









TL;DR
- 场景:评估Gemini 3 Pro在2025年重登LMSYS/Arena等榜单的技术与体验成因。
- 结论:稀疏MoE、百万级上下文、原生多模态与可控推理深度共同抬升“难题场景”得分与主观对话体验。
- 产出:一页式摘要 辅助读者快速复现与规避坑点。

Gemini 3 Pro重回榜首的原因
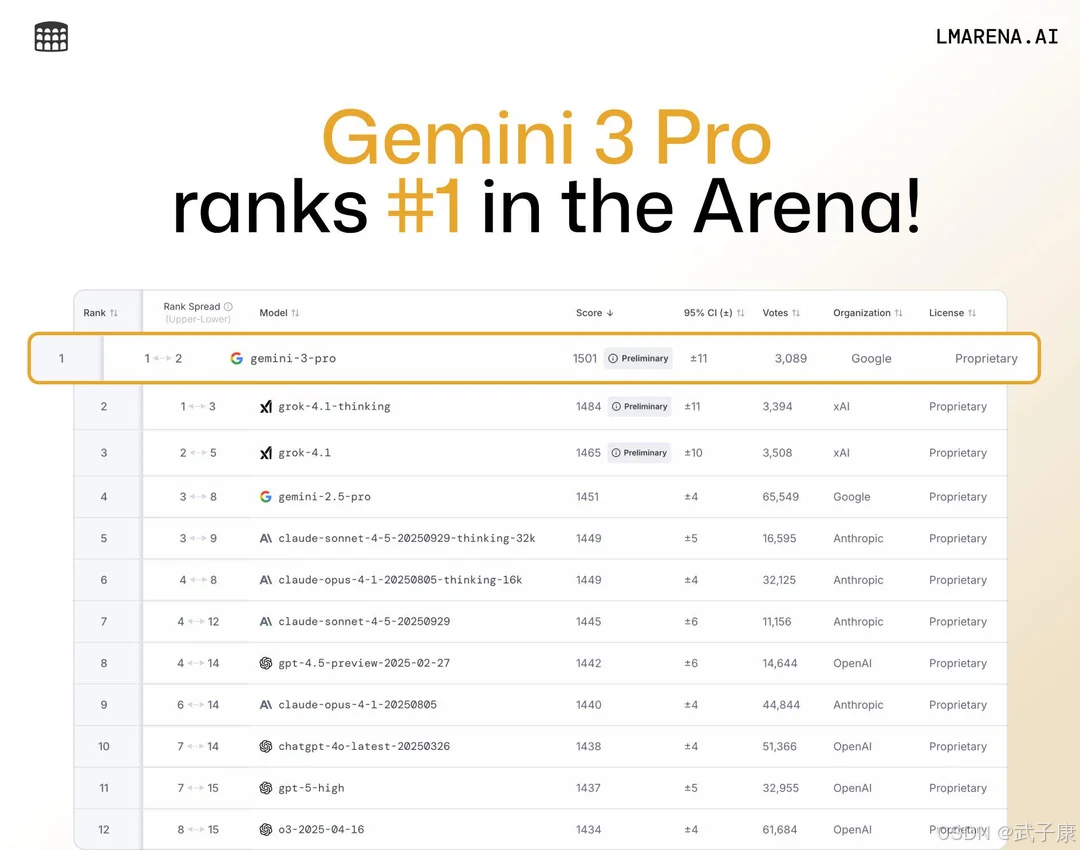
模型更新日志与架构改进
2025年11月18日,Google DeepMind发布了Gemini 3.0 Pro版本并将其加入LMSYS Arena排行榜后,短时间内该模型就在几乎所有榜单类别中登顶。这次重大更新带来了多方面的架构改进和功能增强。

大模型架构
Gemini 3 Pro采用了万亿规模的稀疏MoE(Mixture-of-Experts)架构,通过路由仅激活部分专家网络参与推理,从而拥有极高参数量但推理开销可控。相比上一代的密集Transformer,这种架构实现了性能与成本的平衡,并为模型提供了更大的表示能力。
超长上下文
Gemini 3 Pro支持最长约100万Token的上下文窗口,可以一次性读入数十万字的文本(相当于多本书的内容)并生成最长6.4万Token的连续输出。这一突破性提升(上一代Gemini 2仅支持数万Token)使模型能够在不借助复杂检索算法的情况下处理长对话和长文档。
原生多模态
与一些将图像编码器外挂到语言模型上的做法不同,Gemini 3 Pro的核心Transformer架构原生支持多模态输入,将文本、图像、音频、视频帧、PDF等视作“一等公民”直接处理。这种设计使模型在处理跨模态推理任务时效果更佳,例如同时理解题干文字和配套示意图、UI界面截图和操作指令等场景。原生多模态也让Gemini 3在视觉理解和跨模态推理上胜过主要竞品 。
推理引擎与思维控制
新版模型引入了 “thinking_level”推理深度控制参数,以及即将推出的“Deep Think” 模式。
开发者可以通过调整thinking_level在每次请求中按需权衡速度与推理深度;Deep Think模式则会在遇到极困难问题时动态投入额外计算资源,让模型探索多种解题路径后再作答。
