






MapReduce: Simplified Data Processing on Large Cluster
abstract
MapReduce 是一种用于处理和生成大型数据集的编程模型,使用Map function 处理键-值对, 然后得到一系列中间值, reduce 合并拥有相同的键的键值对, 现实世界中很多任务都符合这个模型。
以这种风格编写的程序,可以并行运行在大规模的商业机器上,运行时系统负责对输入数据进行分区,在一系列机器上协同程序的执行,处理机器故障,以及管理所需的机器间通信。这使得没有任何并行和分布式系统经验的程序员能够轻松地利用大型分布式系统的资源。
MapReduced 的实现代码运行在大规模商业机器上,并且拥有高度扩展性,典型的Mapreduce 计算进程,可以协同几千台机器,处理TB级别的数据。该系统易于使用:每天都有上百个MapReduce的程序被开发,有超过1000个MapReduce的job在Google 集群中运行。
1. Introduction
Google 实现了上百个特定任务的计算程序,以处理大规模原始数据:爬取文件, 网络日志。这些数据来计算比如:每个host 爬取的page数量, 指定日期最多访问的网页。虽然这些任务很简单, 但是因为数据庞大,导致需要处理一下问题, 使得原有问题变得复杂
- 并发问题
- 负载均衡
- 数据分配
- 故障处理
设计了一种abstraction,隐藏一些复杂的细节(并发、数据分配、故障处理、负载均衡),将这些封装成库。 这种abstracion受到Lisp 中原语Map和Reduce 启发, 且大多数计算问题可以抽象成:将原始数据Map转换成一些中间 key - value, 使用reduce 聚合派生数据。 这种Map,Reduce操作,让大型计算任务变得简单,而且有重启动机制,实现fault tolerance
主要贡献:提出简单、强大的接口,让大规模并行运算成为可能; 实现了这个接口,而且在商用PC 集群上有很高的性能。
Section2:介绍基本编程模型; Section3: 描述了在集群环境下的,编程的实现, Section4: 提出了一些对模型有用的改进; Section5: 性能测试; Section6: MapReduce 在Google 内的使用经验; Section7: 相关和未来工作
2 Programming Model
计算输入:一套key/value 对
计算输出:一套key/value 对
MapReduce lib 将计算分为 Map 和Reduce 两个部分
- Map: 用户编写,将输入pair 转化成一系列intermediate的 key/value 对,Mapreduce 库将这些中间过程的 key/value 以key 分组, 然后将这些传递给Reduce function
- Reduce: 也由用户编写,接受一个intermediate的的key 和与之相关的value,将数值合并。通常一个Reduce 调用产生一个output。 Reduce 的值通过iterator给用户, 用以处理大规模的数据。
2.1 例子
统计文件中单词的数量

2.2 类型
2.3 其他的用例
- 分布式grep(抓取)
- 统计URL 访问频率
- 创建倒排索引:map 发出〈word, document ID〉键值对,reduce 合并,收到〈word, list(document ID)〉,
- 反向Web-链接图:用于target URL的链接叫做source, Map emit 出:〈target, source〉键值对, reduce 输出〈target, list(source)〉
3. Implementation
(1)Google 内运行环境:每台机器: x86 processors, Linux, with 2-4 GB 内存
(2)100Mb/1Gb 网速
(3)一个集群内有几百台机器,有故障是常态
(4)存储设备使用的是普通廉价硬盘,文件系统使用replication 保证可用性和可靠性
