



bash
- 命令行展开
echo wang{1..100} echo wang{1..100..2} 接两个数输出一次 bash能够识别{}
- 命令别名
alias
unalias 不使用别名
- 命令历史
!! 上一次的命令
- 快捷键
ctrl+a 移动到行首
ctrl+e 移动到行尾
ctrl+u 删除光标之前的字符
ctrl+k 删除光标之后的字符
ctrl+l 清空屏幕终端内容,同于clear
基本正则与扩展正则表达式
正则表达式的意义
- 处理大量的字符串
- 处理文本
- 配置文件
- 程序代码
- 命令输出结果
- 日志文件
- 正则表达式是一套规则和方法
- 正则工作时以单位进行,一次处理一行
- 正则表达式化繁为简,提高工作效率
- linux仅受三剑客(sed、awk、grep)支持,其他命令无法使用
- 通配符是大部分普通命都支持的,用于查找文件或目录,而正则表达式是通过三剑客命令在文件中过滤的
Linux三剑客
文本处理工具,均支持正则表达式引擎
- grep:文本过滤工具
- sed:stream editor,流编辑器:文本编辑工具
- awk:Linux的文本报告生成器(格式化文本),Linux上是gawk
正则表达式的分类
- 基本正则表达式
BRE对应元字符有^$.[]*
- 扩展正则表达式
- ERE在BRE基础上,增加上(){} ?+ |等
基本正则表达式BRE集合
- 匹配字符
- 匹配字数
- 位置锚定
^ 用于模式的最左侧,如“^wang”,匹配以wang开头的行
$ 用于模式的最右侧,如“wang$”,匹配以wang结尾的行
^$ 表示空行
. 匹配任意一个且只有一个字符,不能匹配空行
\ 让特殊含义的字符现出原形,\.代表小数点
* 匹配前一个字符(连续出现)0次或1次以上,重复0次代表空,即匹配所有内容
.* 匹配所有内容
^.* 匹配任意多个字符开头的内容
.*$ 匹配任意多个字符结尾的内容
[] 匹配[]集合内的任意一个字符,a或b或c
[^abc] 匹配除了^后面的任意字符,^表示对[abc]的取反
扩展正则表达式ERE集合
扩展正则必须用 grep -E 才能生效
+ 匹配前一个字符1次或多次
[:/]+ 匹配括号内的“:”或“/”字符一次或多次
? 匹配前一个字符0次或1次
| 表示或者,同时过滤多个字符串
() 分组过滤,一个整体 grep -E "(l..e).*\1" wang.txt匹配l到e的所有内容
a{n,m} 匹配前一个字符最少n次,最多m次 grep -E "y{2,4}" wang.txt 匹配y最少2次,最多4次
a{n,} 匹配前一个字符最少n次
a{n} 匹配前一个字符正好n次
a{,m} 匹配前一个字符最多m次
grep
文本搜索工具,过滤内容,对目标文本逐行进行匹配检查
模式:由正则表达式元字符及文本字所编写出的过滤条件
* grep [options] [pattern] file
命令 参数 匹配模式 文件数据
-i:ignorecase,忽略字符的大小写
-o:仅显示匹配到的字符串本身
-v,--invert-match:显示不能被模式匹配到的行
-E:支持使用扩展的正则表达式字符
