







1 线程控制程序
1.1 问题描述
本实验要求使用互斥量、信号量、障碍、条件变量中的至少一种Pthread编程API来实现一个线程控制程序。
输出样例为:
I am the child thread 0.
I am the child thread 1.
I am the child thread 2.
I am the child thread 3.
All the child threads has printed.
Thread 0 is going to exit.
Thread 1 is going to exit.
Thread 2 is going to exit.
Thread 3 is going to exit.
实验环境:计算机apple MacBook pre2015、系统macOS High Sierra10.13.5、编辑器vscode、gcc编译。
1.2 设计与实现
在本次实验中设计线程数为4,采用信号量通信的方式来实现主线程和子线程间通信。
使用到的pthread相关api函数如下:
int pthread_create( &thread1,NULL,(void*)&print_fun,(void*) message); //创建线程
int pthread_join(pthread_t *, void**value_ptr) //挂起线程直到结束
int sem_init(sem_t *sem, int pshared, unsigned value); //初始化信号量
int sem_wait(sem_t *sem); // 信号量值减1,若已为0则阻塞
int sem_post(sem_t *sem); // +1,若原来为0则可能唤醒阻塞线程
int sem_destroy(sem_t *sem); //释放信号量
//由于实验环境为macOS X,OS X不支持创建无名的信号量,只能使用sem_open创建有名的信号量。
sem_t* psemaphore = sem_open("/mysem",O_CREAT, S_IRUSR | S_IWUSR, 10);
sem_close(psemaphore);
sem_unlink("/mysem");
实现结果为:
I am the child thread 0.
I am the child thread 1.
I am the child thread 2.
I am the child thread 3.
All the child threads has printed.
Thread 0 is going to exit.
Thread 1 is going to exit.
Thread 2 is going to exit.
Thread 3 is going to exit.
结果与输出样例一致。
具体代码见3.1。
2 多个数组排序
2.1 问题描述
本实验要求对"多个数组排序"的任务不均衡案例进行复现,并探索最优的方案。可从任务分块的大小、线程数的多少、静态动态多线程结合等方面进行尝试,探索规律。
由于LARGE_INTEGER为头文件windows.h中的数据类型
typedef union _LARGE_INTEGER{
struct{
DWORD LowPart;
LONG HighPart;
};
LONGLONG QuadPart;
}LARGE_INTEGER;
因此在macOS X中无法使用该头文件,实验环境改变为windows10、编译器code blocker 、c++11。
2.2 设计与实现
本次实验使用并行实现多个数组排序,主要操作为将需要排序的数组构建成一个矩阵m,将矩阵划分为n个块交由n个线程执行排序操作,每个块大小均为m/n。
1)随机生成元素情况下的动态任务划分
首先构造一个1000010000的矩阵,线程数设计为4,矩阵元素随机生成,执行时不做动态任务划分,每个线程执行初始分配的任务,执行程序得到实验结果一:
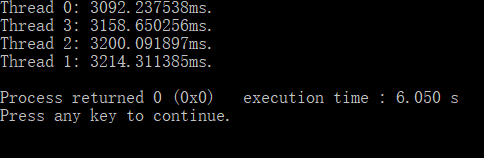
其次同样构造一个1000010000的矩阵,线程数设计为4,矩阵元素随机生成,执行时做动态任务划分,每个线程在空闲时会承担别的线程需要执行的任务,执行程序得到实验结果二:
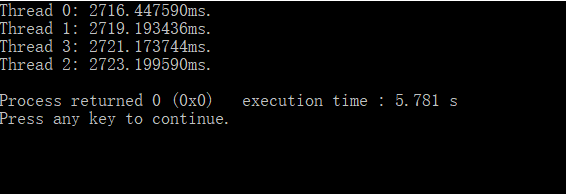
可以看出,在数据随机的情况下,将排序任务动态划分给空闲线程可以实现更均衡的负载,并且执行速度也更快。
2)随机生成元素情况下的线程数量
在实验结果一的基础上,将线程数修改为8,块大小变为10000*10000/8,得到实验结果三:
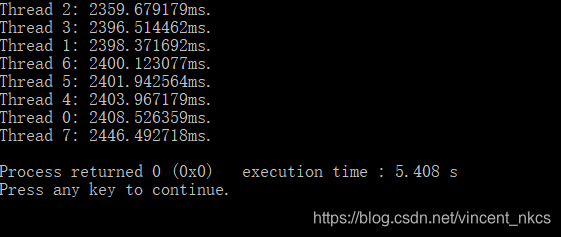
从该实验结果可以看出,在数据随机的情况下,线程数相对较多时执行速度更快。
3)特殊数据元素情况下的动态任务划分
矩阵大小不变,线程数为4,将矩阵分块后的数据故意构造成部分升序和降序,造成块划分负载不均的情况,来考察动态任务划分的作用:
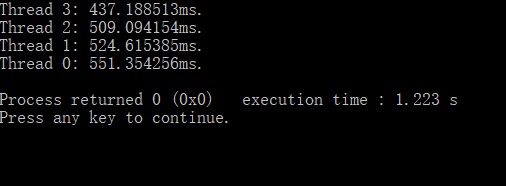
