






1.引子
25年前的cpu没有现在这麽复杂。那时候,cpu和内存的频率在同一个级别。内存的访问只比寄存器慢了一点点。但是这一切在90年代发生巨变。cpu厂商增加了其频率,但是内存厂商却没有相应地增加。原因不是技术上做不到,而是花费太高。内存频率若与cpu频率频率相同,所需要的经济代价要贵几个数量级。
内存速度快,但考虑到经济性,不可能做太大。大容量的数据我们一般放在硬盘中。这是一种方法。但硬盘速度比起内存差远了。
我们还有另一种方法,就是增加SRAM,SRAM比主存(DRAM)快,把内存中的一些数据缓存到SRAM中,需要时快速取来。SRAM是否可以同内存一样放在cpu外?不可行,原因是对SRAM的管理开销太大(kernel 对内存的管理就占整个内核工作量的三分之一),SRAM的速度优势与这个开销相比,简直得不偿失。所以我们把SRAM集成到CPU中。集成到CPU中的SRAM就叫CPU cache。当然,CPU cache虽然快,但也贵啊,所以容量很小,就几兆,对它的管理也是大有文章的。
2.计算机系统中的CPU cache
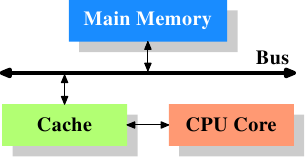
上图是CPU cache在计算机系统中的位置,cache与内存通过FSB总线相连。此图省略了北桥。
过去计算机系统使用冯诺依曼架构(数据和指令放在一起),这种结构设计制造简单,但是速度还有提升空间。于是出现了哈佛结构(数据和指令分开存取)。英特尔自93年开始使用指令和数据分开存放的CPU cache。例如下图:
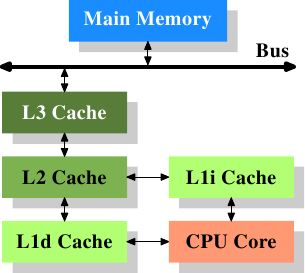
但是L1缓存还是小,怎么办,设计生产大容量的L1 cache?不,这样成本太高了。我们可以制造速度稍慢一点的二级缓存甚至三级缓存。
上图中数据流并非一定是这样走流经多级缓存。多级缓存之间的设计由设计师自由发挥,可能和图中不符,我们编写软件不必在意,它在我们眼里是透明的。
但是,cpu进行写数据时,数据流向:cpu->cache->memory,这是不会变的,当cache中数据变了(内存中尚未更新),此时cache line是dirty;当内存也更新了,dirty重置。
在多cpu系统中是这样的:
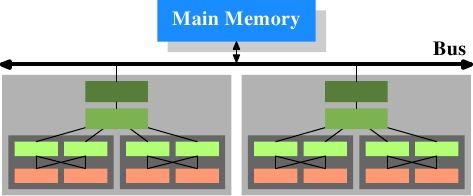
这个计算机系统有两个CPU,每个CPU是两核,每个核中运行两个线程(依照上图自己对号入座)。同一个核中的线程共享L1缓存,cpu中的两个core共享L2缓存。两个CPU不共享任何cache,因为cache是cpu的cache。
3.CPU cache的分类
缓存描述符:

表示一个内存地址到一个缓存地址的映射。
内存地址到缓存地址映射有三种:
一,直接映射

地址映象规则: 主存储器中一块只能映象到Cache的一个特定的块中。
优点:映射简单
缺点:换入换出频繁,命中率低(cache_index0中,缓存memory_index0,4,8…,只能一个,命中率低,需换出),cache使用效率低。
二,全关联映射

地址映象规则:主存的任意一块可以映象到Cache中的任意一块
优点:命中率高,cache使用效率高
缺点:速度慢,硬件复杂,故用在小容量cache,如TLB。
三,组关联映射
直接映射与全关联映射的折中。
如上上右图。先直接映射到set(index),再全关联到line(way)。
使用最普遍。
4.参考
https://en.wikipedia.org/wiki/CPU_cache#Associativity
http://blog.csdn.net/stardhb/article/details/44900509
http://www.cnblogs.com/freebye/archive/2005/04/08/133699.html
http://blog.csdn.net/pang040328/article/details/4285590
http://blog.csdn.net/qq_34374664/article/details/54142347















 6389
6389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