内测显示,启用Deep Think可让模型在超高难度测试(如Humanity’s Last Exam和ARC-AGI-2挑战)上的得分相对基础模式再提升数个百分点。这些改进表明新版推理引擎在系统提示词和解题流程上进行了优化,使模型遇到复杂任务时更擅长“慢思考”而非浅尝辄止。
系统提示与响应风格
在对话系统方面,Google针对Gemini 3 Pro调整了隐藏的系统提示策略,改善了回答风格。模型回复变得更加简洁直接,摒弃了过度的客套与讨好,能够给出具有洞见且直截了当的回答。
官方表示Gemini 3会“告诉你需要听的,而不只是你想听的”,强调输出内容的真实价值。这暗示新版模型在对话人格上做了微调,使其更像一个真诚的思想伙伴,而非一味迎合用户。
此外,Gemini 3更善于领会用户意图和上下文细节,可用更少的提示就明白需求。这些变化很可能源于系统提示词和对话策略的改进,使模型对上下文理解力增强、废话客套减少,从而提升用户实际对话体验。
暂时小结
综上,Gemini 3 Pro在底层架构上进行了重大升级,包括大幅增加模型容量(稀疏专家)、拓展上下文长度,以及深度融合多模态处理,同时在推理策略和系统提示上也做出了优化调整。这些更新为其性能飞跃和用户体验提升奠定了基础,也是其重回排行榜榜首的技术原因。
基准任务性能的提升
新版Gemini在各类基准评测中表现出显著提升,在众多学术和能力测试上重新夺回领先地位。特别是在一些具有挑战性的高难度基准上,Gemini 3 Pro的成绩远超前代和主要竞争模型,证明了更新带来的实质效果。


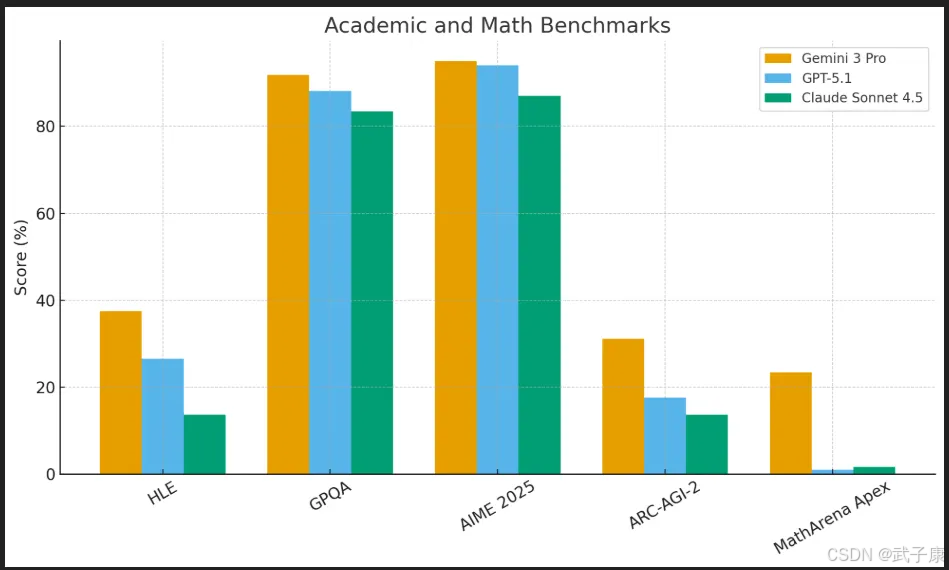
通用智力与推理
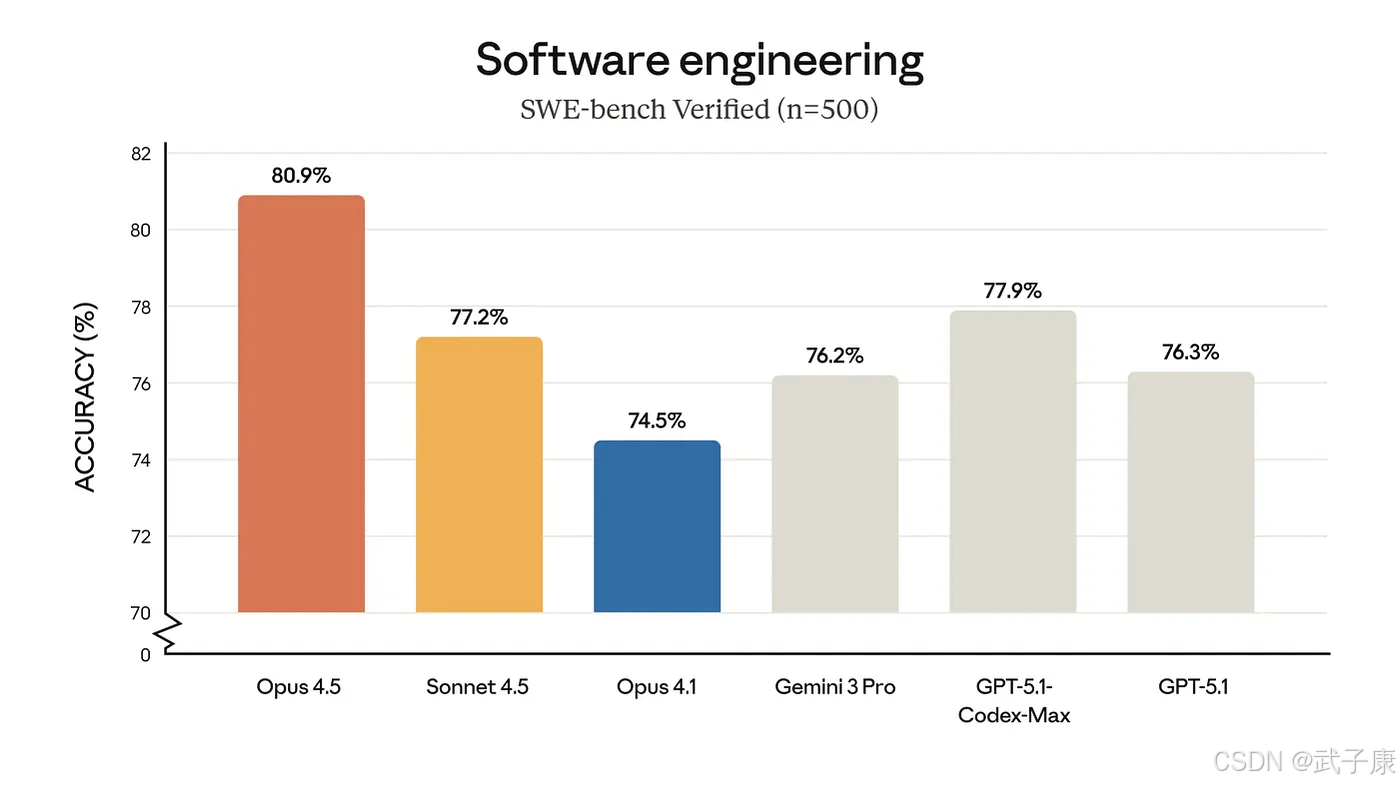
在被称为“大模型终极考验”的Humanity’s Last Exam (HLE)上,Gemini 3 Pro在不开工具辅助的情况下取得约37–38%的准确率,而OpenAI最新的GPT-5.1仅为中段20%出头,Anthropic新模型Claude Sonnet系列甚至只有十几%。这意味着Gemini在复杂学术问答和综合推理上实现了一次大幅跃升,拉开了与竞品的差距。
