






【翻译: System Design Interview: An Insider’s Guide】
Chapter 1:从零扩展至百万用户(一)
设计一个支持百万用户的系统非常有挑战性,这是一个需要持续精炼和无尽提升的过程。这章,将会构建一个支持单个用户的系统,然后逐渐扩展到支持百万的用户。这章之后,会掌握许多破解系统设计面试的技巧。
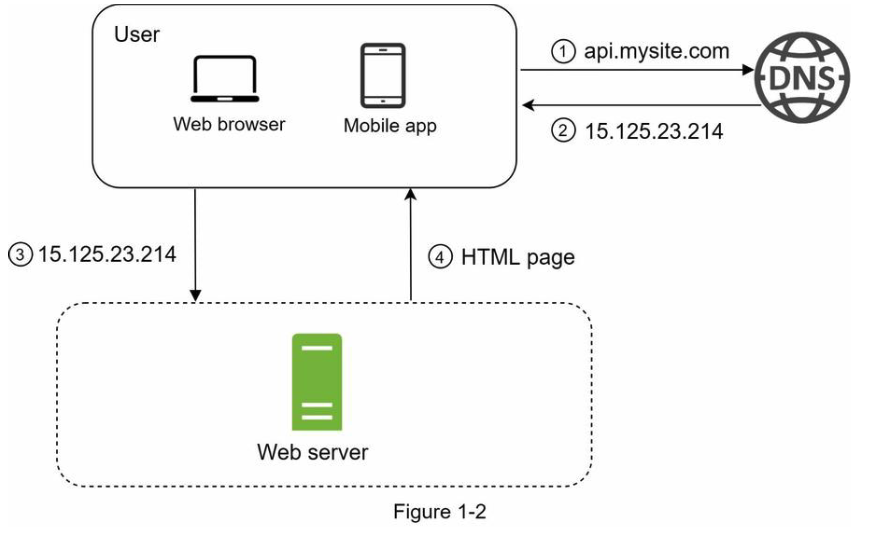
千里之行始于足下,构建一个复杂的系统也是这样。从很简单的开始,所有程序都在单个服务器上运行。如图1-1所示,单服务器设置中,所有的内容都在一台服务器上运行,web app, 数据库,缓存等。
-
用户使用域名访问,由第三方提供DNS域名解析服务
-
IP地址返回给客户端,
-
使用IP地址,利用HTTP协议[1],直接发送请求给web server
-
web server 返回HTML 页面或者Json数据
web服务器的流量来自两个来源:web应用程序和移动应用程序:
-
Web应用程序:它使用服务器端语言(Java、Python等)的组合来处理业务逻辑、存储等,并使用客户端语言(HTML和JavaScript)进行表示
-
移动应用程序:HTTP协议是移动应用程序和web服务器之间的通信协议。 JavaScript Object Notation(JSON)由于其简单性,被用于传输数据。JSON格式如下:

Database
用户数量不断上升,一台服务器不够,使用多个服务器:一台用于处理web/mobile流量,另一个存储数据,将网络层和数据层分离。
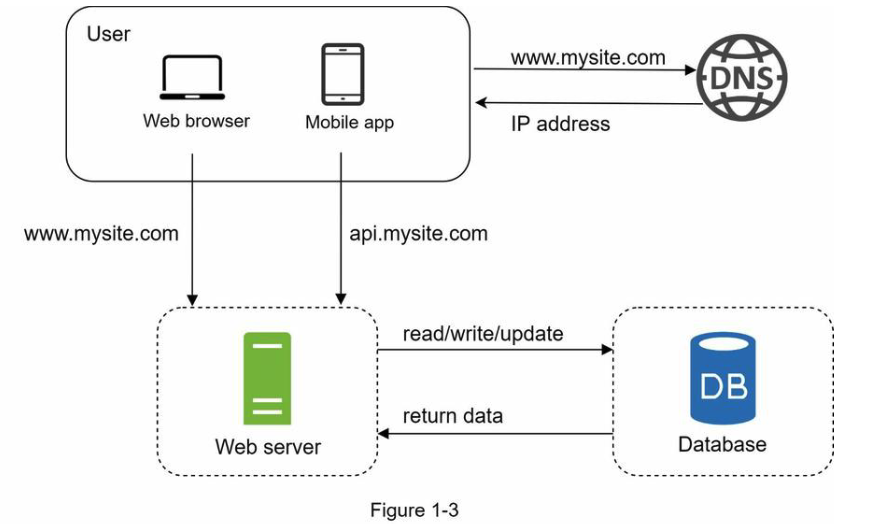
使用什么类型数据库?