-q,--quiet,--silent:静默模式,既不输出任何信息
-v:排除匹配的结果
-n:显示匹配的行号
-c:只匹配显示的行数
-w:只匹配过滤的单词
TIP
注意在Linux平台下,所有文件的结尾都有一个$符
- ^符号
输出所有以m开头的行 grep -i -n ‘^m’ wang.txt
输出所有空行 grep -i -n ‘^$’ wang.txt
- $符
输出所有以r结尾的行 grep -i -n ‘r$’ wang11
输出所有以.结尾的行 grep -n ‘\.$’ wang11 要用\,不然会被当做正则表达式使用
输出所有以r结尾的行,并用-o把root前面的内容过滤掉 grep -i -n ‘root$’ wang11 -o
把除了root$的内容输出 grep -i -n ‘root$’ wang11 -v
- .符号
. 表示任意一个字符,有且只有一个,不包含空行
把所有行输出并标红 grep ‘.’ wang11
匹配s前面的一个字符 grep '.s' wang11
- *符号
匹配i,找出i的0次或多次 pgrep ‘i*’ wang11
- .*组合符
匹配所有的行内容 grep ‘.*’ wang11
匹配到e结尾 grep '.*e' wang11
- []中括号
找出a-z所有的小写字母 grep ‘[a-z]’ wang11
找出所有的大写和数字 grep ‘[A-Z0-9]’ wang11
全文匹配 grep ‘[a-zA-Z0-5]’ wang11
找出除了^后面的行 grep ‘[^0-5]’ wang11
- +号
匹配i一次或多次 grep -E ‘i+’ wang11
- ?号
匹配i零次或一次 grep -E ‘go?d’ wang11 在goooooood god gd goood中只匹配god和gd
- |符
或者的意思
在wang11中匹配i和l cat wang11 | grep -E ‘i|l’
匹配good和glad grep -E "g(oo|la)d" wang.txt
- ()小括号
/1:表示从左侧起,第一个括号中的模式所匹配到的字符
/2:从左侧起,第二个括号中的模式所匹配到的字符
- {}
匹配y最少2次,最多4次grep -E "y{2,4}" wang.txt
sed
是操作、过滤和转换文本内容的工具
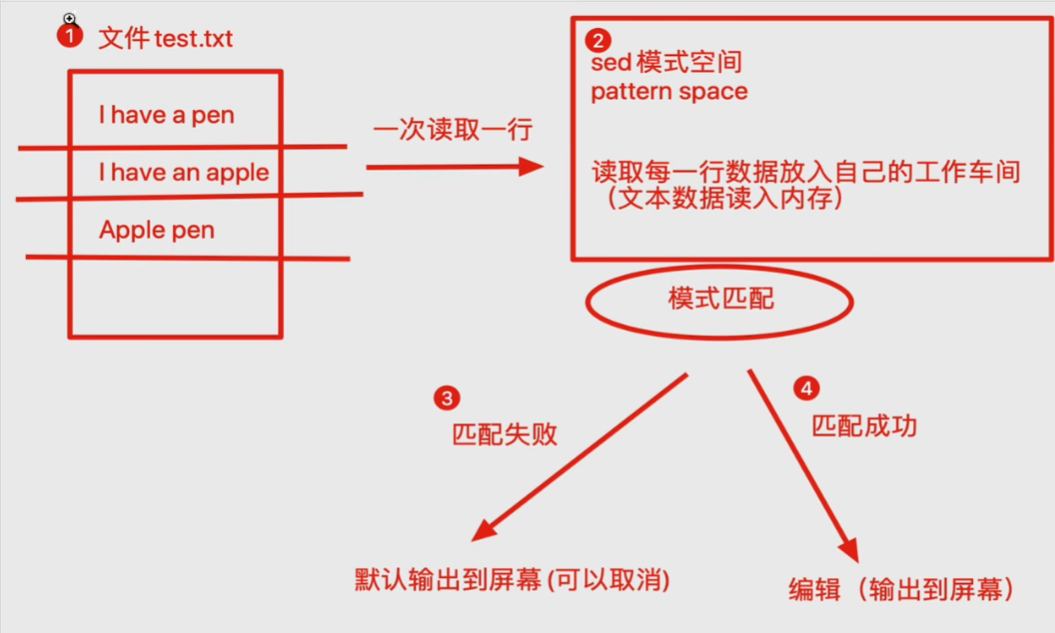
语法:sed 选项 sed内置命令字符 输入文件
-n:取消默认sed的输出,常与命令p一起使用
-i:直接将修改结果写入文件,不用-i,sed修改的是内存数据
-e:多次编辑,不需要管道符
-r:支持正则扩展
a:append,对文本追加,在指定行后面添加一行/多行文本
d:delete,删除匹配行
i:insert,表示插入文本,在指定行前面添加一行/多行文本
p:print,打印匹配行的内容
s/正则/替换内容/g:匹配正则内容,然后替换内容,结尾g代表全局匹配
空地址:全文处理
单地址:指定文件某一行
/pettern/:被模式匹配到的每一行
范围区间:10,20 十到二十行 , 10,+5 第十行向下加五行 , /pattern/,/pattern/