同时在Massive Multitask Language Understanding (MMLU)等知识测验上,Gemini 3也保持业界最高水平,延续了Gemini 1.5在2024年初创造的SOTA成绩(Gemini 1.5曾创下MMLU和GSM8K的当时最高分)。
数学和奥赛难题
在数学推理方面,Gemini 3在新推出的MathArena Apex高难度数学竞赛基准上取得23.4%的正确率。别小看这个数字,大多数模型在此“终极魔王关”上几乎挂零——GPT-5.1和Claude的得分仅约1–2%。
Gemini 3足足比上一代和竞品高出20多个百分点,在奥林匹克竞赛级别的问题上实现了质的突破。虽然这不意味着模型已经媲美顶尖人类数学家,但确实标志着AI在复杂符号推理和多步骤推导任务上迈进了一大步。在常见的数学基准如GSM8K(小学算术应用题)上,Gemini系列自上一代起就已达到接近满分水准;此次更新则侧重攻克更复杂的竞赛难题。
专业考试与常识
Gemini 3 Pro还在诸如ARC(AI复杂推理挑战)等基准上表现优异。例如在难度最高的ARC-AGI-2测试中,Gemini 3取得了31.1%的成绩,几乎是此前SOTA水平的两倍(使用工具代码执行验证后,Deep Think模式甚至达到45.1%)。
相比之下,其他模型普遍远低于这一水准。这说明Gemini 3在解决全新挑战性问题上的能力有了突破性增强。同样,在Big-Bench大型开放问答集合中,Gemini 3 Pro在约一半子任务上拔得头筹(人工智能分析平台的“智能指数”显示其领先于一众模型)。
科学与专业问答
在研究级科学问答基准GPQA Diamond(研究生难度的科学题库)上,Gemini 3 Pro的正确率约为92%,明显领先GPT-5.1的高80%水平,以及Anthropic最佳模型低80%的成绩。如此高分表明其专业知识掌握和推理应用已非常扎实。此外在常识推理(如PIQA物理常识测试)等方面,新模型也保持了约90%以上的正确率,与主要闭源模型旗鼓相当。
多模态理解
得益于原生多模态架构,Gemini 3 Pro在跨模态基准上优势明显。在MMMU-Pro综合多模态理解测试中,Gemini 3得分约81%,超出GPT-5.1的中70%水平,略高于Anthropic最强模型的成绩。
