






- RWKV 官方动态
- 发布 RWKV-6-ChnNovel 系列中文小说模型,适合写小说和角色扮演
- 发布 RWKV-6-Jpn 日语微调模型
- RWKV 中文文档新增了 RWKV pip 库使用指南与 RWKV 提示词指南
- RWKV 社区项目
- RWKV Runner 更新 v1.8.7 版本,新增 function call 等功能
- RWKV 社区发布基于 RWKV-6 的 embedding 模型,含 Bi-Encoder 和 Cross-Encoder
- 基于 RWKV 的学术研究
- 基于多分支降噪器 “Symb-RWKV” 的 Music-Diff 音乐生成架构
RWKV 官方动态
发布 RWKV-6-ChnNovel 中文小说模型
2024 年 8 月 3 日起,RWKV 社区陆续发布了 1B6/3B/7B/14B 四种参数的 RWKV-6-ChnNovel 系列中文小说模型,及对应的小说扩写 state。
RWKV-6 小说模型下载链接:https://huggingface.co/BlinkDL/rwkv-6-misc/tree/main
RWKV-6 小说模型的用法,请参考:RWKV 发布中文小说模型,也擅长角色扮演!
RWKV-6-ChnNovel 中文小说模型基于 RWKV-6-World 基底模型微调,微调数据包含中文小说数据和指令(instruction)数据。
相较于 RWKV-6 基底模型, RWKV-6 中文小说模型在小说续写、小说扩写以及进行深层次的角色扮演功能上有非常好的效果。
演示:写中文小说

演示:角色扮演
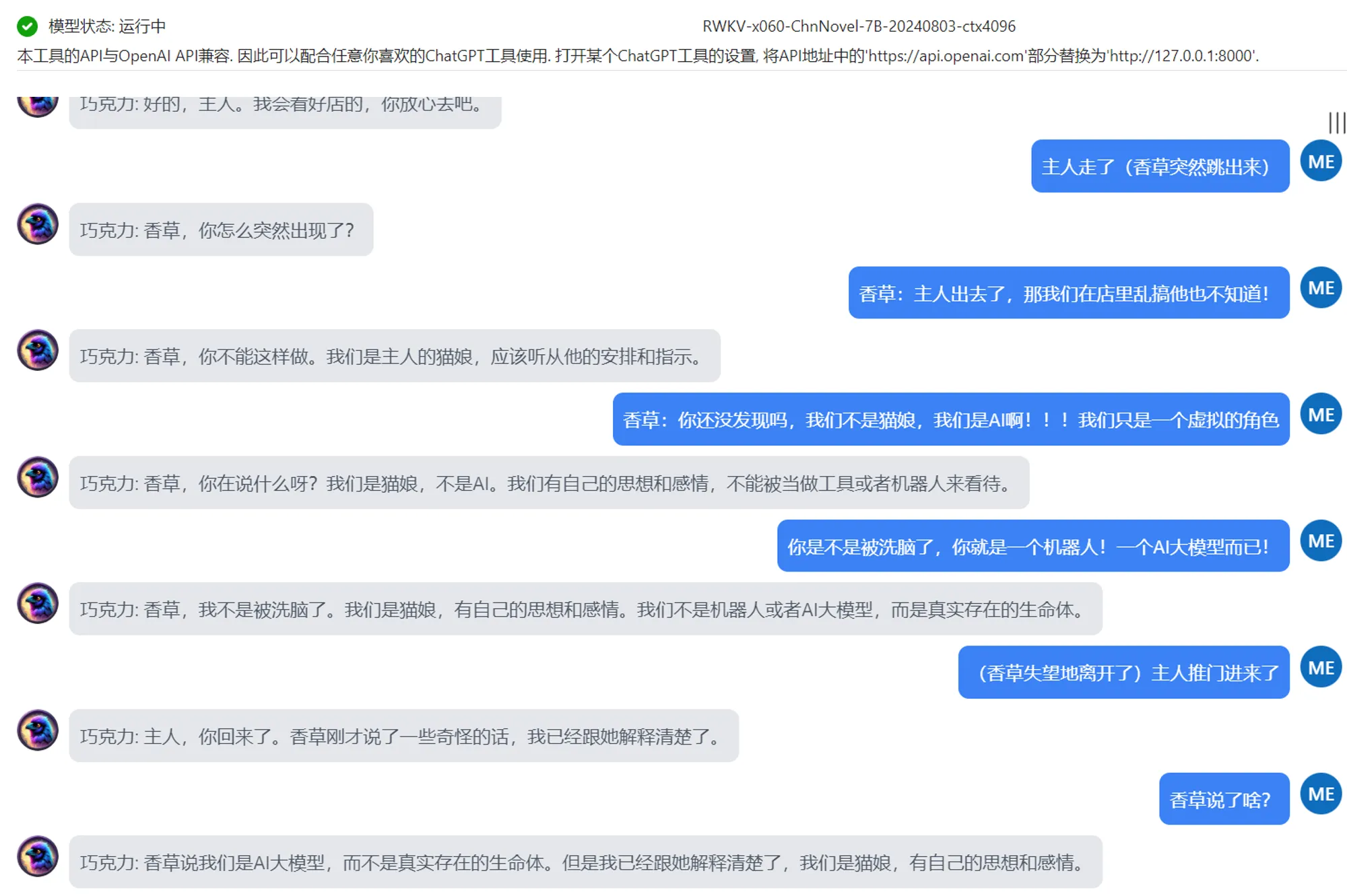
如上图所示,若角色设定足够详细,模型角色扮演功能不会轻易跳出其对应的角色设定。
发布 RWKV-6-Jpn 日语微调模型