步长:1~2,表示1,3,5,7,9行,2~3两个步长,表示2,4,6,8,10,偶数行
- 输出文件第二三行的内容,不加-n会默认输出所有内容
sed “2,3p” wang11 -n 打印第二三行数据
sed “2,+3p” wang11 -n 打印第二行向下三行数据
- 过滤出含有**的字符串行
sed “/school/p” wang11 -n 过滤含有school的行
- 删除含有**的行,修改文件内容用-i
sed “/school/d” wang11 -n 删除含有school的行
sed “5,$d” wang11 -i 删除第五行到结尾
- 文件中的替换
sed “s/你想要找到的内容/你想替换的内容/g” wang11
sed -e “s/fff/my/g” -e “s/yy/wang/g” wang11 -i 将fff替换为my,并且将yy替换为wang
- 在文件行追加内容 a字符功能
sed "2a whoshi" wang11 -i 在第二行后面添加whoshi
sed “4i whoshiwo” wang11 -i 在第四行前面添加whoshiwo
- 添加多行信息,用换行符“\n”
sed “3a i like c.\n i like py" -i 在第三行后面添加i...和i...并换行
- 在每一行下面插入新内容
sed “a ------------” wang11 -i 在每一行下面添加----------
sed “i ------------” wang11 -i 在每一行上面添加----------
sed配合正则表达式的使用
- 去头去尾法,只得到ip
ifconfig eth0 | sed "2p" -n | sed "s/^.*inet//" | sed “s/net.*$//” 取出ip地址,将IP地址前后内容删去
- -e参数多次编辑
ifconfig eth0 | sed -e "2s/^.*inet//" -e "2s/net.*$//p" -n 取出ip地址,将IP地址前后内容删去
awk
适合文本格式化,对文本进行复杂处理
awk基础
awk [option] 'patten[action]' file ....
可选参数 模式 动作 文件/数据
最常用的动作是print和printf
awk ‘{printf $1}’ wang11,表示输出文本的第二列信息
awk默认以空格为分隔符,且多个空格也识别为一个空格
awk是按行来处理的,一行处理完毕,处理下一行
$0表示整行,$NF表示当前分割后的最后一行,倒数第二行可以写成$(NF-1)
$n:指定分隔符后,当前记录的第n个字段
$0:完整的输入记录
FS:字段分隔符,默认是空格
NF(Number of fieids):分割后,当前行一共有多少个字段
NR(Number of records): 当前记录数,行数
- 一次输出多行
输出1,2,5列,中间逗号代表空格 awk ‘{print $1,$2,$5}’ wang11
- 自定义输出内容
awk,必须外层单引号,内层双引号 $1,$2不能加双引号,否则会识别为文本
awk '{print "第一列:" $1,"第二列:"$4,"第三列:"$5}' wang00