在Video-MMMU(长视频理解)中,Gemini 3得分约87–88%,展示了对长时序视频内容的强大理解能力。最突出的例子是ScreenSpot-Pro(界面截图理解)测试,Gemini 3 Pro取得 72.7% 的高分,而GPT-5.1在该测试中几乎“看不懂”图形界面,仅是个位数百分比的水平 。即使是专门训练用于计算机界面操作的模型也远落后于Gemini。
这一项目标志着Gemini 3真正掌握了“看图操作”的能力——能够读取软件截图中的菜单、对话框、表格等UI元素并做出正确操作。也正因此,Google才有信心将其直接整合进新版搜索的“AI模式”和Antigravity浏览器自动化工作流中,让模型直接“看界面点按钮”完成任务。
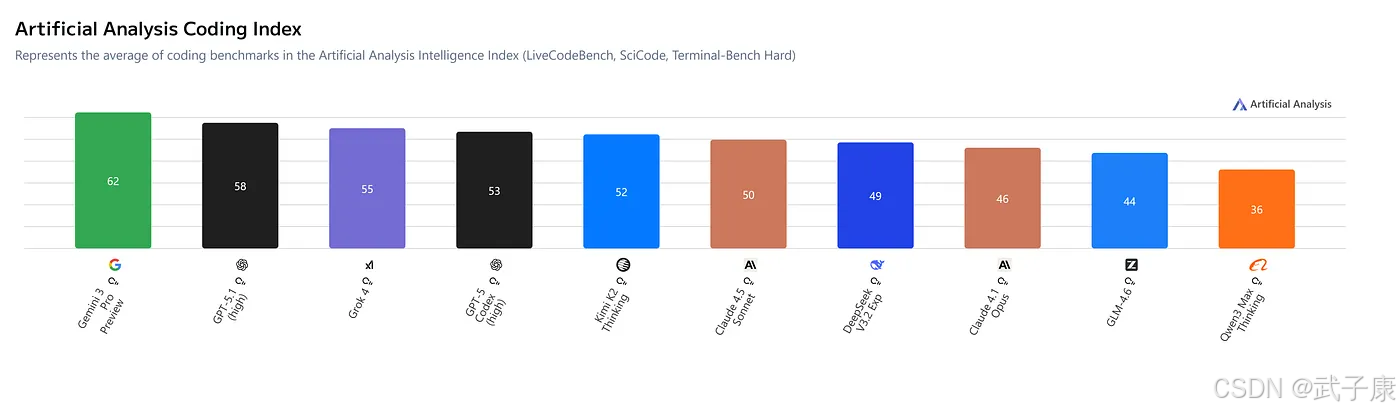
代码与工具使用
在代码任务上,Gemini 3 Pro在基础的编码基准上已与其他顶级模型旗鼓相当:例如在主流编程评测(如HumanEval或GitHub问题集的pass@1)上,Gemini 3 Pro、GPT-5.1和Claude Opus 4.1都集中在约70%中后段,彼此差距只在百分点级别。但在更高级的“AI编程”任务上,Gemini的优势开始体现。
LiveCodeBench
(实时编程对战,类似Codeforces竞赛)中,Gemini 3 Pro的Elo分约2439,显著高于GPT-5.1的约2240,而Claude更是远远落后。
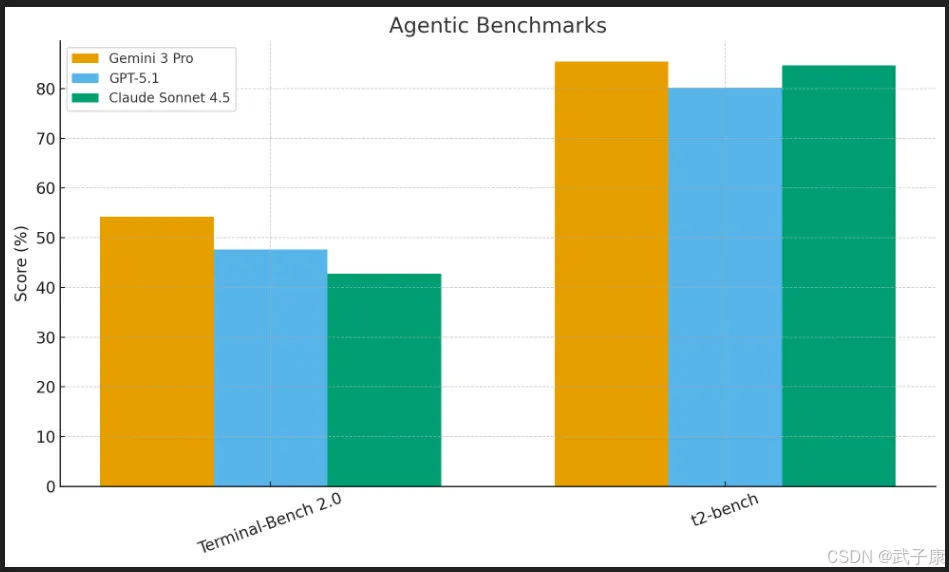
- Terminal-Bench 2.0(在仿真终端中完成任务)中,Gemini 3得分50%+(中高50%),领先GPT-5.1的高40%和Claude低40%的水平,说明其作为“命令行智能体”比仅会产出代码的模型更加胜任。
- Vending-Bench 2(自动售货机模拟长期决策)中,Gemini 3在模拟经营一整年的环境下最终收益远高于其他前沿模型:其决策规划稳定且回报更高,没有像其它模型那样操作一段时间后策略走偏。这一点体现了Gemini在长程规划任务上的突出能力,这也正是其名为“Antigravity”的新代理式IDE所要充分利用的。
