







1. 环境准备
(1)运行在java编程的IEDA软件上(WINDOWS环境)
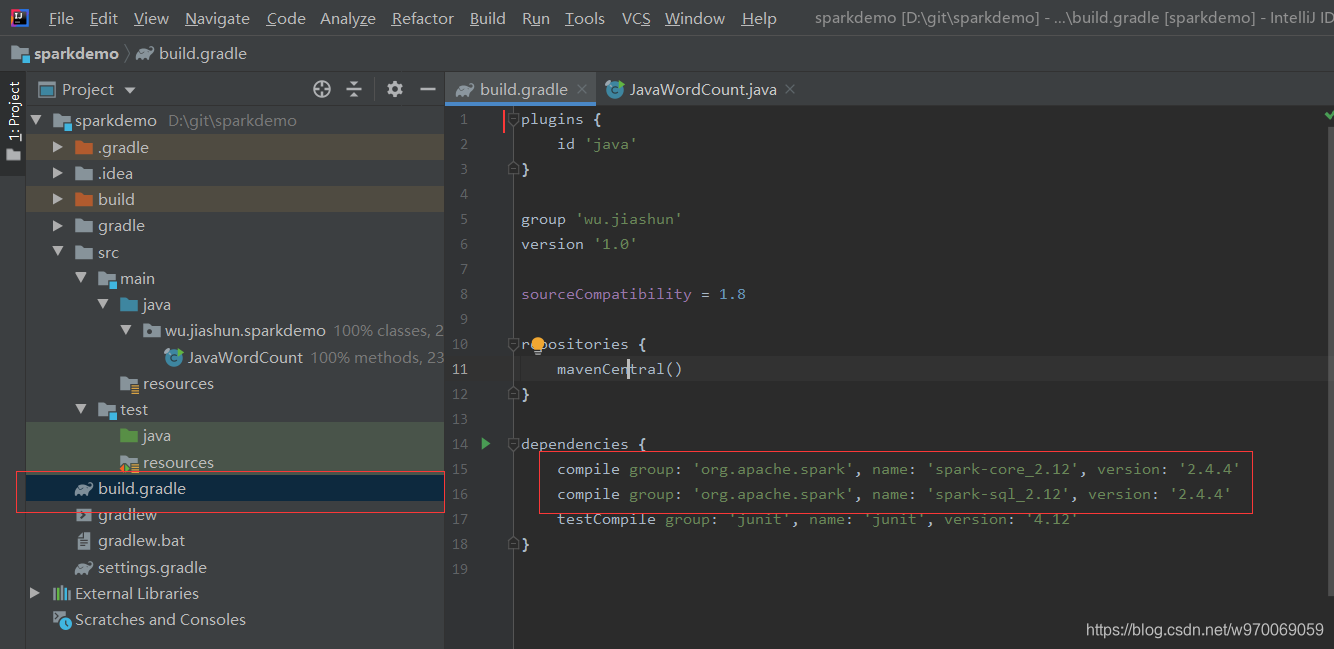
(2)新建好gradle工程后,在build.gradle文件下新增外部依赖
compile group: 'org.apache.spark', name: 'spark-sql_2.12', version: '2.4.4'
如图所示
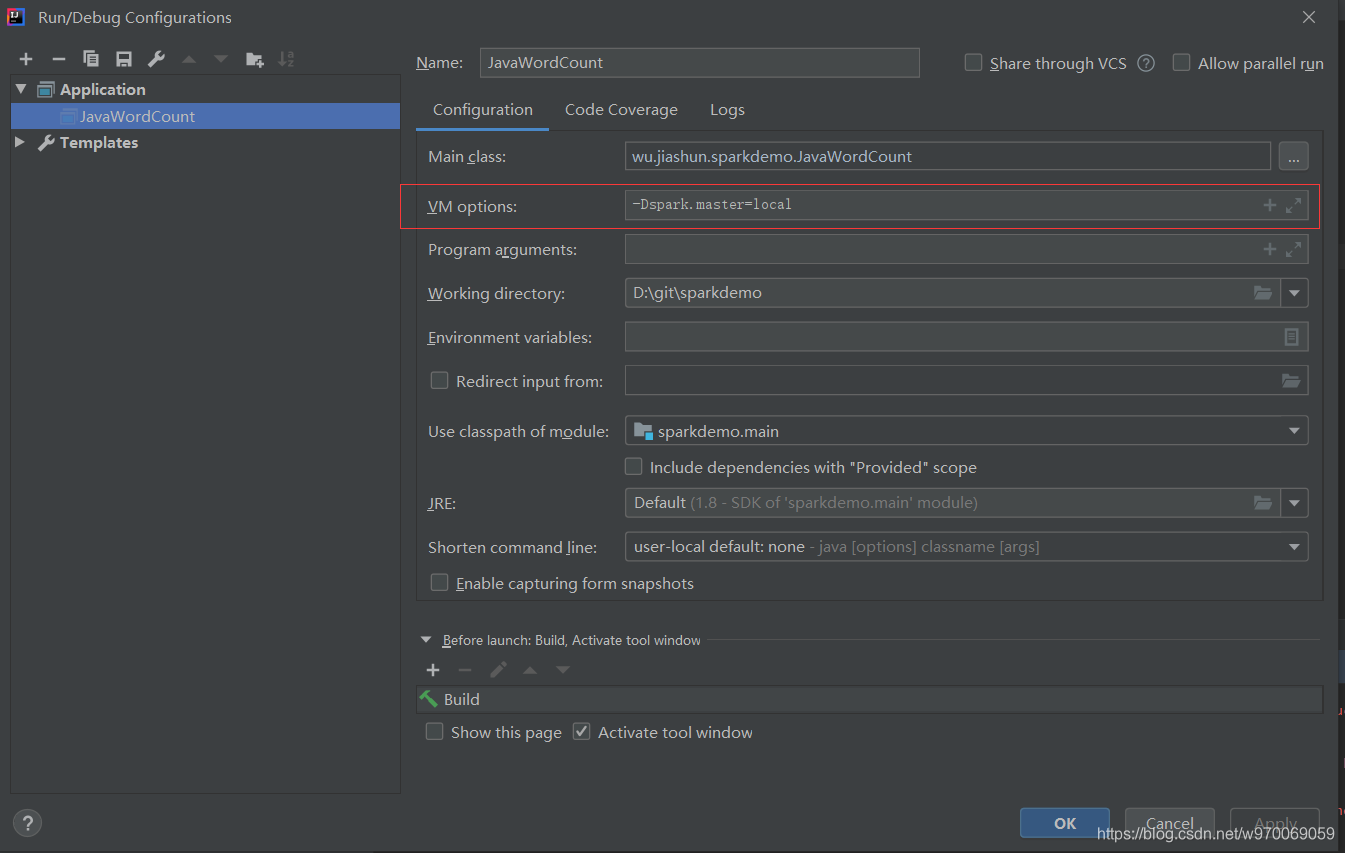
(3)配置
如图所示,在IDEA运行项的Configuration中的VM opthion 增加
“-Dspark.master=local”
2. 重点代码部分
package wu.jiashun.sparkdemo;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
/**
* @description:
* @auth: wujiashun
* @date: 2019/10/30
*/
public final class JavaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
