态后普通。
区别在于:
C#是子类变量->父类变量->父类构造函数->子类构造函数(先变量后构造)
Java是父类变量->父类构造函数->子类变量->子类构造函数(先父后子)
和C/C++一样,一旦自己定义构造函数,必须显示自己写一个默认构造函数。
this:
1.this可以在参数相同时区分类和参数变量
看以下代码:
class Car{
private string name;
private double cost;
public void ChangeName(string name){
name = name;
}
}
编译器会警告:正在用变量本身设置该变量。
原因是参数变量的优先级大于类本身的,所以左边的name并不是调用者对象的name。
2.this可以实现串联构造函数
所谓串联构造函数是在有很多的构造函数时,将主要的构造工作交给参数最多的构造函数,避免冗[rǒng]余的代码。
原:
class Car
{
private string name;
private double speed;
private bool isSafe;
public Car(){}
//自己定义了构造函数必须要显示给一个默认构造函数
public Car(string name,double speed)
{
if (speed > 10) isSafe = false;
isSafe = true;
}//参数的speed而不是调用者的
public Car(double speed)
{
if (speed > 10) isSafe = false;
isSafe = true;
}
...
}串联构造:
class Car
{
private string name;
private double speed;
private bool isSafe;
public Car(){}
public Car(string name,double speed)
{
if (speed > 10) isSafe = false;
isSafe = true;
}
...
}这里还有一种解决方案:
class Car
{
private string name;
private double speed;
private bool isSafe;
public Car(){}
public Car(string name,double speed)
{
SetSafe(speed);
}
public Car(double speed)
{
SetSafe(speed);
}
private void SetSafe(double speed)
{
if (speed > 10) isSafe = false;
isSafe = true;
}
}可选参数和命名参数:
命名参数增加了维护复杂度,非必要不要使用
命名参数一般是在使用了可选参数的情况下使用
class Car
{
private string name;
private string nickname;
private double speed;
private bool isSafe;
public Car(){}
public Car(string name,double speed = 10,string nick = "hello")
{
if (speed > 10) isSafe = false;
else isSafe = true;
this.name = name;
nickname = nick;
}
}
//在另外一个类中
public static void Main()
{
Car();
Car(100);
Car(nick:"world");
}














 262
262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