可以选择关系型数据库和非关系型数据库,具体区别如下:
-
关系型数据库:又称RDBMS(relational database management system), 最主要有MySQL, Oracle database, PostgreSQL等。这些数据将数据存储在表和行里面,可以在不同的数据中进行join操作
-
非关系型数据库:又称NoSQL 数据库,有CouchDB,Neo4j, Cassandra, HBase, Amazon DynamoDB[2]等,可以分为key-value 型、图型、列型和文档性, 这些数据库通常不支持join操作。
大多数情况下,关系型数据是适用的,但是如果有以下特殊的情况,可以考虑NoSQL:
-
用户需要极低的延时
-
数据是非结构化的,不需要任何关系型数据
-
只有序列化和反序列化的数据(JSON, XML, YAML, etc)
-
需要存储极大规模数据
垂直扩展和水平扩展
垂直扩展,称为“向上扩展”,指的是使用性能更强大的服务器(CPU、RAM等)。水平扩展(称为“横向扩展”),使用更多的服务器来进行扩展。 流量很低的时候,使用垂直扩展,好处是非常简单,但是会受到限制:
-
不可能在一台机器上无限添加CPU和内存
-
一台服务器,不能做到故障容错和冗余,如果一台服务器宕机,那么整个网站直接全部崩溃
基于以上垂直扩展以上限制,水平扩展更适合大型应用,
在之前的设计中,用户直接连接到web服务器。如果web服务器处于离线状态,用户将无法访问该网站。在另一种情况下,如果许多用户同时访问web服务器,当访问量达到web服务器的负载限制,会出现响应较慢或无法连接到服务器的情况,而负载均衡器可以有效解决这些问题。
Load balancer
负载均衡器将流量平均分配给配置好的web server

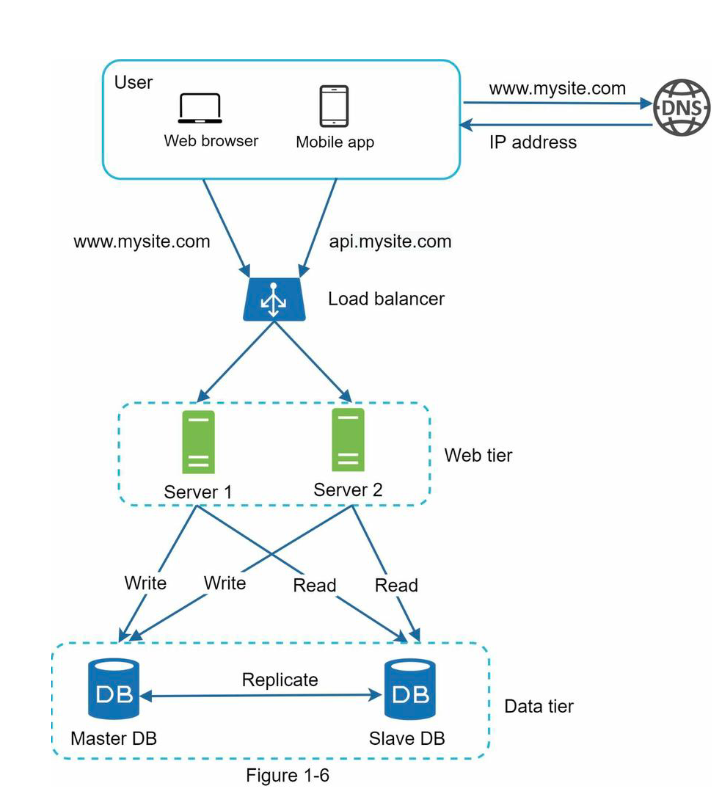
如图1-4所示,用户直接连接到负载均衡器的公网IP。通过这种设置,客户端无法直接访问web服务器。处于安全性考虑,服务器之间使用内网IP进行通信。私网IP无法通过公网访问,只能在同一局域网中的服务器才能访问;然而。负载平衡器通过内网IP与web服务器通信。
在图1-4中,在添加负载平衡器和第二个web服务器后,我们成功地解决了故障转移问题,并提高了web层的可用性。详细说明如下:
-
如果服务器1离线,所有流量将路由到服务器2。这样可以防止网站崩溃。我们还将向服务器池中添加一个新的健康web服务器,以平衡负载
-
如果网站流量快速增长,而两台服务器不足以处理流量,负载平衡器可以优雅地处理这个问题。只需向web服务器池添加更多服务器,负载平衡器就会自动开始向它们发送请求。
