






18 Tuning the Performance of Oracle GoldenGate
This chapter contains suggestions for improving the performance of Oracle GoldenGate components.
Topics:
18.1 Using Multiple Process Groups
通常,从数据库有效地捕获一个提取组是必需的。但是,根据redo (transactional)值或数据和操作类型,您可能会发现需要向配置添加一个或多个提取组。
类似地,如果在协调模式下使用Replicat,通常只需要一个Replicat组就可以将数据应用到目标数据库。(有关更多信息,请参阅协调复制模式。)但是,即使在某些情况下,在协调模式下使用Replicat,也可能需要使用多个Replicat组。如果您在经典模式下使用Replicat,并且您的应用程序生成一个高事务量,那么您可能需要使用并行的Replicat组。
因为每个Oracle GoldenGate组件——Extract、data pump、trail、Replicat——都是一个独立的模块,您可以以适合自己需要的方式组合它们。您可以使用多个跟踪和并行提取和复制进程(带或不带数据泵)来处理大量事务、提高性能、消除瓶颈、减少延迟或隔离特定数据的处理。
Figure 18-1 shows some of the ways that you can configure Oracle GoldenGate to improve throughput speed and overcome network bandwidth issues.
Figure 18-1 Load-balancing configurations that improve performance
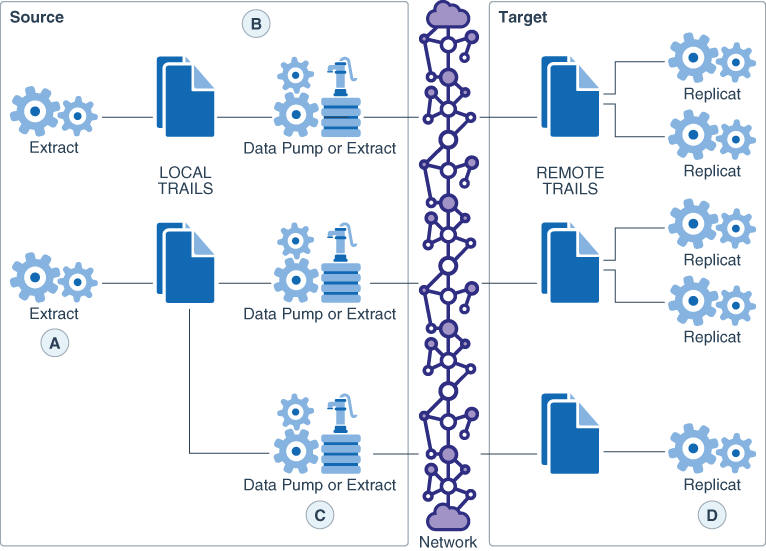 The image labels imply the following:
The image labels imply the following:
-
A: Parallel Extracts divide the load. For example, by schema or to isolate tables that generate fetches.
-
B: A data pump with local trail can be used for filtering, conversion, and network false tolerance.
-
C: Multiple data pumps work around network per-process bandwidth limitations to enable TCP/IP throughput. Divide the TABLE parameter statements among them.
-
D: Parallel Replicats increase throughput to the database. Any trail can be read by one or more Replicats. Divide MAP statements among them.
18.1.1 Considerations for Using Multiple Process Groups
在配置多个处理组之前,请检查以下事项,以确保配置产生所需的结果并维护数据完整性。
18.1.1.1 Maintaining Data Integrity
Not all workloads can be partitioned across multiple groups and still preserve the original transaction atomicity. You must determine whether the objects in one group will ever have dependencies on objects in any other group, transactional or otherwise. For example, tables for which the workload routinely updates the primary key cannot easily be partitioned in this manner. DDL replication (if supported for the database) is not viable in this mode, nor is the use of some SQLEXEC or EVENTACTIONS features that base their actions on a specific record.
If your tables do not have any foreign- key dependencies or updates to primary keys, you may be able to use multiple processes. Keep related DML together in the same process stream to ensure data integrity.
