







序列化:结构化对象<=>字节流
1.自定义数据类型,实现Writable接口或者WritebaleComparable接口。
如果作为value,实现Writable就可以;如果作为key的话,必须是可排序的,是可排序的必然就是可比较的,需要实现WritebaleComparable。
2.Avro(跨语言)
构建Maven项目添加依赖导包比较方便。通过Scheme进行序列化和反序列化。
第一种方式代码举例:
一个mapreduce程序
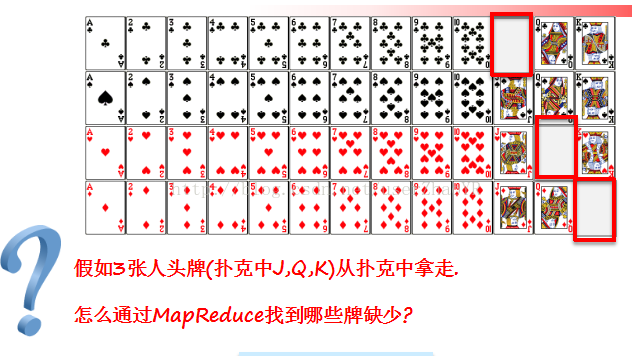
创建一个纸牌的类,将其对象传入到mapreduce中的value位置
package com.hadoop.serialization;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class CardBean implements Writable{
private int number;
private int huaSe;
public int getNumber() {
return number;
}
public void setNumber(int number) {
this.number = number;
}
public int getHuaSe() {
return huaSe;
}
public void setHuaSe(int huaSe) {
this.huaSe = huaSe;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(huaSe);
out.writeInt(number);
}
@Override
public void readFields(DataInput in) throws IOException {
//读的时候顺序要一致。先写什么就先读什么。使用和属性类型一致的方法
huaSe = in.readInt();
number = in.readInt();
}
}map:将从输入文件中的获取的信息,封装成CardBean对象,作为输出<key,value>中的value。
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class PokerMapper extends Mapper<LongWritable, Text, Text, CardBean>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] strs = line.split("-");
if (strs.length==2) {
int number = Integer.valueOf(strs[1]);
CardBean cardBean = new CardBean();
cardBean.setNumber(number);
cardBean.setHuaSe(Integer.valueOf(strs[0]));
if (number>10) {
context.write(new Text(strs[0]), cardBean);
}
}
}
}
reduce:将封装好的CardBean对象作为输入,计数输出。
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class PokerReduce extends Reducer<Text, CardBean, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<CardBean> values, Reducer<Text, CardBean, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
Iterator<CardBean> iterator = values.iterator();
int count=0;
while(iterator.hasNext()){
iterator.next();
count++;
}
if (count<3) {
context.write(key, new LongWritable(count));
}
}
}
第二种方式:Avro我创建的是maven项目
1、下载jar包,配置pom.xml
pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>2</groupId>
<artifactId>avro</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>avro</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- <dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>2.4.3</version>
</dependency> -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-mapred</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.1.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.7.7</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
</plugins>
<pluginManagement>
<plugins>
<!--This plugin's configuration is used to store Eclipse m2e settings only. It has no influence on the Maven build itself.-->
<plugin>
<groupId>org.eclipse.m2e</groupId>
<artifactId>lifecycle-mapping</artifactId>
<version>1.0.0</version>
<configuration>
<lifecycleMappingMetadata>
<pluginExecutions>
<pluginExecution>
<pluginExecutionFilter>
<groupId>org.apache.avro</groupId>
<artifactId>
avro-maven-plugin
</artifactId>
<versionRange>
[1.7.7,)
</versionRange>
<goals>
<goal>schema</goal>
</goals>
</pluginExecutionFilter>
<action>
<ignore></ignore>
</action>
</pluginExecution>
</pluginExecutions>
</lifecycleMappingMetadata>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
2、定义一个schema
文件路径以及文件名:/avro/src/main/avro/User.avro
{
"namespace": "example.avro",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
编译schema 在cmd中执行命令
java -jar /path/to/avro-tools-1.7.7.jar compile schema <schema file> <destination>


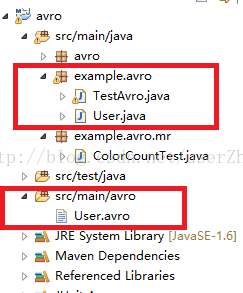
编译成功,E盘出现User.java文件,如上图。将User.java粘贴到项目中,项目结构如下图(本文的代码写在红框的文件中):
做到这步,接下来就会有两种写法,一种是有代码生成,一种是无代码生成。不同点见代码。下面分别介绍一下:
1)有代码生成
public static void main(String[] args) {
User user = new User();
user.setName("tom");
user.setFavoriteColor("red");
user.setFavoriteNumber(6);
User user2 = new User("jerry", 8, "");
User user3 = User.newBuilder().setName("lisi")
.setFavoriteNumber(5).setFavoriteColor("black").build();
//序列化写文件
try {
DatumWriter<User> userDatumWriter = new SpecificDatumWriter<User>(User.class);
DataFileWriter<User> dataFileWriter = new DataFileWriter<User>(userDatumWriter);
dataFileWriter.create(user.getSchema(), new File("user.avro"));
dataFileWriter.append(user);
dataFileWriter.append(user2);
dataFileWriter.append(user3);
dataFileWriter.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}//反序列化读
@Test
public void ReadAvro(){
// Deserialize Users from disk
try {
DatumReader<User> userDatumReader = new SpecificDatumReader<User>(User.class);
DataFileReader<User> dataFileReader;
dataFileReader = new DataFileReader<User>(new File("user.avro"), userDatumReader);
User user = null;
while (dataFileReader.hasNext()) {
// Reuse user object by passing it to next(). This saves us from
// allocating and garbage collecting many objects for files with
// many items.
user = dataFileReader.next(user);
System.out.println(user);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}2)无代码生成
@Test
public void WriteWithoutCode(){
try {
//创建schema
Schema schema = new Schema.Parser().parse(new File("F://正在学习课程//软件工程课程设计//课设软件//avro//src//main//avro//User.avro"));
//创建对象
GenericRecord user1 = new GenericData.Record(schema);
user1.put("name", "Alyssa");
user1.put("favorite_number", 256);
// Leave favorite color null
GenericRecord user2 = new GenericData.Record(schema);
user2.put("name", "Ben");
user2.put("favorite_number", 7);
user2.put("favorite_color", "red");
//序列化 Serialize user1 and user2 to disk
File file = new File("F://正在学习课程//软件工程课程设计//课设软件//avro//user2.avro");
DatumWriter<GenericRecord> datumWriter = new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter = new
DataFileWriter<GenericRecord>(datumWriter);
dataFileWriter.create(schema, file);
dataFileWriter.append(user1);
dataFileWriter.append(user2);
dataFileWriter.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//反序列化
@Test
public void ReadWithoutCode(){
try {
// Deserialize users from disk
Schema schema = new Schema.Parser().parse(new File("F://正在学习课程//软件工程课程设计//课设软件//avro//src//main//avro//User.avro"));
DatumReader<GenericRecord> datumReader = new GenericDatumReader<GenericRecord>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("user2.avro"),
datumReader);
GenericRecord user = null;
while (dataFileReader.hasNext()) {
// Reuse user object by passing it to next(). This saves us from
// allocating and garbage collecting many objects for files with
// many items.
user = dataFileReader.next(user);
System.out.println(user);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}














 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