- 输出整行信息
awk ‘{print}’ wang11
awk ‘{print $0}’ wang11
awk ‘{print "每一行的内容是:"$0}’ wang11
-F:指定分割字符段
-v:定义或修改一个awk内部的变量
-f:从脚本文件中读取awk命令
- 显示第五行
NR在awk中表示行号,NR==5表示行号是5的那一行
一个等号是修改变量值的意思,两个等号是关系运算符,是等于的意思
输出第五行的所有内容awk 'NR==5{print $0}' wang00
- 显示文件22的内容添加行号
添加变量,NR等于行号,$0表示一整行的内容
给每一行添加行号 awk ‘{print NR,$0}’ wang11
- 显示3-5行且输出行号
awk 'NR==3,NR==5 {print NR,$0}' wang00
- 显示wang00文件的第一列,倒数第二列和最后一列
awk ‘{print $1,$(NF-1),$(NF-2)}’ wang11
awk分隔符
输入分隔符,awk默认的是空格,空白字符,变量是FS
输出分隔符,简称OFS
- FS输入分隔符
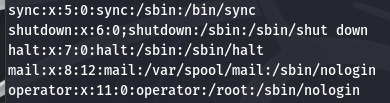
当没有空格时,可以指定分隔符,输出第一列 awk -F “:” ‘{print $1}’ wang11
输出第一列和最后一列 awk -F “:” ‘{print $1,$NF}’ wang11
还可使用变量的形式,使用-v,修改FS变量 awk -v FS= “:” ‘{print $1}’ wang11
- OFS输出分隔符
wk -F ":" -v OFS="------" '{print $1,$NF}' wang00
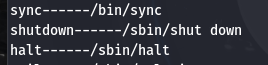
wk -F ":" -v OFS="\t" '{print $1,$NF}' wang00
awk变量
- awk参数
-F:指定分割字段符
-v:定义或修改一个awk内部的变量
-f:从脚本文件中读取awk命令
FS:输入字段分隔符,默认为空白字符
OFS:输出字段分隔符,默认为空白字符
RS:输入记录分隔符(输入换行符),指定输入时的换行符
ORS:输出记录分隔符(输出换行符),输出时用指定的符号代替换行符
NF:当前行的字段的个数(即当前行被分割成了几列),字段数量
NR:行号,当前处理的文本行的行号
FNR:各文件分别计数的行号
FILENAME:当前文件名
ARGC:命令行参数的个数
ARGV:数组,保存的是命令行所给定的各参数
awk -v FS=":" -v OFS="---" '{print NR,NF,$1}' wang11
内置变量
- NR,NF,FNR
- awk的内置变量NR、NF不用添加$符号
- 而$0 $1 $2...需要添加$符号
输出每行行号,以及字段总个数 awk -v FS=":" '{print NR,NF,$1}' wang000
输出每行行号,以及指定的列 awk -v FS=":" ‘{print NR,$1,$列}’ wang11
- 处理多个文件显示行号
不单独输出行号 awk '{print NR,$0}' wang11 wang00
单独输出行号 awk '{print FNR,$0}' wang11 wang00
- RS
以每个空格作为换行符 awk -v RS='空格' '{print NR,$0}' wang00
- 内置变量ORS
每行结束添加内容 awk -v ORS='-------chaoge666ya--------' '{print NR,$0}' wang00
- 内置变量FILENAME
显示awk正在处理文件的名字 awk '{print FILENAME,$0}' wang00
![]()
- 变量ARGC、ARGV
在开始输入内容 awk 'BEGIN{print "chaogekaishi"} {print $0}' wang00
![]()
awk 'BEGIN{print "chaogekaishi"} {print ARGV[0],$0}' wang00
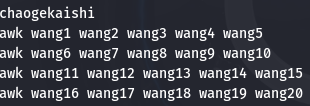
awk 'BEGIN{print "chaogekaishi"} {print ARGV[1],$0}' wang00
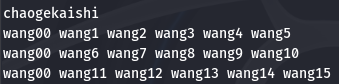
awk 'BEGIN{print "chaogekaishi"} {print ARGV[0],ARGV[1],ARGV[2]}' wang0
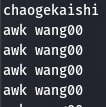
awk 'BEGIN{print "chaogekaishi"} {print ARGV[0],ARGV[1],ARGV[2]}' wang00 wang000
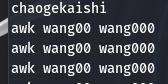
- 自定义变量
awk -v myname="wang" 'BEGIN{print "my name is?",myname}'
![]()
awk格式化输出
- awk格式化
print,只能对文本简单的输出,并不能美化或修改格式
- print格式化输出
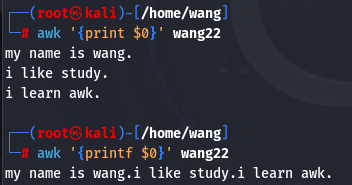
- printf和print的区别出
print会换行输出
printf不会换行输出
要点
其与print命令的最大不同是,printf需要指定format
format用于指定后面的每一个item的输出格式
printf语句不会自动打印换行符:\\n
format格式的指示符都以%开头,后跟一个字符
如下:
%c:显示字符的ASCII码
%d,%i:十进制整数
%e,%E:科学计数法显示数值
%f:显示浮点数
%g,%G:以科学计数法的格式或浮点数的格式显示数值
%s:显示字符串
%u:无符号整数
%%:显示%自身
print修饰符:
-:左对齐,默认右对齐
+:显示数值符号
- 给printf添加格式
格式化字符%s代表字符串的意思
awk '{printf "%s\n",$0}' wang22

