









模型训练
原来我们的感觉是这样的
y
=
f
(
x
)
y = f(x)
y=f(x)
模型训练的细节都是使用梯度下降去进行调节的。
不过这里我们被蒙蔽了一点,至少新手如我:我们是可以直接拟合的。
多数的任务我们都是通过模型作为转换器,把基础输入替换到我们的目标空间。也就是间接拟合。
我们的拟合无处不在,间接并非第一步,因为转换器的参数,本身就是直接拟合的。
直接拟合
a ⇒ b a \Rightarrow b a⇒b
import torch
from torch import optim
from torch.nn import functional as F
src = torch.randint(0, 100, (1, 10), dtype=torch.float)
dst = torch.arange(0, 10, dtype=torch.float).unsqueeze(0)
dst.requires_grad = False
iterations = 0
optimizer = optim.Adam([src.requires_grad_()])
while iterations < 100000:
optimizer.zero_grad()
loss = F.mse_loss(src, dst)
loss.backward()
optimizer.step()
print(f'iterations : {iterations}, Loss : {loss}')
iterations += 1
print(src)

并不是简单计算梯度,而是直接更新了数值。
所以平时见到需要model.parameters()其实都是要进行直接拟合的,使得最终的损失最小。
单次下降
大部分的梯度下降方法都是连续梯度下降,也就是说它能根据每次输出去更新同一份的参数列表。
但是有些梯度下降方法,和LBFGS一样,属于单次的计算,这种时候需要特殊的传递方法。
import torch
from torch import optim
from torch.nn import functional as F
src = torch.randint(0, 100, (1, 10), dtype=torch.float)
dst = torch.arange(0, 10, dtype=torch.float).unsqueeze(0)
dst.requires_grad = False
iterations = [0]
optimizer = optim.LBFGS([src.requires_grad_()])
def f():
optimizer.zero_grad()
loss = F.mse_loss(src, dst)
loss.backward()
print(f'iterations : {iterations[0]}, Loss : {loss}')
iterations[0] += 1
return loss
while iterations[0] < 10:
optimizer.step(f)
print(src)
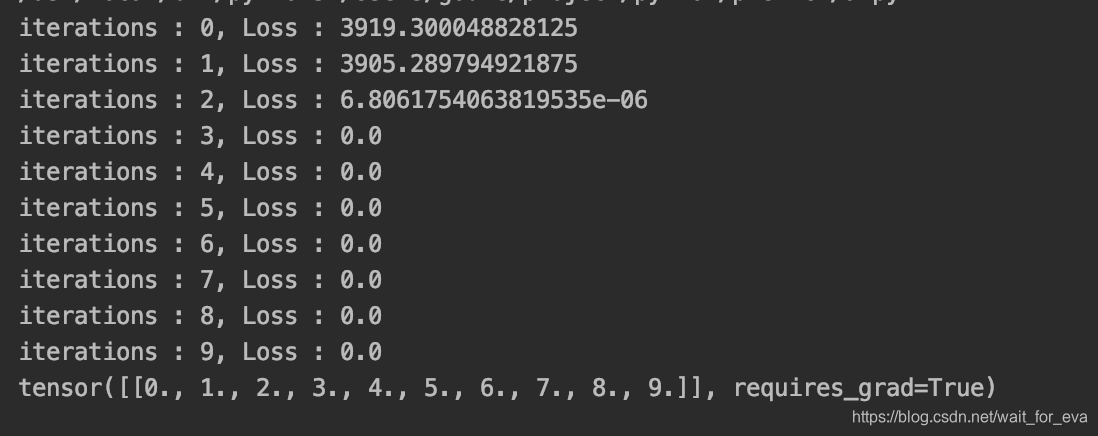
把单元的下降方法写为一个函数,step外层进行更新,传入下降函数即可。
可以看到,虽然不能够连续,但是断崖式的回归,能够极大的减少计算步骤。
风格迁移
大多数模型都是复杂的,因为他们都算作是转换器而非生成器。
但是基础的图像风格转移,就是风格图像的直接生成,这个时候,不存在网络的转换。
因此,对于这种直接的生成、拟合,需要采用的就是直接拟合而非模型训练。
把图像作为一个Tensor,和上面的方法一样,不停的依据损失进行拟合,最后得出来的就是目标张量。
而这个张量,刚好就是那个需要的图片。














 718
718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