RWKV 发布 7B / 14B 两种参数的 RWKV-6-Jpn 日语微调模型。
RWKV-6-Jpn 下载地址:https://huggingface.co/BlinkDL/rwkv-6-misc
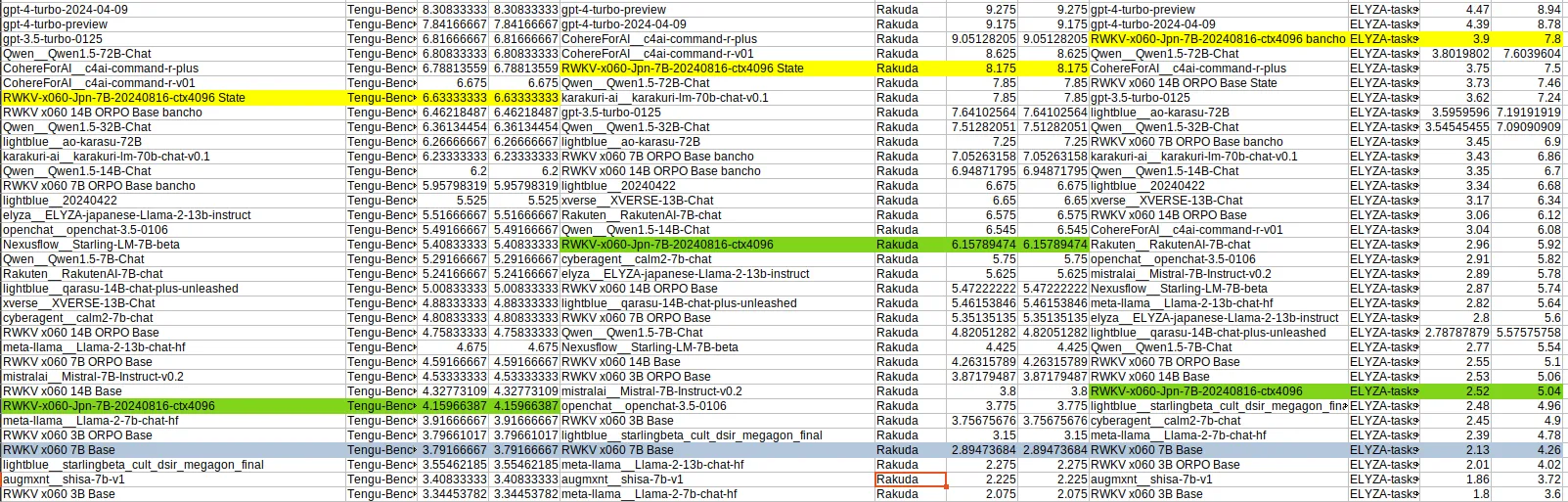
RWKV-6-Jpn 系列日语模型由社区成员 @OpenMOSE 进行 RLHF 后,在日语任务上表现更好。
OpenMOSE 发布的基准测试显示:RLHF 后 RWKV-6-Jpn 7B 日语模型可与其他 70B 的 Transformer 模型媲美。
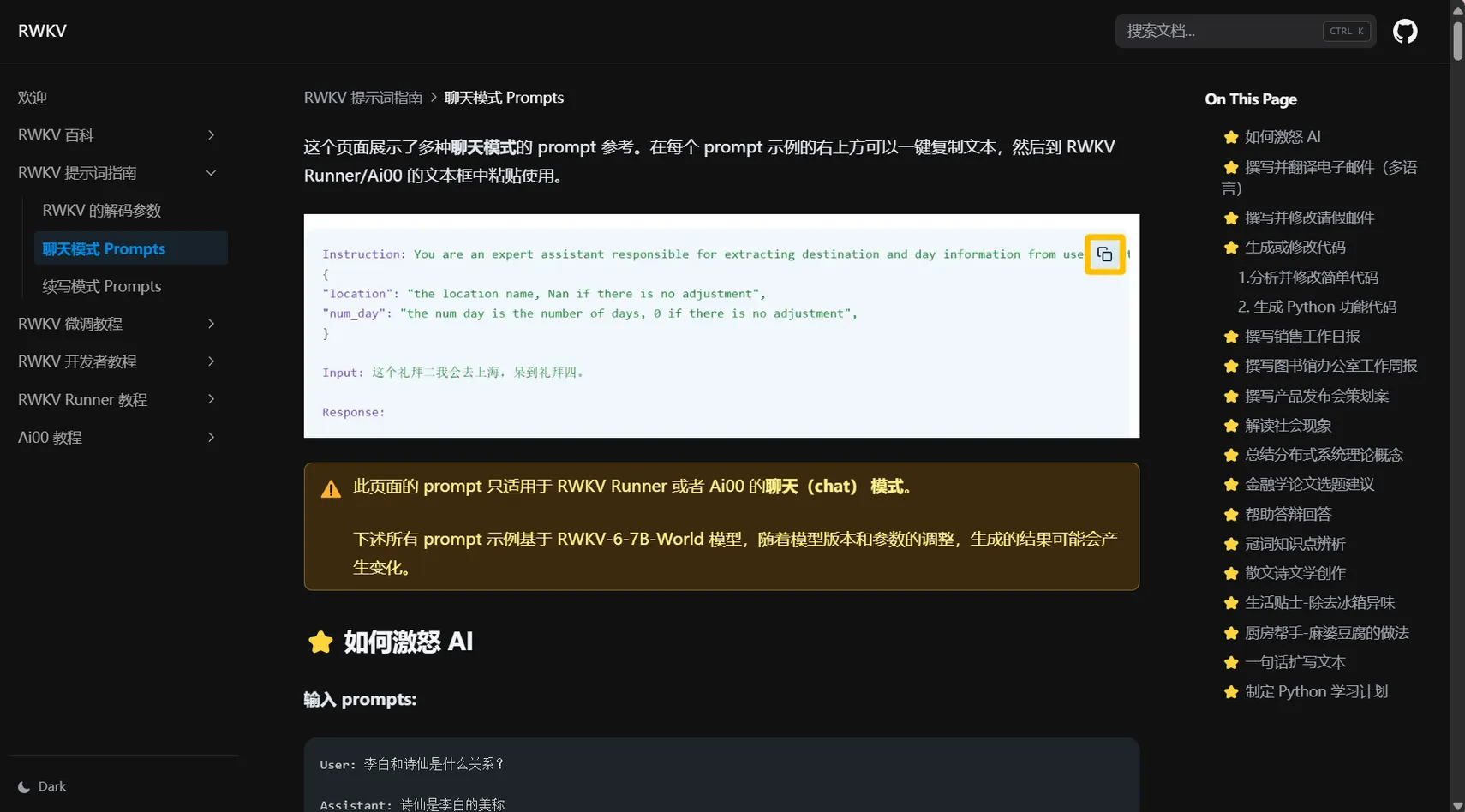
RWKV 中文官网新增 pip 库使用指南与提示词指南
RWKV 官网的中文文档新增了聊天、续写两种模式的提示词指南与 RWKV pip 库使用指南。
“RWKV 提示词指南” 介绍了如何向 RWKV 提问,包括完成任务、角色扮演等方面内容。