(5)用户提交job到调度程序, 每个job有一系列任务,
3.1 Execution Overview
Map 调用是跨多台机器进行的,自动将输入data 分布成M份,可以并行地被M台机器处理,Reduce 使用分区函数(eg: hash(key)modR), 调用intermediate key 分配到R个分片。
图1展示了整个运行的流程,用户调用MapReduce 程序时,以下动作依次进行:
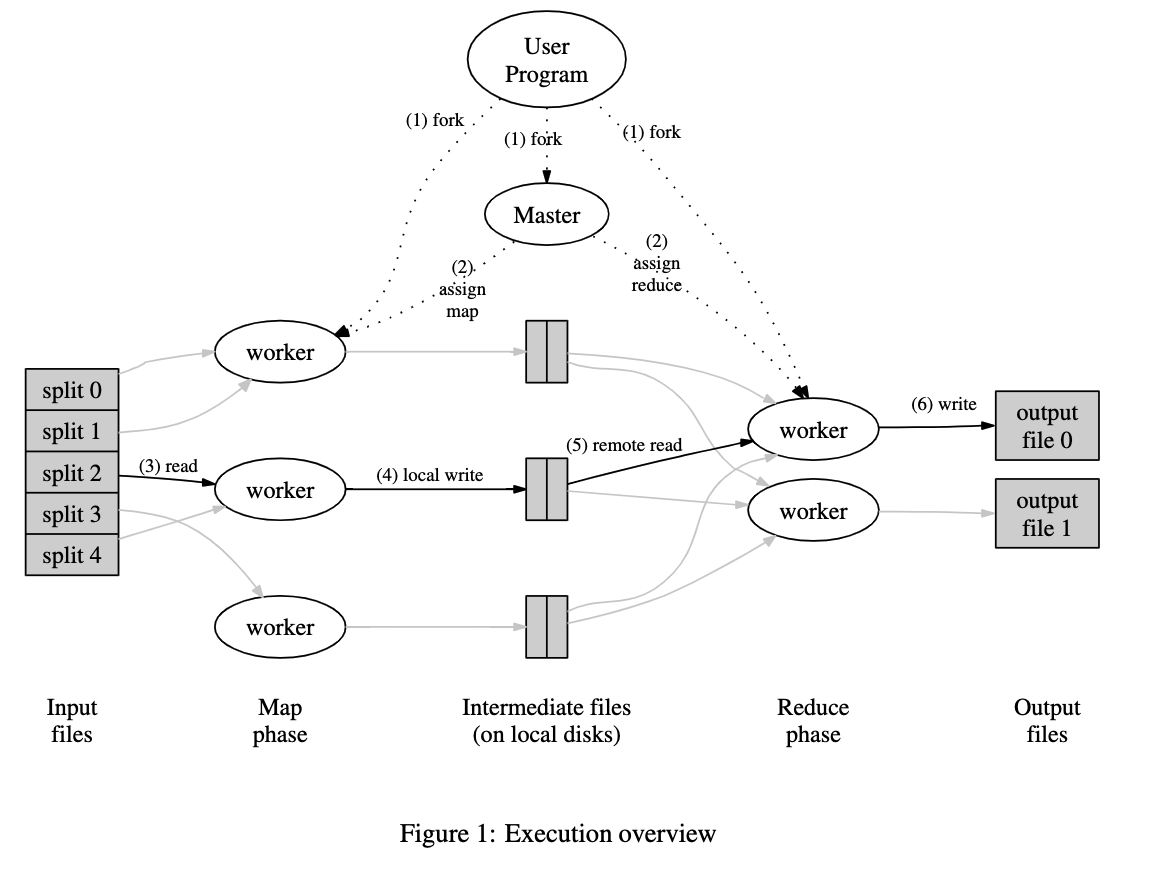
-
MapReduce库将输入数据分为M个 16 ~ 64MB的数据块,然后在集群中启动多份copy程序
-
其中一个copy – master 很特殊,master 分配任务给 workers, master 找到idle 的worker, 为其分配map 或者reduce task
-
分配到map 任务的work 读取输入文件, 将输入数据解析成 key/value对, 然后将pair 传递给用户定义的Map 函数。Map 函数缠身的intermediated 键值对先缓存在内存中
-
buffered pair 定时写入本地磁盘,然后使用分区函数分配到R个Region。buffered pair 的文职被传递给master, 然后master 负责将这些位置转发给Reduce worker
-
master 通知reduce worker 有intermediated 文件位置,然后使用RPC 从map函数阅读buffered data。 reduce worker 读完intermediated 数据之后, 对读完intermediated key 进行排序,将相同键的合并在一起(排序一定需要),键太大时,内存不够时,可以使用外部排序。
-
Reduce worker 迭代sorted intermediate shuju ,每个唯一的键都统计, 将这些intermediate values 传递到用户自定义的Reduce 函数。 Reduce函数的最后输出被追加到最终输出文件
-
所有map 和Reduce 任务完成之后,master 唤醒用户程序,这是MapReduce 的调用返回到用户代码
所以过程都成功了之后,mapreduce的输出保存在 R个输出文件中(每个Reduce Task一个文件)。按照惯例,用户不需要合并R个文件。一般是做为下一次Mapreduce 调用的输入。 或者作为其余可以处理多个文件的分布式应用的输入
3.2 Master Data structure
Master 维持着几个数据结构:
Map 和 Reduce 任务, 三种状态(idle, in-process, completed)
Master 作为唯一线索, 记录每个从map task 传递到reduce task 的intermediate file 。 这些信息被
3.3 Fault Tolerance
MapReduce 集群机器数量庞大,因此需要优雅地处理故障
Work 故障
Master定时去 ping worker, 一段时间无法接到worker 心跳,标记work 故障。所有完成的Map任务被重新设置成idle state, 然后可以安排在其他worker上。 类似,所有进行中的Map 和 Reduce任务也会被设置成idle ,然后重新调度。
完成的Map 任务被重新运行,因为这些输出存在reduce本地磁盘上,无法访问,
Master 故障
master 定时在检查点,将master的数据结构写入,如果master 任务发生故障, 那么新的master可以在检查点重新启动。 Master 只有一个,不大可能故障,一旦故障,按照设计,将放弃MapReduce的计算
出现故障时的语义
如果用户提供的Map和Reduce 操作是确定性的,那么分布式系统的输出结果将与顺序、无故障的运行相同。