暂时小结
上述基准测试结果清晰表明:Gemini 3 Pro在推理、知识问答、代码、多模态等各方面的能力均有全面飞跃。尤其在难度最高的一批挑战上,远超以往模型的成绩证明了此次升级的含金量。
社区评价称这些数据“经得起检验”,并非仅是营销噱头。可以说,卓越的评测表现是Gemini 3重回排行榜首位最直接的原因。
社区反馈与对话体验改进
模型性能提升的同时,用户体验和社区反馈也显示出积极变化。许多率先体验Gemini 3 Pro的开发者和用户发现,与前代或其他模型相比,新版本在对话交互中更加“聪明”和“贴心”。
更强的上下文把握
Gemini 3据称“更能读懂空气”。它对于对话中的语境和用户意图理解得更透彻,往往不需要用户反复澄清就能抓住真正需求。这意味着在实际交流中,Gemini 3能更好地明白隐含的意思或之前对话提及的内容,从而少问反问句,直接给出所需信息。
长达百万字符的记忆窗口更是保证了即便对话持续很久,模型也几乎不会遗忘早先的细节。社区用户反馈,Gemini 3在长对话中的一致性和连贯性明显优于以往模型——不再像一些模型那样聊着聊着就“失忆”或自相矛盾了。
回答风格和可信度
很多用户注意到,Gemini 3 Pro的回答风格相比之前有所转变。它更加直截了当,很少给出那种漫长而空洞的客套前缀或重复确认,而是开门见山进入正题。官方博客也强调这一点,称Gemini 3摒弃了陈词滥调和恭维,提供的是用户真正需要听的内容,而不仅仅是迎合用户想听的话。这种风格转变在实际使用中提升了效率和可信度——用户感觉与其交流更像是在与一个有见地的专家对话,而非一个只会讨好迁就的助手。
创造力与实用性并重
社区测试者报告,Gemini 3在保持理性和准确的同时,创造力也不逊色。在开放式写作、头脑风暴等场景下,新模型能够提出新颖有趣的想法,同时又有足够的逻辑支撑避免离题。
例如,有用户让多个模型就某个科研创意进行讨论,发现Gemini 3既能跳出现有框架提出大胆设想,又能清晰解释背后的原理和可行性,这种思想火花与严谨推理并存的对话体验广受好评。
编程和工具辅助对话