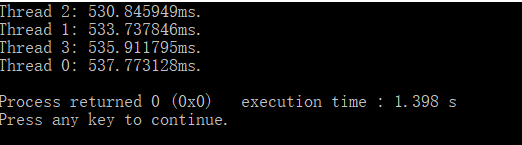
实验结果四为不做动态任务划分的情况,结果五为实现动态任务划分后的情况,发现执行速度不升反降,但是各线程间负载更加均衡,考虑到具体原因应该是动态任务划分时为了保持线程负载间的均衡,造成了更大的任务分配开销,因而执行速度变慢。
4)特殊数据元素情况下的线程数量
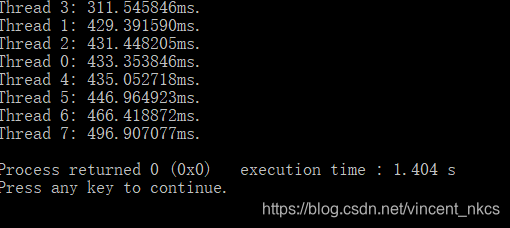
实验结果六为在实验结果四的基础上,没有实现动态任务划分,将线程数量修改成8的情况,同样块划分也变为10000*10000/8,发现执行速度更慢,而且线程间负载更加不均衡,考虑到原因应该是在数据已有升降序特殊处理的情况下,线程数变多会使得块划分更细,从而导致块与块之间的负载更加不均衡,因而执行速度更慢。
本实验具体代码参考3.2。
3 源代码
3.1 线程控制程序
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <semaphore.h>
#define NUM_THREADS 4
typedef struct{
int threadId;
} threadParm_t;
sem_t* sem_parent;
sem_t* sem_children[4];
void *threadFunc(void *parm){
threadParm_t *p = (threadParm_t *) parm;
fprintf(stdout, "I am the child thread %d.\n", p->threadId);
sem_wait(sem_children[p->threadId]);
sem_post(sem_parent);
fprintf(stdout, "Thread %d is going to exit.\n", p->threadId);
pthread_exit(NULL);
}
int main(int argc, char *argv[]){
int i;
sem_parent = sem_open("/mysem",O_CREAT, S_IRUSR | S_IWUSR, 10);
for (i=0; i<NUM_THREADS; i++){
sem_children[i] = sem_open("/mysem",O_CREAT, S_IRUSR | S_IWUSR, 10);
}
pthread_t thread[NUM_THREADS];
threadParm_t threadParm[NUM_THREADS];
for (i=0; i<NUM_THREADS; i++){
threadParm[i].threadId = i;
pthread_create(&thread[i], NULL, threadFunc, (void*)&threadParm[i]);
}
for (i=0; i<NUM_THREADS; i++){
sem_wait(sem_parent);
}
fprintf(stdout, "All the child threads has printed.\n");
for (i=0; i<NUM_THREADS; i++){
sem_post(sem_children[i]);
}
for (i=0; i<NUM_THREADS; i++){
pthread_join(thread[i], NULL);
}
for (i=0; i<NUM_THREADS; i++){
sem_close(sem_children[i]);
}
sem_close(sem_parent);
sem_unlink("/mysem");
return 0;
}
3.2 多个数组排序
#include <iostream>
#include <algorithm>
#include <vector>
#include <time.h>
#include <wmmintrin.h>
#include <immintrin.h>
#include <windows.h>
#include <pthread.h>
using namespace std;
typedef struct{
int threadId;
} threadParm_t;
const int ARR_NUM = 10000;
const int ARR_LEN = 10000;
const int THREAD_NUM = 8;
const int seg = ARR_NUM / THREAD_NUM;
vector<int> arr[ARR_NUM];
pthread_mutex_t amutex = PTHREAD_MUTEX_INITIALIZER;
long long head, freq; // timers
/*void init(void){ //随机生成元素
srand(unsigned(time(nullptr)));
for (int i = 0; i < ARR_NUM; i++) {