18.1.1.2 Number of Groups
The number of concurrent Extract and Replicat process groups that can run on a system depends on how much system memory is available. Each Extract and Replicat process needs approximately 25-55 MB of memory, or more depending on the size of the transactions and the number of concurrent transactions.
The Oracle GoldenGate GGSCI command interface fully supports up to 5,000 concurrent Extract and Replicat groups per instance of Oracle GoldenGate Manager. At the supported level, all groups can be controlled and viewed in full with GGSCI commands such as the INFO and STATUS commands. Beyond the supported level, group information is not displayed and errors can occur. Oracle GoldenGate recommends keeping the number of Extract and Replicat groups (combined) at the default level of 300 or below in order to manage your environment effectively. The number of groups is controlled by the MAXGROUPS parameter.
Note:
When creating the groups, keep tables that have relational constraints to each other in the same group.
18.1.1.3 Memory
The system must have sufficient swap space for each Oracle GoldenGate Extract and Replicat process that will be running. To determine the required swap space:
- Start up one Extract or Replicat.
- Run GGSCI.
- View the report file and find the line
PROCESS VM AVAIL FROM OS (min). - Round up the value to the next full gigabyte if needed. For example, round up 1.76GB to 2 GB.
- Multiply that value by the number of Extract and Replicat processes that will be running. The result is the maximum amount of swap space that could be required
See the CACHEMGR parameter in Reference for Oracle GoldenGate for more information about how memory is managed.
18.1.1.4 Isolating Processing-Intensive Tables
You can use multiple process groups to support certain kinds of tables that tend to interfere with normal processing and cause latency to build on the target. For example:
-
Extract may need to perform a fetch from the database because of the data type of the column, because of parameter specifications, or to perform SQL procedures. When data must be fetched from the database, it affects the performance of Extract. You can get fetch statistics from the
STATS EXTRACTcommand if you include theSTATOPTIONS REPORTFETCHparameter in the Extract parameter file. You can then isolate those tables into their own Extract groups, assuming that transactional integrity can be maintained. -
In its classic mode, Replicat process can be a source of performance bottlenecks because it is a single-threaded process that applies operations one at a time by using regular SQL. Even with
BATCHSQLenabled (see Reference for Oracle GoldenGate) Replicat may take longer to process tables that have large or long-running transactions, heavy volume, a very large number of columns that change, and LOB data. You can then isolate those tables into their own Replicat groups, assuming that transactional integrity can be maintained.
18.1.2 Using Parallel Replicat Groups on a Target System
本节包含创建配置的说明,该配置将一个提取组与多个副本组配对。尽管多个Replicat进程可以读取单个轨迹(不超过三个以避免磁盘争用),但建议将每个Replicat与它自己的轨迹和相应的提取进程配对。
-
Refer to Reference for Oracle GoldenGate for Windows and UNIX for command and parameter syntax.
-
For detailed instructions on configuring change synchronization, see Configuring Online Change Synchronization.
18.1.2.1 To Create the Extract Group
Note:
This configuration includes Extract data-pumps.
- On the source, use the
ADD EXTRACTcommand to create a primary Extract group. - On the source, use the
ADD EXTTRAILcommand to specify as many local trails as the number of Replicat groups that you will be creating. All trails must be associated with the primary Extract group. - On the source create a data-pump Extract group.
- On the source, use the
ADD RMTTRAILcommand to specify as many remote trails as the number of Replicat groups that you will be creating. All trails must be associated with the data-pump Extract group. - On the source, use the
EDIT PARAMScommand to create Extract parameter files, one for the primary Extract and one for the data pump, that contain the parameters required for your database environment. When configuring Extract, do the following:-
Divide the source tables among different
TABLEparameters. -
Link each
TABLEstatement to a different trail. This is done by placing theTABLEstatements after theEXTTRAILorRMTTRAILparameter that specifies the trail you want those statements to be associated with.
