







计算机处于网络中,是不知道什么时候会发过来数据,是不可预测的。因此,目前所有的现代设备驱动程序都是使用了中断来通知内核的有 链路层的以太网帧到达。
驱动程序有特定的相应的程序,因此当有数据帧到达的时候,内核就会调用该程序。将数据从网卡上传输到物理内存中。或者通知内核延迟处理。
下面一个图就是数据穿过内核的路径完整的路径
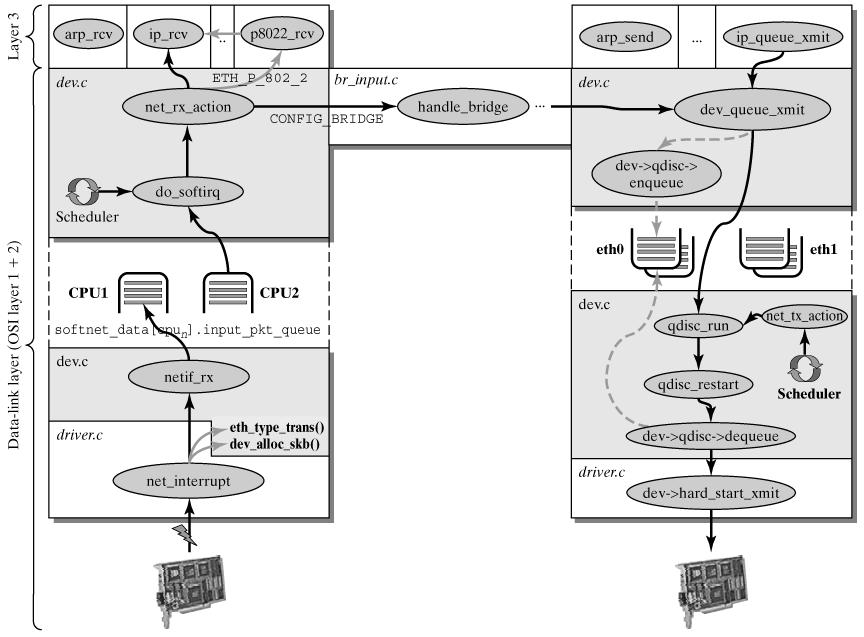
(1)net_interrupt是设备驱动程序设置的终端处理程序。
(2)net_rx 函数是特定于网卡。首先会创建一个心的套接字缓冲区。分组的内容就会从网卡传输到缓冲区,也就是内核空间的内存中。然后使用各种函数来分析这个数据包,比如IP协议。
下面一个比较重要的函数
/**
* netif_rx - post buffer to the network code
* @skb: buffer to post
*
* This function receives a packet from a device driver and queues it for
* the upper (protocol) levels to process. It always succeeds. The buffer
* may be dropped during processing for congestion control or by the
* protocol layers.
*
* return values:
* NET_RX_SUCCESS (no congestion)
* NET_RX_CN_LOW (low congestion)
* NET_RX_CN_MOD (moderate congestion)
* NET_RX_CN_HIGH (high congestion)
* NET_RX_DROP (packet was dropped)
*
*/
int netif_rx(struct sk_buff *skb)
{
int this_cpu;
struct softnet_data *queue;
unsigned long flags;
if (!skb->stamp.tv_sec)
do_gettimeofday(&skb->stamp);
/*
* The code is rearranged so that the path is the most
* short when CPU is congested, but is still operating.