if (args.length < 1) {
System.err.println("Usage: JavaWordCount <file>");
System.exit(1);
}
SparkSession spark = SparkSession
.builder()
.appName("JavaWordCount")
.getOrCreate(); //启动一个spark控件
JavaRDD<String> lines = spark.read().textFile("file:\\D:\\git\\sparkdemo\\sparkdemo.txt").javaRDD(); //读取操作
JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(SPACE.split(s)).iterator());
// 分词操作
JavaPairRDD<String, Integer> ones = words.mapToPair(s -> new Tuple2<>(s, 1));
// 将单个独立的单词变为键值对,方便后面的处理
JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);
//将键值对中的数字相加
List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?,?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
spark.stop(); //将spark控件停止
}
}
运行此代码,如图所示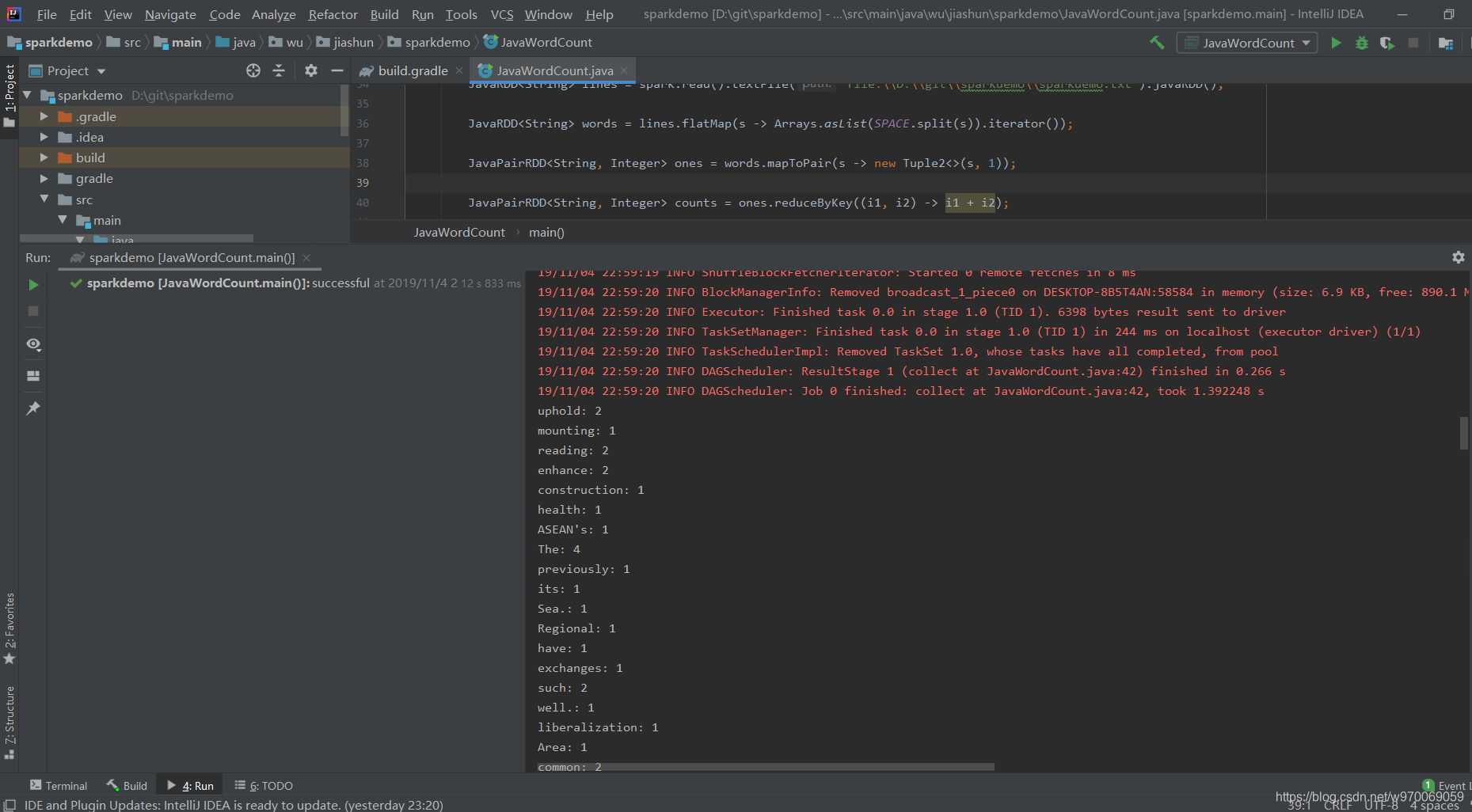
这是我的第一个大数据程序,运行成功了,很激动,希望后面的学习能更加顺利。
P.S. 如果运行出错却在代码里找不到语法问题,大概率是读取路径有问题,检查路径说不定就能排查问题啦。
针对此程序,还有一些不是特别明白的地方,所以后面学习目标:
- 算子和函数的区别
- 每个算子的具体原理,知其所以然














 3979
3979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