现在web层看起来不错,那么数据库层呢?目前的设计中,只有一个数据库,因此,它不支持故障切换和冗余。数据库复制(Database replication)可以解决以上问题
Database replication
引自维基百科:“数据库复制可用于许多数据库管理系统,通常将主-从架构在原始数据库(主)和副本数据库(从)中”[3]。
master数据库通常只支持写操作,slave数据库从主数据库获取数据副本,slave只支持读取操作。所有数据修改命令(如insert、delete或update)都必须发送到主数据库。大多数应用程序读操作的比例远大于写, 因此,系统中从数据库的数量通常大于主数据库的数量。图1-5显示了一个master数据库和多个slave数据库。
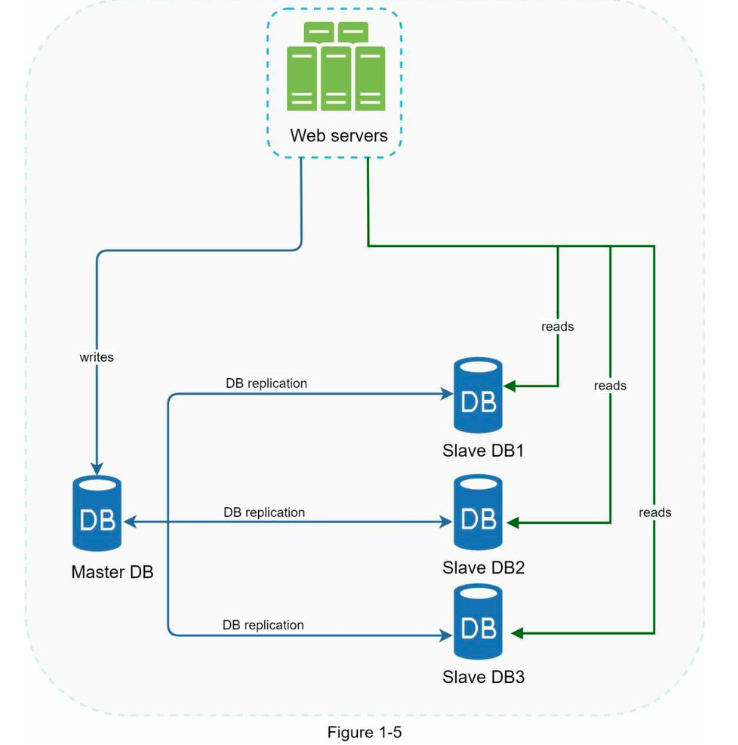
数据库复制的优点:
-
更好的性能:在主-从模式下,所有写入和更新都发生在主节点上,读取操作分布在从节点上。这种模式提高了性能,支持并行处理更多的查询
-
可靠性:如果您的一台数据库服务器被不可抗力因素破坏,例如地震、台风,数据仍会保留。不必担心数据丢失,因为数据被跨区域、多点备份
-
高可用性:通过在不同的位置备份数据,当一台数据库离线了,网站仍然可用
之前的章节中讨论了,负载均衡器如何提升系统的可用性,现在讨论同样的问题:如果其中一个数据库离线怎么办?图1-5中的架构设计可以处理这种情况:
-
如果只有一个slave数据库可用,并且它处于离线状态,则读取操作将临时指向主数据库。故障被发现后,新的从数据库将取代旧的。如果有多个从数据库可用,读取操作将重定向到其他正常的从数据库。新的数据库服务器将取代旧的数据库服务器
-
如果master数据库离线,slave数据库将升级为新的master数据库。所有数据库操作将临时在新的主数据库上执行。新的slave数据库将立即取代旧的数据库进行数据复制。在生产项目中,升级一个新的主数据库更加复杂,因为从数据库中的数据可能不是最新的。丢失的数据需要通过运行数据恢复脚本进行更新。虽然其他一些复制方法,如多台master主机和循环复制,但会使配置更加复杂, 这里超出了讨论的范围。感兴趣的读者可以参考这些文章[4][5]。
图1-6展示了添加了负载均衡和数据库复制的系统设计:
缓存
缓存是一个临时存储区域,用于将请求代价高或频繁访问的数据存储在内存中,以后续请求速度。如图1-6所示,每次加载新网页时,都会执行一个或多个数据库调用来获取数据。重复调用数据库会极大地影响应用程序的性能。缓存可以缓解这个问题。
