







一、各个小节之间的串联
决策树(多个判定条件的分类问题)–> 如何判定(划分选择)–> 如何优化(剪纸处理)
决策树(多个判定条件的分类问题)–> 数据是连续(连续与缺失值处理)
二、决策树概念
概念:属于分类问题(在用基尼指数的时候,也有回归树)。
组成部分:一颗决策树一般包括一个根节点(样本全集)、若干个内部节点(测试属性)、若干个子节点(决策结果)。算法如下:

返回的判定条件:
- 当前节点包含的样本全部属性属于同一类别,无需划分。
- 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分。(把节点标记为叶节点,类别为样本中类别占比最大的)
- 当前节点包含的样本集合为空,不能划分。
三、划分选择
信息熵:
先说几个概念:
- 熵:一种事务的不确定性
- 信息:消除不确定性的事务,调整对事务发生概率的认识,排除干扰,确定情况。
那么这个事务不确定性怎么去度量呢,应该用什么去衡量?
等概率的情况:
公式 : 
个人理解:对于这个事件的不确定性,等同于与抛多少次硬币所产生的事件不确定。
一般情况:
公式:
前面说到的,信息熵为度量样本集合纯度的一种指标。个人理解为:在这个样本中,具体为某个类别的概率的量化。
那么对于判定类别的信息,应该用什么去衡量?
信息增益: 第一个判定决策树如何划分的家伙。(算法ID3划分属性的依据)
公式:

信息增益的缺点:对可取值数目较多的属性有所偏好。
增益率: (著名的C4.5决策树算法的划分标准):
公式:
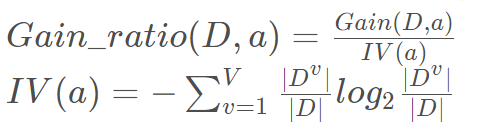
在上图公式中,*IV(a)*表示属性a的”固有值“。特点是,属性a的可能性越多,值越大。
缺点:信息增益率对于类别较少的属性有所偏好,因此,C4.5并不是直接选择增益率作为划分属性的标准,而是使用了一个启发式:
先从候选划分属性中找到信息增益高于平均水平的属性,然后再从中选择增益率最高的。
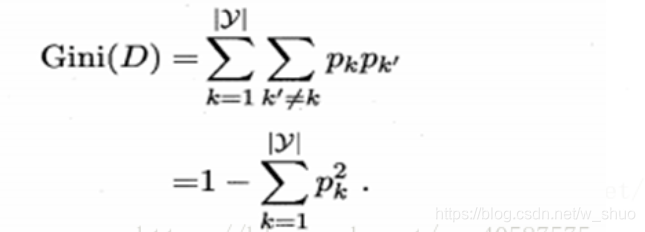