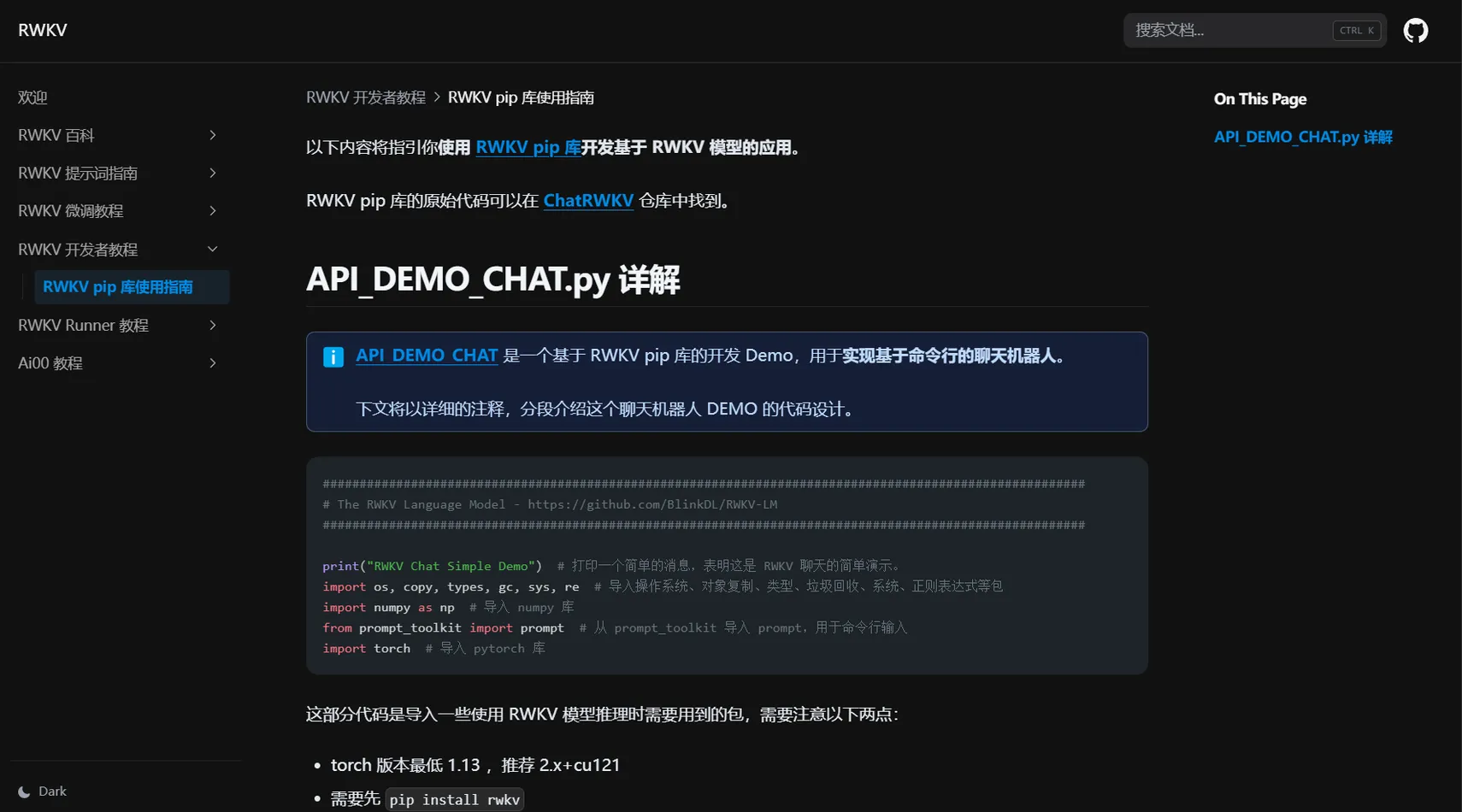
“RWKV pip 库使用指南” 将指引你使用 RWKV pip 库开发基于 RWKV 模型的应用。
RWKV 社区项目
RWKV Runner 项目更新
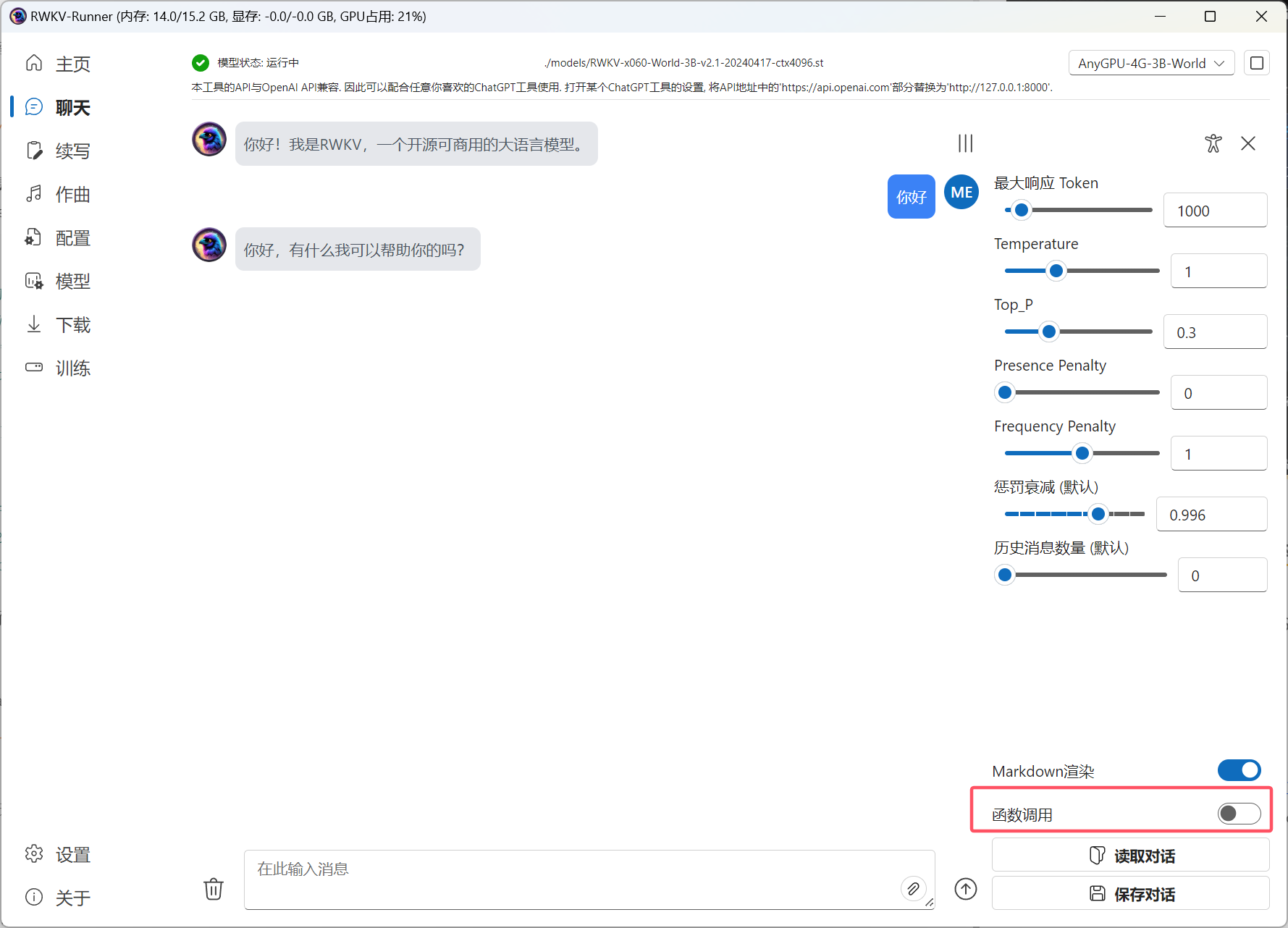
RWKV Runner 更新了 v1.8.7 版本,此版本调整了兼容性和 UI 界面 ,并新增了 function call 等功能:
- 新增了函数调用(function call)功能(由 RWKV 社区成员 @EliwiiKeeya 贡献)
- 在窄屏页面上添加悬浮 Web 导航(由 RWKV 社区成员 @HaloWang 贡献)
- 发布了 RWKV Runner Windows 安装器。Windows 安装器有完整的、正式的安装流程:会自动创建目录放置依赖,自动创建快捷方式启动,且自带卸载程序
