







LCSTS 数据集的构建给中文文本摘要的研究奠定了基础,LCSTS数据集中包含了200万真实的中文短文本数据和每个文本作者给出的摘要。同时作者团队也手动标注了10666份文本的摘要。
一、数据来源
首先,数据来源主要是微博爬虫,数据收集的策略很类似pageRank思想。先找50个流行的官方组织用户作为种子然后从种子用户中抓取他们关注的用户,并且将不是大V,且粉丝少于100万的用户过滤掉。然后抓取候选用户的微博内容。最后通过过滤,清洗,提取等工作得到最后的数据集。
二、实验
实验中,本文使用seq2seq模型进行验证。
采用了两种方法来处理数据:
1、基于汉字的方法(character-based),将词汇表降维到了4000。
2、基于词的方法(word-based),本文用jieba做分词,词汇表维度为50000。
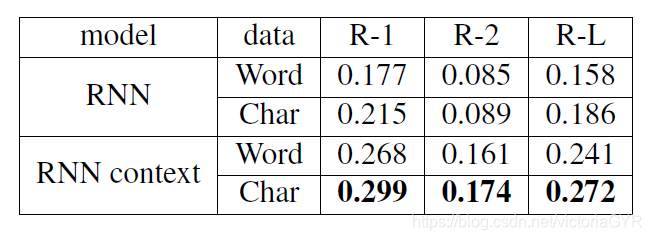
最后效果最好的是RNN+context+char。
三、评价标准
评价标准蛮有意思。评测方法采用ROUGE-1,ROUGE-2,ROUGE-L,由于标准的ROUGE包是用来评测英文的,所以这里将中文汉字转换成id。结果中基于汉字的RNN context模型有更好的效果。简单分析下原因,基于词的模型由于词汇表的限制,非常容易遇到unknown words,而基于字则不同,可以轻松解决unk的问题。














 818
818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