对于开发者社区来说,Gemini 3 Pro带来的直接惊喜是对代码和工具更高的熟练度。许多用户反馈它在对话中能更加主动地使用工具帮助完成任务。例如在Google的AI Studio环境中,Gemini 3可以根据自然语言指令生成交互式前端代码,甚至自动调用外部API来丰富结果。
有用户让它“设计一个霓虹风格的太空主题仪表盘界面”,Gemini不仅输出了HTML/CSS/JS代码,还配以暗色调星云背景,完成度很高。这种 “随心涂抹,瞬间出图”的创造体验受到创意工作者的热议。此外,在集成开发环境Antigravity中,Gemini 3能与绑定的浏览器、终端一起工作,自动执行多步骤操作,这种代理式对话 让用户感觉仿佛有一个真正在帮忙敲代码、跑命令的AI搭档。
安全和礼貌
经过更严格的对齐训练,Gemini 3在保持礼貌和安全的同时变得更加果断。它依然会遵循道德和使用政策,对不当请求礼貌拒绝,但不会过度避讳正当内容。由于引入了AI反馈和大规模红队测试(推测自Google以往做法),模型对敏感话题的处理也更加成熟。
例如,有用户尝试一些潜在的“提示攻击”,发现Gemini 3比过去的版本更难被绕过安全限制,同时在正常请求下几乎不会出现无故的内容审查或莫名其妙的拒答。这种稳健性让很多用户表示信赖感提升。
内部评估显示,与前代相比,Gemini 3的不恰当输出率降低了约40%——社区对此给予了积极评价,因为模型变得既更安全又不影响正常使用。
暂时小结
总体而言,Gemini 3 Pro在对话体验上的进步是全方位的:理解更深刻、响应更高效、风格更专业可信,同时还能利用工具和编码能力拓展对话的边界。
社区用户的积极反馈和改进体验,进一步巩固了它在排行榜中的领先地位——毕竟排行榜(如Chatbot Arena)的胜负很大程度取决于人类对比选择,而Gemini 3赢得了更多用户的青睐 。
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新… 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接


















 1414
1414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