缓存层
缓存层是一个临时数据存储层,比数据库快得多。独立缓存层的好处包括:更好的系统性能、降低数据库负载,以及缓存层可以独立扩展。图1-7展示了缓存服务器可能的设置:

在收到请求后,web服务器首先检查缓存内是否有可用的数据。如果有,它会将数据返回回客户端。如果没有,它会查询数据库,将数据存储在缓存中,并将其返回回客户端。这种缓存策略称为读缓存。根据数据类型、大小和访问模式,还可以使用其他缓存策略。有专门的研究解释不同的缓存策略是如何工作的[6]。
与缓存服务器交互很简单,因为大多数缓存服务器都为通用编程语言提供API。以下代码片段显示了典型的Memcached API:

使用缓存的注意事项
以下是使用缓存的注意事项:
-
决定何时使用缓存。当数据频繁读取但不经常修改时,考虑使用缓存。由于缓存的数据存储在易失性内存中,缓存服务器不适合持久化数据。例如,如果缓存服务器重新启动,内存中的所有数据都将丢失。因此,重要数据应保存在永久性数据存储中
-
过期策略。实施过期策略一种良好的做法。缓存的数据一旦过期,就会从缓存中删除。当没有过期策略时,缓存的数据将永久存储在内存中。建议不要使过太短的过期策略,因为这会导致系统过于频繁地从数据库重新加载数据。同时建议不要将过期时间设置得太长, 由于数据可能会过时
-
一致性:这涉及保持数据存储和缓存同步。由于数据存储和缓存上的数据修改操作不在单个事务中,因此可能会发生不一致。跨多个区域缩放时,保持保持数据存储和缓存之间的一致性是一项挑战。有关更多详细信息,请参阅Facebook发表的题为“Scaling Memcache at Facebook”的论文[7]。
-
故障减轻:单个缓存服务器代表潜在的单点故障(SPOF,single point of failure ),单点故障在维基百科中定义如下:“单点故障(SPOF)是系统的一部分,如果发生故障,整个系统将停止工作”[8]。因此,建议跨不同数据中心设置多个缓存服务器,以避免SPOF。另一个推荐的方法是按百分比超额提供所需的内存。随着内存使用量的增加,这提供了一个缓冲区
-
淘汰策略:一旦缓存已满,任何向缓存中添加数据的请求都可能导致现有数据被删除,这叫做缓存淘汰。Least-recently-used(LRU)是最流行的缓存淘汰策略, 其他淘汰策略,如Least Frequently Used (LFU)或先进先出(FIFO),可以用来满足不同的使用场景。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