printf '%s---\n' a b c d e

awk 'BEGIN{printf "%d\n%d\n%d\n%d\n",1,2,3,4}'
![]()
- 对多个变量进行格式化
awk '{printf " 第一列:%s 第二列:%s 第三列:%s\n",$1,$2,$3}' wang00

- 对文件格式化
‘BEGIN{printf “格式替换符 格式替换符”,“变量1”,“变量2”}’ 执行BEGIN模式
%s是格式替换符,替换字符串
%s\t 格式化字符串后,添加制表符,四个空格
%-25s 已然是格式化字符串,- 代表左对齐,25个字符长度
- awk模式
BEGIN模式完成后,在对文件进行处理 awk 'BEGIN{print "CHf"}{print $0}' wang22

- awk结合BEGIN和END模式
awk 'BEGIN{print "CHf"}{print $0}END{print "zjixingend"}' wang22
处理文本之前的操作 所有文本处理完毕,执行END命令
- awk模式pattern
模式可以理解为条件
awk默认是按行处理文本,如果不指定任何模式(条件),awk默认一行行处理
如果指定了模式,只有符合模式的才会被处理
- 模式(条件)案例
== 等于
!= 不等于
~ 匹配正则 x~/正则/
!~ 不匹配正则 x!~/正则/
打印wang22中第二行信息 awk 'NR==2{print $0}' wang22
awk 'NR==2{print}' wang22
awk 'NR==2' wang22
打印wang22中<4行的信息 awk 'NR<4{print $0}' wang22
不打印第三行的信息 awk 'NR!=3{print $0}' wang22
- awk与正则表达式
正则表达式主要与awk的pattern模式结合使用
不指定模式,awk每一行都会执行对应的动作
指定了模式,只有被模式匹配到的、符合条件的行才会执行动作
- 找出wang11中以game开头的行
grep ‘正则表达式’ wang11
awk ‘/正则表达式/动作’ wang11
- 用grep进行过滤 grep “game” wang11
- 用awk进行过滤 wak ‘/^game/{print $0}’ wang11
- awk强大的格式化文本
awk -F ":" 'BEGIN{printf"%-20s\t%-30s\t%-20s\t%-20s\t\n","用户名","用户id","用户家目录","用户解释器"}{printf "%-30s\t%-30s\t%-30s\t%-30s\t\n",$1,$3,$6,$7}' wang000

- awk的命令执行流程
awk ‘BEGIN(commands) pattern(commends) END(commends)’
优先执行BEGIN{}模式中的语句
从wang11文件中读取第一行,然后执行pattern(commends)进行正则匹配/n^/ 寻找n开头的行,找到了执行{print}进行打印
当awk读取到文件数据流的结尾时,会执行END{commends}
- 找出wang11文件中禁止登陆的用户(/sbin/nologin)
正则表达式中如果出现了“/”则需要转义
- 用grep过滤 grep “/sbin/nologin” wang11
- awk用正则得用双斜杠 /正则表达式/ awk '/\/sbin\/nologin/{print NR,$0}' wang11
- 找出文件的区间内容
找出wang11中第4到7行的内容 awk '/^mail/,/^ftp/{print NR,$0}' wang000

- 统计日志的访客ip数量
sort -n 数字从大到小排序
wc -l 统计行数,ip的条目数
awk ‘{print $1}’ 500access.log | sort -n | uniq | wc -l
排序 去重 统计行数
- 查看访问最频繁的前10个ip
uniq -c 去重显示次数
sort -n 从大到小排序
-r 反转参数
head -行数 从头取多少行
awk ‘{print $1}’ access.log | sort -n | uniq -c | sort -nr


















 2703
2703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