通过原子性提交map和Reduce的操作实现这个特性,运行中的任务将output写入本地临时文件。一个Reduce 任务产生这样的一个文件,一个map任务产生R个(分给R个Reduce 任务)文件。 Map 任务完成之后,会发送消息给Master, 包含输出文件的位置,Map 完成任务完成了,给master 发送消息,然后master 更新本地的数据结构(此任务如已经完成master忽略)。
task 任务完成,reduce worker 将暂时文件重命名成最终输出文件。如果多台机器同时完成了Reduce操作,那么final输出文件将产生多个重命名操作。为保证输出文件由一个reduce Task完成的。这里依赖于底层操作系统提供的原子rename 操作。(Go 中可以使用IoUtil.Tempfile(), 和os.Rename() 功能)
大多数map 和Reduce操作都是deterministic的,所以多个map reduce并发操作的语义是等同于sequential进行的。 当 map 和/或 reduce 运算是非deterministic时,我们提供较弱但仍然合理的语义。在存在非deterministic运算的情况下,特定 reduce 任务 R1 的输出等价于由非确定性程序的顺序执行产生的 R1 的输出。但是,不同的 reduce 任务 R2 的输出可能对应于另外一个非确定性程序的sequential执行产生的 R2 的输出。(某种程度上也是合理的语义)
3.4 Locality
带宽资源相对缺乏,input 数据保存在GFS 集群中(GFS 建立在Mapreduce集群的硬盘上,避免数据对宽带的占用)。 输入信息的位置在master上有记录,这样尽量将map任务分配给存有对应输入数据的机器上。如果做不到,那么分配到临近输入数据的机器(相同的交换机)。这样数据的输入几乎不占用网络带宽。
3.5 Task Granularity (任务颗粒度)
将 map 阶段细分为 M 个pieces,将 reduce 阶段细分为 R 个pieces。理想情况下,M 和 R 应该远大于工作机器的数量。让每个worker执行许多不同的任务, 以实现动态负载平衡。且worker故障时,可以提升恢复速度:将完成的map的任务传播到别的worker上执行。
但实际上M和R有限制, master需要花费O(M + R)的时间复杂度去分配任务,使用O(M * R)的空间维持状态。R也受到用户的限制, 因为每个Reduce 任务都会产生一个输出文件。 一般来说,调整M, 使得一个输入文件有16 ~ 64MB, R = k * Num(work), k 是一个相对较小的数。例如: 一个Mapreduce任务: M = 200000, R = 5000, 2000个worker.
3.6 Backup Task
MapReduce 操作总时间被延长,主要因为几个Map 和Reduce需要非常长的时间(straggler)。 straggler 有以下一些原因:磁盘故障,读取性能从 30 MB/s 降低到 1 MB/s;机器运行很多其他任务,硬件资源紧张;机器初始化代码错误, 计算速度减慢了一百多倍。
straggler的出现可能有很多原因。例如,具有坏磁盘的机器可能会经常遇到可纠正的错误,从而将其读取性能从 30 MB/s 降低到 1 MB/s。集群调度系统可能已经在机器上调度了其他任务,由于 CPU、内存、本地磁盘或网络带宽的竞争,导致它执行 MapReduce 代码更慢。我们最近遇到的一个问题是机器初始化代码中的一个错误,它导致处理器缓存被禁用:受影响机器上的计算速度减慢了一百多倍。
使用机制减轻straggler问题,当MapReduce 任务快要完成时,master 为仍在运行的task 安排备份任务(backup task)。调优后,这个机制增加很少比例的计算资源,但是有效减少了运行时间。例如,排序任务中,不使用backup task, 会增加44%的时间。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