arr[i].resize(ARR_LEN);
for (int j = 0; j < ARR_LEN; j++)
arr[i][j] = rand();
}
}*/
void init_2(void){ //构造特殊数据的元素矩阵
int ratio; srand(unsigned(time(nullptr)));
for (int i = 0; i < ARR_NUM; i++) {
arr[i].resize(ARR_LEN);
if (i < seg)
ratio = 0;
else if (i < seg * 2)
ratio = 32;
else if (i < seg * 3)
ratio = 64;
else
ratio = 128;
if ((rand() & 127) < ratio)
for (int j = 0; j < ARR_LEN; j++){arr[i][j] = ARR_LEN - j;}
else
for (int j = 0; j < ARR_LEN; j++){arr[i][j] = j;}
}
}
/*void *arr_sort(void *parm){ //不做动态划分
threadParm_t *p = (threadParm_t *) parm;
int r = p->threadId; long long tail;
for (int i = r * seg; i < (r + 1) * seg; i++)
sort(arr[i].begin(), arr[i].end());
pthread_mutex_lock(&amutex);
QueryPerformanceCounter((LARGE_INTEGER *)&tail);
printf("Thread %d: %lfms.\n", r, (tail - head) * 1000.0 / freq);
pthread_mutex_unlock(&amutex);
pthread_exit(nullptr);
}*/
int next_arr = 0;
pthread_mutex_t mutex_task;
void *arr_sort_fine(void *parm){
threadParm_t *p = (threadParm_t *) parm;
int r = p->threadId; int task = 0; long long tail;
while (1) { //动态划分
pthread_mutex_lock(&mutex_task);
task = next_arr++;
pthread_mutex_unlock(&mutex_task);
if (task >= ARR_NUM) break;
stable_sort(arr[task].begin(), arr[task].end());
}
pthread_mutex_lock(&amutex);
QueryPerformanceCounter((LARGE_INTEGER *)&tail);
printf("Thread %d: %lfms.\n", r, (tail - head) * 1000.0 / freq);
pthread_mutex_unlock(&amutex);
pthread_exit(nullptr);
}
int main(int argc, char *argv[]) {
QueryPerformanceFrequency((LARGE_INTEGER *)&freq);
init_2();
amutex = PTHREAD_MUTEX_INITIALIZER;
pthread_t thread[THREAD_NUM];
threadParm_t threadParm[THREAD_NUM];
QueryPerformanceCounter((LARGE_INTEGER *)&head);
for (int i = 0; i < THREAD_NUM; i++){
threadParm[i].threadId = i;
pthread_create(&thread[i], nullptr, arr_sort_fine, (void *)&threadParm[i]);
}
for (int i = 0; i < THREAD_NUM; i++){
pthread_join(thread[i], nullptr);
}
pthread_mutex_destroy(&amutex);
}
4 实验感想
由于实验初期使用的环境时macOS,无法使用c中的windows.h头文件,由于该头文件的某些数据类型和方法在本次实验中反复使用,因此在实验初期遇到了较大障碍。最终在同学帮助下更改了实验环境并完成了本次实验。希望以此为契机呼吁c委员会实现unix系统中对windows.h文件的替换文件。














 1076
1076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