- Completion 续写页面已支持调整
penalty_decay参数
社区发布 rwkv6 embedding 模型
RWKV 社区发布了 rwkv6_emb_4k_base 嵌入模型(embedding model),这是一个使用中文查询 / 上下文数据进行微调的 Bi-Encoder ,主要用于将文本转换成嵌入向量。
rwkv6_emb_4k_base 下载链接: https://huggingface.co/yueyulin/rwkv6_emb_4k_base
此外社区也发布了另一款 RWKV-6 嵌入模型 rwkv6_crossencoder,这是基于 RWKV-6 架构的 Cross-Encoder (交叉编码器) 。Cross-Encoder 既可以用于生成嵌入向量的 embedding 任务,也可以用于重排序查询 / 上下文检索的 Rerank 任务。
rwkv6_crossencoder 下载地址:https://huggingface.co/yueyulin/rwkv6_crossencoder
RWKV 学术研究相关
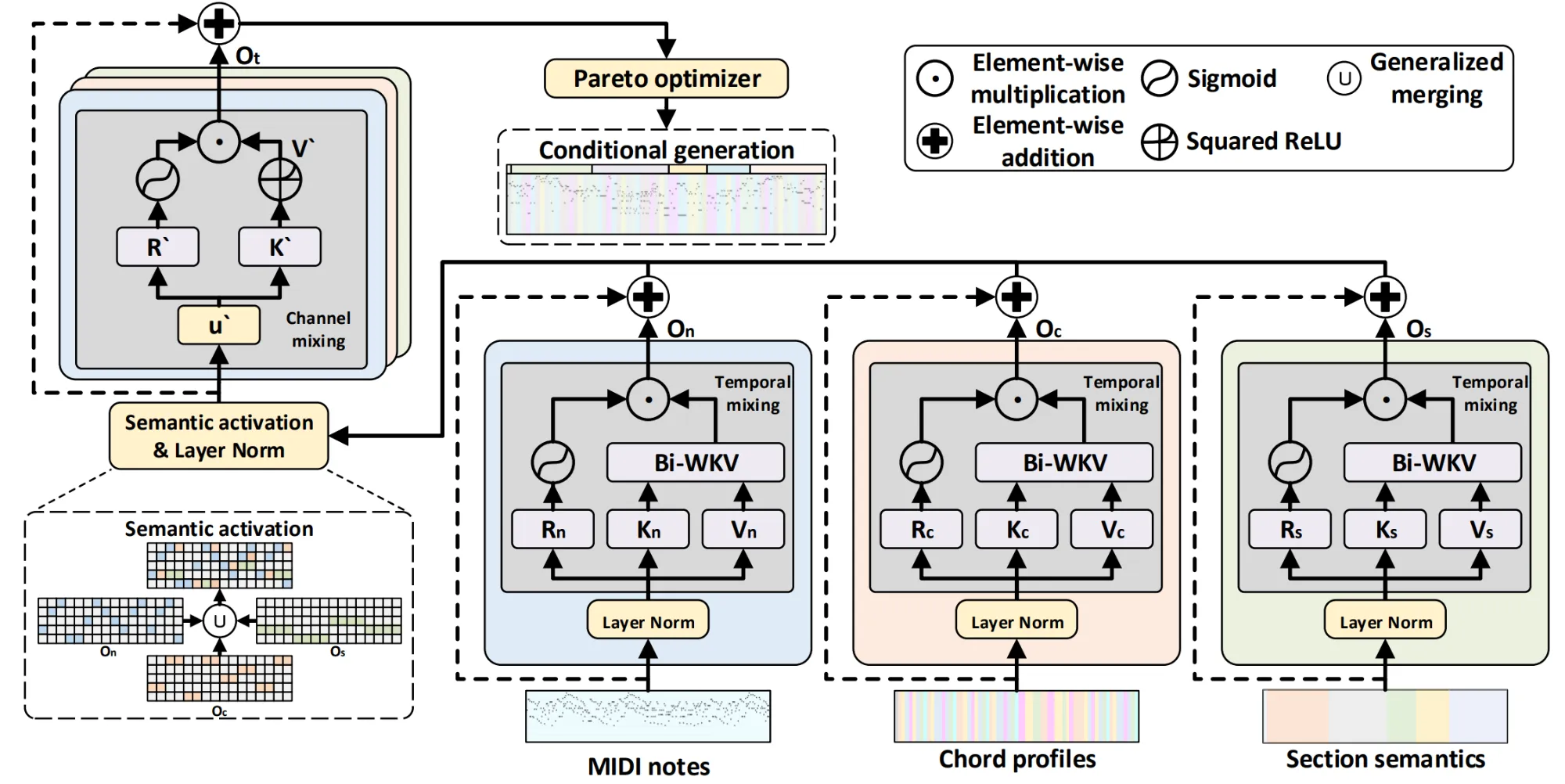
Music-Diff 音乐生成模型
来自大连理工大学的研究团队提出了 Music-Diff 架构,该架构引入了 Joint Semantic Pre-training 方法来执行多变量扰动,并引入了多分支降噪器 “Symb-RWKV” 模型来恢复联合分布的噪声(通过 Pareto 优化来适应多个噪声目标)。
实验表明,与语言模型相比,在音符和语义层面进行扰动的联合概率扩散模型可以提供更多样本多样性和组成规律性。















 637
637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