-
18.1.2.2 To Create the Replicat Groups
- On the target, create a Replicat checkpoint table. For instructions, see Creating a Checkpoint Table. All Replicat groups can use the same checkpoint table.
- On the target, use the
ADD REPLICATcommand to create a Replicat group for each trail that you created. Use theEXTTRAILargument of ADD REPLICAT to link the Replicat group to the appropriate trail. - On the target, use the
EDIT PARAMScommand to create a Replicat parameter file for each Replicat group that contains the parameters required for your database environment. AllMAPstatements for a given Replicat group must specify the same objects that are contained in the trail that is linked to that group. - In the Manager parameter file on the target system, use the
PURGEOLDEXTRACTSparameter to control the purging of files from the trails.
18.1.3 Using Multiple Extract Groups with Multiple Replicat Groups
多个提取组写入它们自己的踪迹。每个记录由一个专门的副本组读取。
-
Refer to Reference for Oracle GoldenGate for Windows and UNIX for command and parameter syntax.
-
For detailed instructions on configuring change synchronization, see Configuring Online Change Synchronization.
18.1.3.1 To Create the Extract Groups
Note:
This configuration includes data pumps.
- On the source, use the
ADD EXTRACTcommand to create the primary Extract groups. - On the source, use the
ADD EXTTRAILcommand to specify a local trail for each of the Extract groups that you created. - On the source create a data-pump Extract group to read each local trail that you created.
- On the source, use the
ADD RMTTRAILcommand to specify a remote trail for each of the data-pumps that you created. - On the source, use the
EDIT PARAMScommand to create an Extract parameter file for each primary Extract group and each data-pump Extract group.
18.1.3.2 To Create the Replicat Groups
- On the target, create a Replicat checkpoint table. For instructions, see Creating a Checkpoint Table. All Replicat groups can use the same checkpoint table.
- On the target, use the
ADD REPLICATcommand to create a Replicat group for each trail. Use theEXTTRAILargument ofADD REPLICATto link the group to the trail. - On the target, use the
EDIT PARAMScommand to create a Replicat parameter file for each Replicat group. AllMAPstatements for a given Replicat group must specify the same objects that are contained in the trail that is linked to the group. - In the Manager parameter files on the source system and the target system, use the
PURGEOLDEXTRACTSparameter to control the purging of files from the trails.
18.2 Splitting Large Tables Into Row Ranges Across Process Groups
可以使用@RANGE函数将任何表的行划分为两个或多个Oracle GoldenGate进程。它可用于增加大型和频繁访问的表的吞吐量,也可用于将数据划分为集,以便分发到不同的目的地。在表或MAP语句的筛选子句中指定每个范围。
@RANGE is safe and scalable. It preserves data integrity by guaranteeing that the same row will always be processed by the same process group.
It might be more efficient to use the primary Extract or a data pump to calculate the ranges than to use Replicat. To calculate ranges, Replicat must filter through the entire trail to find data that meets the range specification. However, your business case should determine where this filtering is performed.
Figure 18-2 Dividing rows of a table between two Extract groups

Description of "Figure 18-2 Dividing rows of a table between two Extract groups"
Figure 18-3 Dividing rows of a table between two Replicat groups

Description of "Figure 18-3 Dividing rows of a table between two Replicat groups"
18.3 Configuring Oracle GoldenGate to Use the Network Efficiently
跨网络传输数据的低效会导致提取过程的延迟和目标的延迟。如果不进行纠正,最终可能导致流程失败。
When you first start a new Oracle GoldenGate configuration:
-
Establish benchmarks for what you consider to be acceptable lag and throughput volume for Extract and for Replicat. Keep in mind that Extract will normally be faster than Replicat because of the kind of tasks that each one performs. Over time you will know whether the difference is normal or one that requires tuning or troubleshooting.