基尼指数: (CART算法采用的划分标准)
直管理解:从数据集中抽取两个样本,类别标记不一致的概率;所以,公式中是平方的形式。同理:Gini(D)越小,数据集D的纯度越高。
公式:
四、剪枝
防止模型过拟合的一种手段
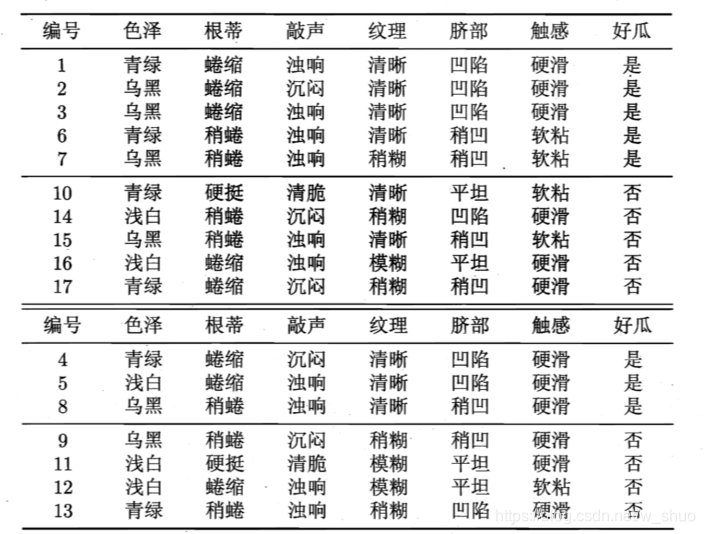
数据集:
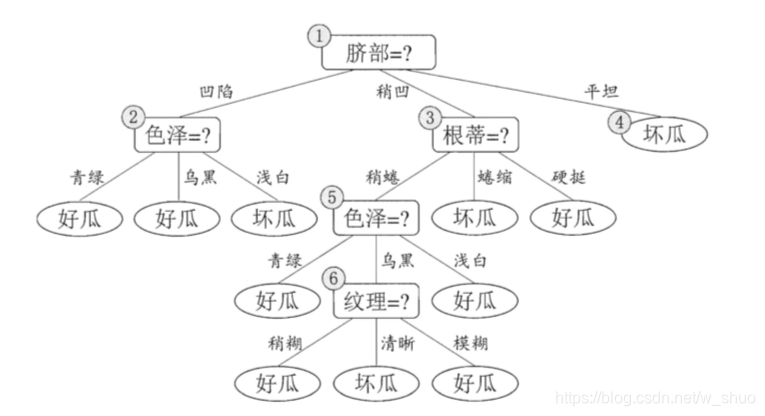
采用信息增益来生成一棵决策树,未剪纸如下:
1)预剪枝
在决策树生成的过程中,对每个节点在划分之前进行估计,若当前节点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶节点。
过程:
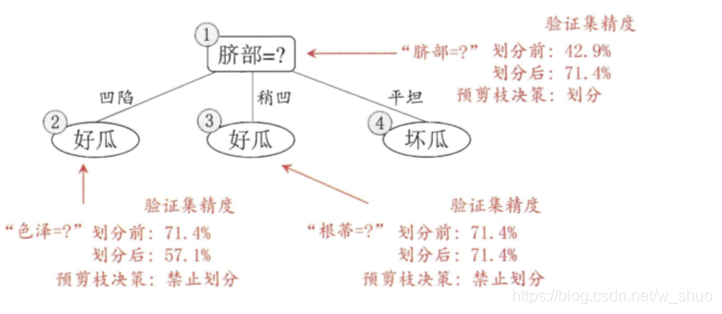
将这个叶结点标记为"好瓜"用表 4.2 的验证集对这个单结点决策树进行评估?则编号为 {4, 5 , 8} 的样例被分类正确?另外 4 个样例分类错误,于是,验证集精度为3/7 x 100% = 42.9%.

优点:降低过拟合的风险,减少了决策树的训练时间开销和测试时间开销。
缺点:可能带来欠拟合的风险
2)后剪枝
从训练集生成一棵完整的决策树,然后自底向上对非叶节点进行检查,若将该结点对应的子树替换为叶节点能带来决策树的泛化能力提升,则将该子树替换为叶节点。
已知下图的精度为42.9%:
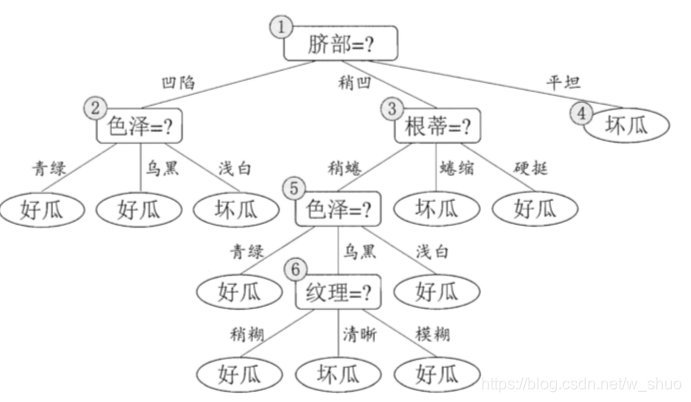
剪枝过程:
1.首先判断结点6,若将其领衔的分支剪除,则相当于 把⑤替换为叶结点.替换后的叶结点包含编号为 {7, 15} 的训练样本,于是?该 叶结点的类别标记为"好瓜",此时决策树的验证集精度提高至 57.1%. 于是,后剪枝策略决定剪枝,如下图所示。
2.考虑节点5,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号为 {6 , 7, 15} 的训练样例,叶结点类别标记为"好瓜’七此时决策树验证集精度仍为 57.1%. 于是,可以不进行剪枝.