*/
local_irq_save(flags);
this_cpu = smp_processor_id();
queue = &__get_cpu_var(softnet_data);
__get_cpu_var(netdev_rx_stat).total++;
if (queue->input_pkt_queue.qlen <= netdev_max_backlog) {
if (queue->input_pkt_queue.qlen) {
if (queue->throttle)
goto drop;
enqueue:
dev_hold(skb->dev);
__skb_queue_tail(&queue->input_pkt_queue, skb);
#ifndef OFFLINE_SAMPLE
get_sample_stats(this_cpu);
#endif
local_irq_restore(flags);
return queue->cng_level;
}
if (queue->throttle) {
queue->throttle = 0;
#ifdef CONFIG_NET_HW_FLOWCONTROL
if (atomic_dec_and_test(&netdev_dropping))
netdev_wakeup();
#endif
}
netif_rx_schedule(&queue->backlog_dev);
goto enqueue;
}
if (!queue->throttle) {
queue->throttle = 1;
__get_cpu_var(netdev_rx_stat).throttled++;
#ifdef CONFIG_NET_HW_FLOWCONTROL
atomic_inc(&netdev_dropping);
#endif
}
drop:
__get_cpu_var(netdev_rx_stat).dropped++;
local_irq_restore(flags);
kfree_skb(skb);
return NET_RX_DROP;
}
/*
* Incoming packets are placed on per-cpu queues so that
* no locking is needed.
*/
struct softnet_data
{
int throttle;
int cng_level;
int avg_blog;
struct sk_buff_head input_pkt_queue;
struct list_head poll_list;
struct net_device *output_queue;
struct sk_buff *completion_queue;
struct net_device backlog_dev; /* Sorry. 8) */
};
上边那个方法就是让所的消息按照一个队列上上一次层协议去处理。其内部原理就是将受到的队列分组放到特定的cpu上的等待队列并推出中断上下文,是cpu做别的事情。
队列就是struct softnet_data数据结构。
接着,会分配一个新的套接字缓冲区 skb ,并调用与协议无关的、网络设备均支持的通用网络接收处理函数 netif_rx(skb) 。 netif_rx() 函数让内核准备进一步处理 skb 。
- 然后, skb 会进入到达队列以便 CPU 处理(对于多核 CPU 而言,每个 CPU 维护一个队列)。如果 FIFO队列已满,就会丢弃此分组。在 skb 排队后,调用 __cpu_raise_softirq() 标记 NET_RX_SOFTIRQ 软中断,等待 CPU 执行。
- 至此, netif_rx() 函数调用结束,返回调用者状况信息(成功还是失败等)。此时,中断上下文进程完成任务,数据分组继续被上层协议栈处理。
NET_RX_SOFTIRQ 网络接收软中断
CPU 开始处理软中断 do_softirq() ,,接着 net_rx_action() 处理前面标记的 NET_RX_SOFTIRQ ,把出对列的 skb 送入相应列表处理(根据协议不同到不同的列表)。比如,IP 分组交给 ip_rcv() 处理, ARP 分组交给 arp_rcv() 处理等。
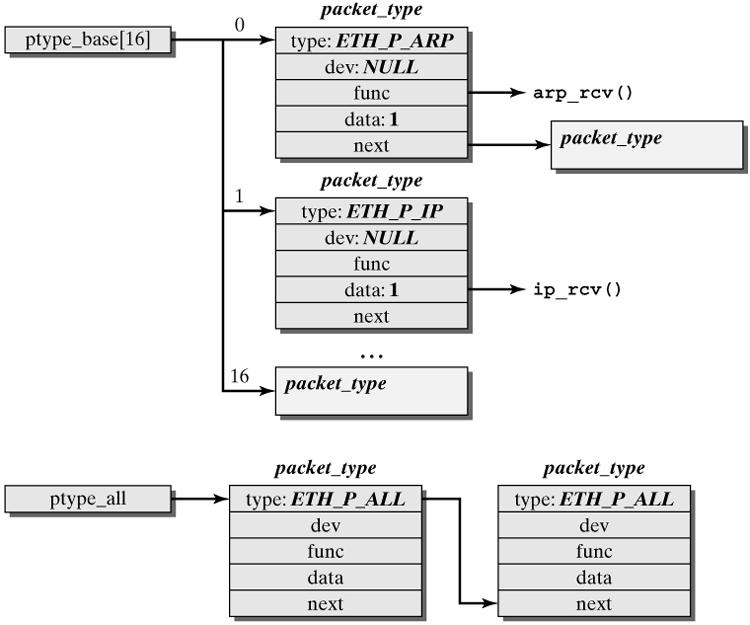
今天只能看着点,很多不明白啊,要细细研究。
更多文章,欢迎访问 http://blog.csdn.net/wallwind














 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