-
Set a regular schedule to monitor those processes for lag and volume, as compared to the benchmarks. Look for lag that remains constant or is growing, as opposed to occasional spikes. Continuous, excess lag indicates a bottleneck somewhere in the Oracle GoldenGate configuration. It is a critical first indicator that Oracle GoldenGate needs tuning or that there is an error condition.
To view volume statistics, use the STATS EXTRACT or STATS REPLICAT command. To view lag statistics, use the LAG EXTRACT or LAG REPLICAT command. See Reference for Oracle GoldenGate for Windows and UNIX for more information.
18.3.1 Detecting a Network Bottleneck that is Affecting Oracle GoldenGate
To detect a network bottleneck that is affecting the throughput of Oracle GoldenGate, follow these steps.
- Issue the following command to view the ten most recent Extract checkpoints. If you are using a data-pump Extract on the source system, issue the command for the primary Extract and also for the data pump.
INFO EXTRACT group, SHOWCH 10 - Look for the
Write Checkpointstatistic. This is the place where Extract is writing to the trail.Write Checkpoint #1 GGS Log Trail Current Checkpoint (current write position): Sequence #: 2 RBA: 2142224 Timestamp: 2011-01-09 14:16:50.567638 Extract Trail: ./dirdat/eh - For both the primary Extract and data pump:
-
Determine whether there are more than one or two checkpoints. There can be up to ten.
-
Find the
Write Checkpointnheading that has the highest increment number (for example,Write Checkpoint #8) and make a note of theSequence,RBA, andTimestampvalues. This is the most recent checkpoint.
-
- Refer to the information that you noted, and make the following validation:
-
Is the primary Extract generating a series of checkpoints, or just the initial checkpoint?
-
If a data pump is in use, is it generating a series of checkpoints, or just one?
-
- Issue
INFO EXTRACTfor the primary and data pump Extract processes again.-
Has the most recent write checkpoint increased? Look at the most recent
Sequence,RBA, andTimestampvalues to see if their values were incremented forward since the previousINFO EXTRACTcommand.
-
- Issue the following command to view the status of the Replicat process.
SEND REPLICAT group, STATUS-
The status indicates whether Replicat is delaying (waiting for data to process), processing data, or at the end of the trail (EOF).
-
There is a network bottleneck if the status of Replicat is either in delay mode or at the end of the trail file and either of the following is true:
-
You are only using a primary Extract and its write checkpoint is not increasing or is increasing too slowly. Because this Extract process is responsible for sending data across the network, it will eventually run out of memory to contain the backlog of extracted data and abend.
-
You are using a data pump, and its write checkpoint is not increasing, but the write checkpoint of the primary Extract is increasing. In this case, the primary Extract can write to its local trail, but the data pump cannot write to the remote trail. The data pump will abend when it runs out of memory to contain the backlog of extracted data. The primary Extract will run until it reaches the last file in the trail sequence and will abend because it cannot make a checkpoint.
Note:
Even when there is a network outage, Replicat will process in a normal manner until it applies all of the remaining data from the trail to the target. Eventually, it will report that it reached the end of the trail file.
18.3.2 Working Around Bandwidth Limitations by Using Data Pumps
使用并行数据泵可以使您绕过网络配置中对每个进程施加的带宽限制。可以使用并行数据泵将数据发送到相同的目标系统或不同的目标系统。数据泵还从主提取中移除TCP/IP职责,并且它们的本地跟踪提供容错能力。
18.3.3 Reducing the Bandwidth Requirements of Oracle GoldenGate
在通过网络发送数据之前,使用RMTHOST参数的压缩选项来压缩数据。将压缩的好处与执行压缩所需的CPU资源进行比较。See Reference for Oracle GoldenGate for more information.
18.3.4 Increasing the TCP/IP Packet Size
使用RMTHOST参数的TCPBUFSIZE选项来控制Extract维护的TCP套接字缓冲区的大小。通过增加缓冲区的大小,可以向目标系统发送更大的数据包。有关更多信息,请参阅Oracle GoldenGate的参考资料。
Use the following steps as a guideline to determine the optimum buffer size for your network.