3.对结点②,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号 为 {1 , 2 , 3 , 14} 的训练样例,叶结点标记为"好瓜"此时决策树的验证集精度 提高至 71. 4%. 于是,后剪枝策略决定剪枝.
4.对结点③和①,若将其领衔的子树替换为叶结点,则所得决策树的验证集精度分别为 71.4% 与 42.9%,均未得到提高.于是它们被保留.
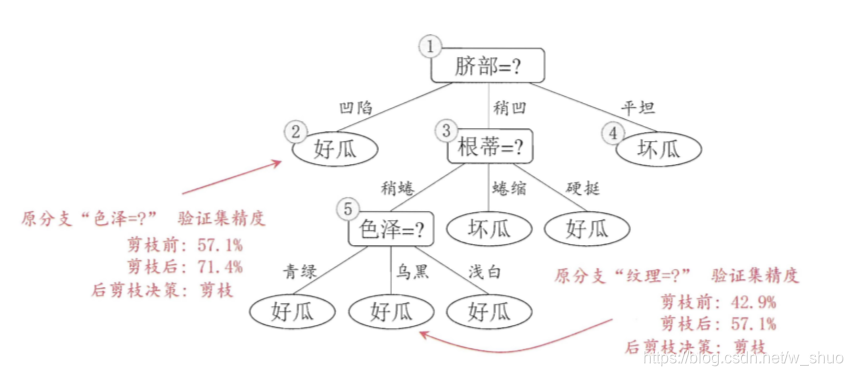
优点:后剪枝决策树的欠拟合风险很小,泛化性能往往优于预 剪枝决策树;
缺点:训练时间开销大
五、连续值与缺失值
1) 连续值
由于连续属性的可取值数目不再有限, 因此,不能直接根据连续属性的可 取值来对结点进行划分.
解决上面问题 --> 连续属性离散化技术
(1)二分法(bi-partition; C4. 5 决策树算法中 采用的机制 [Quinlan, 1993] ):
思路:
对于给定样本集D和连续属性a,假定a在D上出现了n个不同的取值,即把区间 [ai , ai+ 1) 的中位点 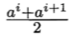 作为候选划分点,可计算包含 n-1 个元素的候选划分点集合:
作为候选划分点,可计算包含 n-1 个元素的候选划分点集合: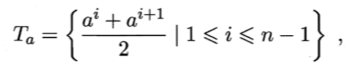
计算其信息增益的: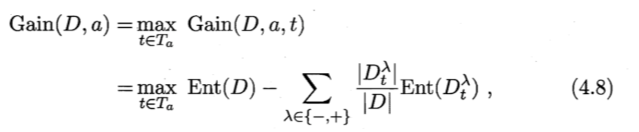
将信息增益最大的点作为划分点。
举例:
数据:
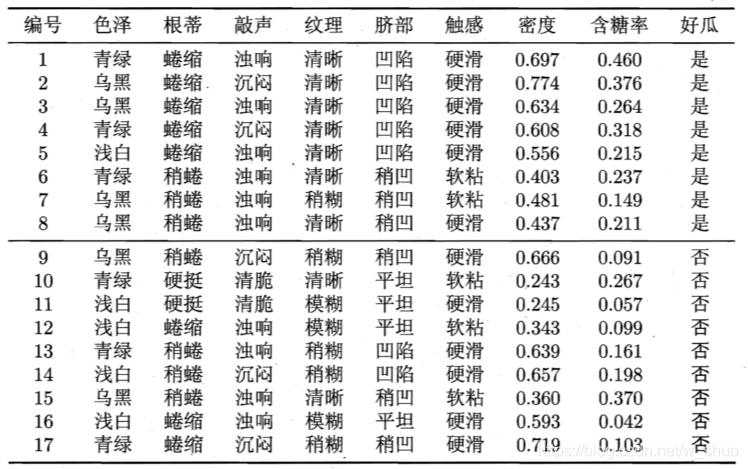
对属性"密度"在决策树学习开始时,根结点包含的 17 个训练 样本在该属性上取值均不同.根据公式,该属性的候选划分点集合 包含 16 个候选值:T密度 = {0.244, 0.294, 0.351 , 0.381 , 0.420, 0.459, 0.518, 0.574, 0.600, 0.621, 0.636, 0.648, 0.661 , 0.681 , 0.708, 0.746}. 由式(4.8) 可计算出属性"密度"的信息增益为 0.262,对应于划分点 0.381.
