






用户行为介绍
基于用户行为的推荐,在学术界名为协同过滤算法。
协同过滤就是指用户可以齐心协力,通过不断地和网站互动,使 自己的推荐列表能够不断过滤掉自己不感兴趣的物品,从而越来越满足自己的需求。
用户行为在个性化推荐系统中一般分两种——显性反馈行为(explicit feedback)和隐性反馈 行为(implicit feedback)。
显性反馈行为包括用户明确表示对物品喜好的行为:主要方式就是评分和喜欢/不喜欢;
隐性反馈行为指的是那些不能明确反应用户喜好的行为:最具代表性的隐性反馈行为就是页面浏览行为;

反馈除了分为显性和隐性外,还能分为正反馈、负反馈,举例子如下: 
互联网中的用户行为有很多种,比如浏览网页、购买商品、评论、评分等。要用一个统一的 方式表示所有这些行为是比较困难的,下面是一个表示的可能: 
用户行为分析
先定义两个变量:
用户活跃度:用户产生过行为的物品总数
物品流行度:对物品产生过行为的用户总数
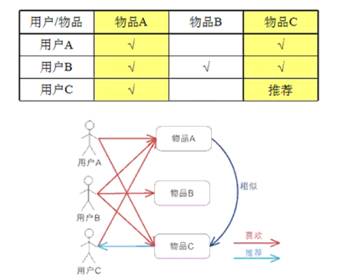
而用户活跃度和物品流行度的人数都符合Power Law,也称为长尾分布: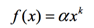 。
。
用户活跃度和物品流行度的关系是:用户越活跃,越倾向于浏览冷门的物品。
仅仅基于用户行为数据设计的推荐算法一般称为协同过滤算法。 学术界对协同过滤算法 进行了深入研究,提出了很多方法,比如基于邻域的方法( neighborhood-based )、隐语义模型 ( latent factor model)、基于图的随机游走算法(random walk on graph)等。
基于邻域的算法
基于领域的方法中,主要包括两大类:
基于用户的协同过滤算法,这种算法给用户推荐和他兴趣相似的其他用户喜欢的物品。
基于物品的协同过滤算法,这种算法给用户推荐和他之前喜欢的物品相似的物品。
基于用户的协同过滤算法
基于用户的协同过滤算法主要包括两个步骤:
(1) 找到和目标用户兴趣相似的用户集合。
(2) 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
在第一步上计算相似度上,具体算法大概有几种:欧几里得距离,皮尔逊相关系数,Cosine 相似度,Tanimoto 系数。不同相似度衡量方法对于结果会有不同的影响。
基于物品的协同过滤算法
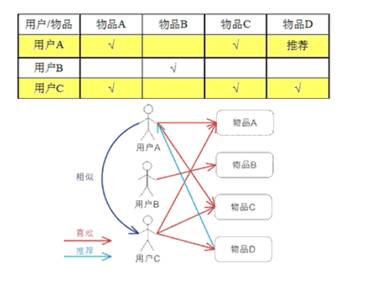
基于item的协同过滤,通过用户对不同item的评分来评测 item 之间的相似性,基于item 之间的相似性做出推荐,简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。
UserCF和ItemCF的综合比较

对于电子商务,用户数量一般大大超过商品数量,此时Item CF的计算复杂度较低。
在非社交网络的网站中,内容内在的联系是很重要的推荐原则,它比基于相似用户的推荐原则更加有效。比如在购书网站上,当你看一本书的时候,推荐引擎 会给你推荐相关的书籍,这个推荐的重要性进进超过了网站首页对该用户的综合推荐。可以看到,在这种情况下,Item CF 的推荐成为了引导用户浏觅的重要手段。基于物品的协同 过滤算法,是目前电子商务采用最广泛的推荐算法。
在社交网络站点中,User CF 是一个更丌错的选择,User CF 加上社会网络信息,可 以增加用户对推荐解释的信服程度。
隐语义模型(LFM)
隐语义模型最早在文本挖掘领域被提出,用于找到文本的隐含语义。相关的 名词有LSI、pLSA、LDA和Topic Model。
LFM源于对SVD(奇异值分解)方法的改进,传统SVD是线性代数典型问题,但由于计算量太大,实际上只是适用于规模很小的系统,Simon Funk改迚SVD(Funk-SVD),后来被称为Latent Factor Model。
LFM假设了一个隐含的变量,用户兴趣,看下面的矩阵分解: 
R 矩阵是 user-item 矩阵,矩阵值 Rij 表示的是 user i 对 item j 的兴趣度,对于其中缺失的值,我们可以先给一个平均值。 LFM 算法从数据集中抽取出若隐变量,作为 user 和 item 之间连接的桥梁,将 R 矩阵表示为 P 矩阵和 Q 矩阵相乘。其中 P 矩阵是 user-topic 矩阵,矩阵值 Pij 表示的是 user i 对 topic j 的兴趣度;Q 矩阵式 topic-item 矩阵,矩阵值 Qij 表示的是 item j 在 topic i 中的权重。
上面这个过程就是一个svd的过程,但是当矩阵太大的时候,svd分解会太慢,于是就有了下面的方法: 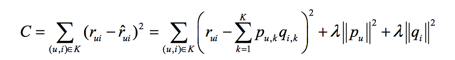
将矩阵分解转换为一个机器学习问题,我们通过梯度下降的方法去预估Rij,先求导: 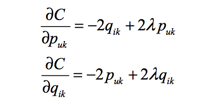
后更新: 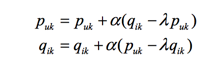
上面的算法的超参数有:
隐特征的个数F;
学习速率alpha;
正则化参数lambda;
还有一个没讲到的是,对于Rij,我们现在只有正样本,即user-item中有的我们算Rij=1,我们要去获取负样本,Rij=0的值,负样在选择上秉持的原则是:
对每个用户,要保证正负样本的平衡(数目相似)。
对每个用户采样负样本时,要选取那些很热门,而用户却没有行为的物品。
此处选择采用热门商品的原因是:对于冷门的物 品,用户可能是压根没在网站中发现这个物品,所以谈不上是否感兴趣。
总结
本文首先介绍了用户行为的基本概念,介绍了显性反馈行为和隐性反馈行为,以及正反馈和负反馈,接着介绍了两大类推荐算法:基于领域的算法和隐语义模型,下面一篇会通过Surprise库来用今天介绍的算法来解决一些实际问题。
参考
使用 LFM(Latent factor model)隐语义模型进行 Top-N 推荐(http://blog.csdn.net/harryhuang1990/article/details/9924377)
推荐系统实践
出处:https://www.zybuluo.com/zhuanxu/note/985025
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
-END-
架构文摘
ID:ArchDigest
互联网应用架构丨架构技术丨大型网站丨大数据丨机器学习

更多精彩文章,请点击下方:阅读原文














 2936
2936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