- Use the
pingcommand from the command shell obtain the average round trip time (RTT), shown in the following example:C:\home\ggs>ping ggsoftware.com Pinging ggsoftware.com [192.168.116.171] with 32 bytes of data: Reply from 192.168.116.171: bytes=32 time=31ms TTL=56 Reply from 192.168.116.171: bytes=32 time=61ms TTL=56 Reply from 192.168.116.171: bytes=32 time=32ms TTL=56 Reply from 192.168.116.171: bytes=32 time=34ms TTL=56 Ping statistics for 192.168.116.171: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 31ms, Maximum = 61ms, Average = 39ms - Multiply that value by the network bandwidth. For example, if average RTT is .08 seconds, and the bandwidth is 100 megabits per second, then the optimum buffer size is:
0.08 second * 100 megabits per second = 8 megabits - Divide the result by 8 to determine the number of bytes (8 bits to a byte). For example:
8 megabits / 8 = 1 megabyte per secondThe required unit for
TCPBUFSIZEis bytes, so you would set it to a value of 1000000.
The maximum socket buffer size for non-Windows systems is usually limited by default. Ask your system administrator to increase the default value on the source and target systems so that Oracle GoldenGate can increase the buffer size configured with TCPBUFSIZE.
18.4 Eliminating Disk I/O Bottlenecks
I/O activity can cause bottlenecks for both Extract and Replicat.
-
A regular Extract generates disk writes to a trail and disk reads from a data source.
-
A data pump and Replicat generate disk reads from a local trail.
-
Each process writes a recovery checkpoint to its checkpoint file on a regular schedule.
18.4.1 Improving I/O performance Within the System Configuration
If there are I/O waits on the disk subsystems that contain the trail files, put the trails on the fastest disk controller possible.
Check the RAID configuration. Because Oracle GoldenGate writes data sequentially, RAID 0+1 (striping and mirroring) is a better choice than RAID 5, which uses checksums that slow down I/O and are not necessary for these types of files.
18.4.2 Improving I/O Performance Within the Oracle GoldenGate Configuration
You can improve I/O performance by making configurations changes within Oracle GoldenGate. Try increasing the values of the following parameters.
-
Use the
CHECKPOINTSECSparameter to control how often Extract and Replicat make their routine checkpoints.Note:
CHECKPOINTSECSis not valid for an integrated Replicat on an Oracle database system. -
Use the
GROUPTRANSOPSparameter to control the number of SQL operations that are contained in a Replicat transaction when operating in its normal mode. Increasing the number of operations in a Replicat transaction improves the performance of Oracle GoldenGate by reducing the number of transactions executed by Replicat, and by reducing I/O activity to the checkpoint file and the checkpoint table, if used. Replicat issues a checkpoint whenever it applies a transaction to the target, in addition to its scheduled checkpoints.Note:
GROUPTRANSOPSis not valid for an integrated Replicat on an Oracle database system, unless the inbound server parameterparallelismis set to 1. -
Use the
EOFDELAYorEOFDELAYCSECSparameter to control how often Extract, a data pump, or Replicat checks for new data after it has reached the end of the current data in its data source. You can reduce the system I/O overhead of these reads by increasing the value of this parameter.
Note:
Increasing the values of these parameters improves performance, but it also increases the amount of data that must be reprocessed if the process fails. This has an effect on overall latency between source and target. Some testing will help you determine the optimal balance between recovery and performance.