对属性"含糖率"其候选划分点集合也包含 16 个候选值:'L含糖率= {0.049, 0.074, 0.095, 0.101 , 0.126, 0.155, 0.179, 0.204, 0.213, 0.226, 0.250, 0.265, 0.292 , 0.344, 0.373, 0 .4 18}. 类似的,根据式(4.8)可计算出其信息增益为 0.349 ,对应于划分点 0.126.
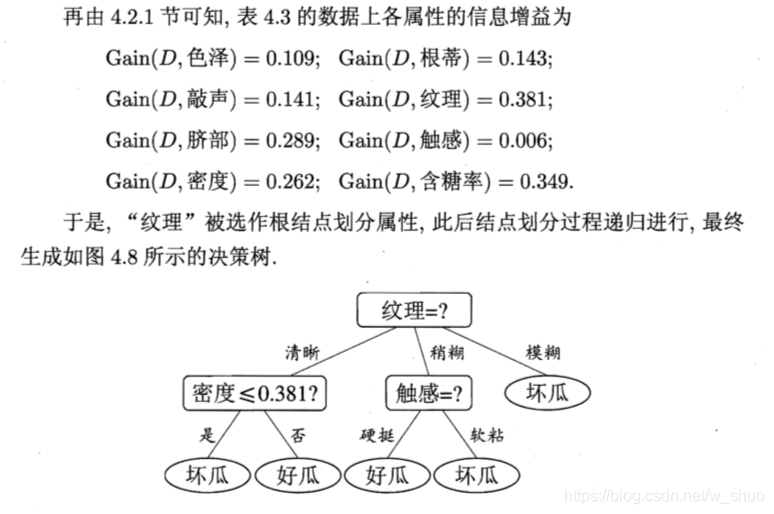
需注意的是,与离散属性不同,若当前结点划分属性为连续属性?该属性还 可作为其后代结点的划分属性.
2) 缺失值
现实任务中常会遇到不完整样本,即样本的某些属性值缺失.面对缺失数据,存在一下两个问题:
(1) 如何在属性值缺失的情况下进行划分属性选择?
(2) 给定划分属性?若样本在该属性上的值缺失,如何对样本进行划分?
本节数据:
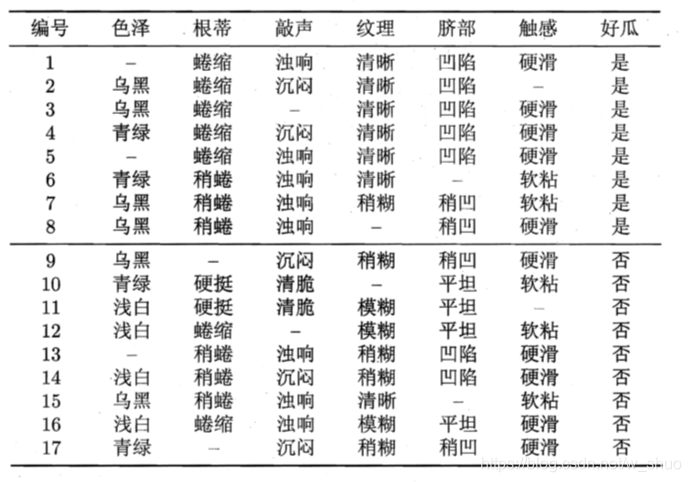
公式很繁重,内容很拉跨,直接看例子把:
1.初始的信息熵:

2.划分属性:



最后的决策树:
公式:
1.
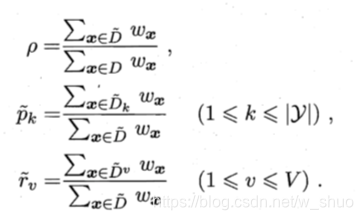
2.
六、多变量决策树
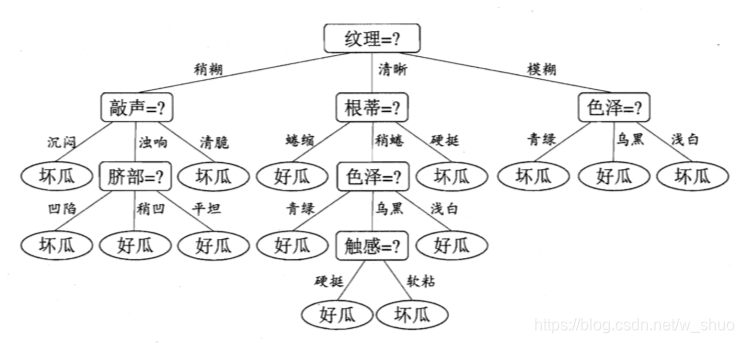
多变量决策树" (multivariate decision tree) 就是能实现"斜划分"甚至更复杂划分的决策树.在此类决策树中,非叶结点不再是仅对某个属性,而是对属性的线性组合进行测试;换言之,每个非叶结点是一个形如 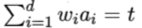 的线性分类器,其中Wi是属性ai的权重,Wi和 t 可在该结点所含的样本集和属性集上学得.于是,与传统的"单变量决策树" (univariate decision tree) 不同,在多变量决策树的学习过程中,不是为每个非叶结点寻找一个最优划分属性,而是试图建立一个合适的线性分类器.例如对如下西瓜数据我们可学得下图这样的多变量决策树,其分类 边界如下第三张图所示:
的线性分类器,其中Wi是属性ai的权重,Wi和 t 可在该结点所含的样本集和属性集上学得.于是,与传统的"单变量决策树" (univariate decision tree) 不同,在多变量决策树的学习过程中,不是为每个非叶结点寻找一个最优划分属性,而是试图建立一个合适的线性分类器.例如对如下西瓜数据我们可学得下图这样的多变量决策树,其分类 边界如下第三张图所示:
数据:
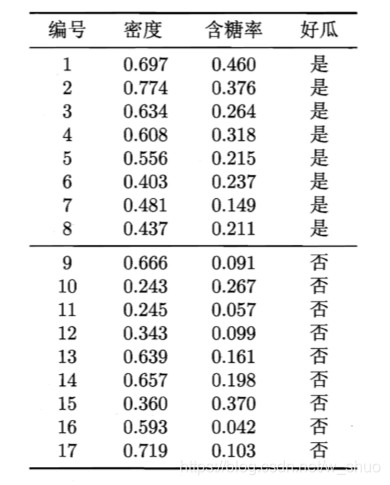
决策树:
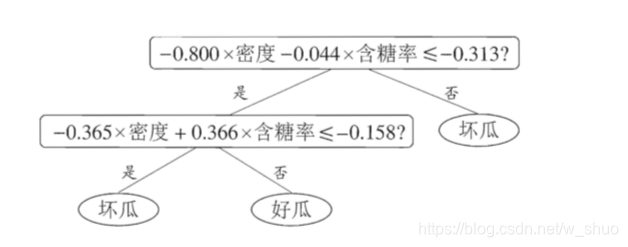
分类边界:














 1112
1112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