18.5 Managing Virtual Memory and Paging
因为Oracle GoldenGate只复制提交的事务,所以它将每个事务的操作存储在托管的称为缓存的虚拟内存池中,直到它收到该事务的提交或回滚。一个全局缓存作为提取或复制进程的共享资源运行。Oracle GoldenGate cache manager充分利用了操作系统的内存管理功能,保证了Oracle GoldenGate进程持续高效的工作。CACHEMGR参数控制用于缓存Oracle GoldenGate正在处理的未提交事务数据的虚拟内存和临时磁盘空间的数量。
When a process starts, the cache manager checks the availability of resources for virtual memory, as shown in the following example:
CACHEMGR virtual memory values (may have been adjusted)CACHESIZE: 32GCACHEPAGEOUTSIZE (normal): 8M PROCESS VM AVAIL FROM OS (min): 63.97GCACHESIZEMAX (strict force to disk): 48G
If the current resources are not sufficient, a message like the following may be returned:
2013-11-11 14:16:22 WARNING OGG-01842 CACHESIZE PER DYNAMIC DETERMINATION (32G) LESS THAN RECOMMENDED: 64G (64bit system)vm found: 63.97GCheck swap space. Recommended swap/extract: 128G (64bit system).
If the system exhibits excessive paging and the performance of critical processes is affected, you can reduce the CACHESIZE option of the CACHEMGR. parameter. You can also control the maximum amount of disk space that can be allocated to the swap directory with the CACHEDIRECTORY option. For more information about CACHEMGR, see Reference for Oracle GoldenGate.
18.6 Optimizing Data Filtering and Conversion
大量的数据过滤或数据转换增加了处理开销。下面是一些建议,这些建议可以最大限度地减少这种开销对系统中其他进程的影响。
-
Avoid using the primary Extract to filter and convert data. Keep it dedicated to data capture. It will perform better and is less vulnerable to any process failures that result from those activities. The objective is to make certain the primary Extract process is running and keeping pace with the transaction volume.
-
Use Replicat or a data-pump to perform filtering and conversion. Consider any of the following configurations:
-
Use a data pump on the source if the system can tolerate the overhead. This configuration works well when there is a high volume of data to be filtered, because it uses less network bandwidth. Only filtered data gets sent to the target, which also can help with security considerations.
-
Use a data pump on an intermediate system. This configuration keeps the source and target systems free of the overhead, but uses more network bandwidth because unfiltered data is sent from the source to the intermediate system.
-
Use a data pump or Replicat on the target if the system can tolerate the overhead, and if there is adequate network bandwidth for sending large amounts of unfiltered data.
-
-
If you have limited system resources, a least-best option is to divide the filtering and conversion work between Extract and Replicat.
18.7 Tuning Replicat Transactions
Replicat使用常规SQL,因此它的性能取决于目标数据库的性能和应用的SQL类型(插入、更新或删除)。但是,您可以采取某些步骤来最大化复制效率。
18.7.1 Tuning Coordination Performance Against Barrier Transactions
在协调的Replicat配置中,主键更新之类的屏障事务会导致向数据库提交的次数增加,并且会破坏Replicat的GROUPTRANSOPS特性。当协调的副本的整个工作负载中有大量的屏障事务时,使用大量的线程实际上会降低副本的性能。
To maintain high performance when large numbers of barrier transactions are expected, you can do the following:
-
Reduce the number of active threads in the group. This reduces the overall number of commits that Replicat performs.
-
Move the tables that account for the majority of the barrier transactions, and any tables with which they have dependencies, to a separate coordinated Replicat group that has a small number of threads. Keep the tables that have minimal barrier transactions in the original Replicat group with the higher number of threads, so that parallel performance is maintained without interruption by barrier transactions.
-
(Oracle RAC) In a new Replicat configuration, you can increase the
PCTFREEattribute of the Replicat checkpoint table. However, this must be done before Replicat is started for the first time. The recommended value ofPCTFREEis 90.
18.7.2 Applying Similar SQL Statements in Arrays
使用BATCHSQL参数来提高Replicat的性能。BATCHSQL导致Replicat将类似的SQL语句组织成数组,并以更快的速度应用它们。在正常模式下,Replicat一次应用一条SQL语句。
When Replicat is in BATCHSQL mode, smaller row changes will show a higher gain in performance than larger row changes. At 100 bytes of data per row change, BATCHSQL has been known to improve the performance of Replicat by up to 300 percent, but actual performance benefits will vary, depending on the mix of operations. At around 5,000 bytes of data per row change, the benefits of using BATCHSQL diminish.
The gathering of SQL statements into batches improves efficiency but also consumes memory. To maintain optimum performance, use the following BATCHSQL options:
BATCHESPERQUEUE
BYTESPERQUEUE
OPSPERBATCH
OPSPERQUEUE
As a benchmark for setting values, assume that a batch of 1,000 SQL statements at 500 bytes each would require less than 10 megabytes of memory.
You can use BATCHSQL with the BATCHTRANSOPS option to tune array sizing. BATCHTRANSOPS controls the maximum number of batch operations that can be grouped into a transaction before requiring a commit. The default for non-integrated Replicat is 1000. The default for integrated Replicat is 50. If there are many wait dependencies when using integrated Replicat, try reducing the value of BATCHTRANSOPS. To determine the number of wait dependencies, view the TOTAL_WAIT_DEPS column of the V$GG_APPLY_COORDINATOR database view in the Oracle database.
See Reference for Oracle GoldenGate for additional usage considerations and syntax.
18.7.3 Preventing Full Table Scans in the Absence of Keys
If a target table does not have a primary key, a unique key, or a unique index, Replicat uses all of the columns to build its WHERE clause. This is, essentially, a full table scan.
To make row selection more efficient, use a KEYCOLS clause in the TABLE and MAP statements to identify one or more columns as unique. Replicat will use the specified columns as a key. The following example shows a KEYCOLS clause in a TABLE statement:
TABLE hr.emp, KEYCOLS (FIRST_NAME, LAST_NAME, DOB, ID_NO);
For usage guidelines and syntax, see the TABLE and MAP parameters in Reference for Oracle GoldenGate.
18.7.4 Splitting Large Transactions
If the target database cannot handle large transactions from the source database, you can split them into a series of smaller ones by using the Replicat parameter MAXTRANSOPS. See Reference for Oracle GoldenGate for more information.
Note:
MAXTRANSOPS is not valid for an integrated Replicat on an Oracle database system.
18.7.5 Adjusting Open Cursors
The Replicat process maintains cursors for cached SQL statements and for SQLEXEC operations. Without enough cursors, Replicat must age more statements. By default, Replicat maintains as many cursors as allowed by the MAXSQLSTATEMENTS parameter. You might find that the value of this parameter needs to be increased. If so, you might also need to adjust the maximum number of open cursors that are permitted by the database. See Reference for Oracle GoldenGate for more information.
18.7.6 Improving Update Speed
Excessive block fragmentation causes Replicat to apply SQL statements at a slower than normal speed. Reorganize heavily fragmented tables, and then stop and start Replicat to register the new object ID.
18.7.7 Set a Replicat Transaction Timeout
使用TRANSACTIONTIMEOUT参数可以防止未提交的Replicat目标事务持有目标数据库上的锁并消耗不必要的资源。您可以更改此参数的值,以便Replicat可以在目标上的现有应用程序超时和其他数据库需求范围内工作。
TRANSACTIONTIMEOUT limits the amount of time that Replicat can hold a target transaction open if it has not received the end-of-transaction record for the last source transaction in that transaction. By default, Replicat groups multiple source transactions into one target transaction to improve performance, but it will not commit a partial source transaction and will wait indefinitely for that last record. The Replicat parameter GROUPTRANSOPS controls the minimum size of a grouped target transaction.
The following events could last long enough to trigger TRANSACTIONTIMEOUT:
-
Network problems prevent trail data from being delivered to the target system.
-
Running out of disk space on any system, preventing trail data from being written.
-
Collector abends (a rare event).
-
Extract abends or is terminated in the middle of writing records for a transaction.
-
An Extract data pump abends or is terminated.
-
There is a source system failure, such as a power outage or system crash.
See Reference for Oracle GoldenGate for more information.

















 2647
2647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









