







1. 问题介绍
在最优化方法中,Newton方法是一个比较经典的方法,它常用来求解无约束的优化问题或含有等式约束的优化问题。准确的说,Newton方法一般分为纯Newton方法和拟Newton方法。今天我们考虑的是无约束优化问题的纯Newton方法,其他衍生方法后续再讲解。
求解的问题是:
min
f
(
x
)
\min {\kern 1pt} f(x)
minf(x)
迭代方法的基本思想:我们每次都按一个方向找一个点
x
(
i
)
x^{(i)}
x(i)(
i
i
i表示第
i
i
i次迭代时找的点),如果每次点对应的函数值都小于前一次,即
f
(
x
(
i
+
1
)
)
<
f
(
x
(
i
)
)
f(x^{(i+1)})< f(x^{(i)})
f(x(i+1))<f(x(i)),那么我们总能找到最终需要的点
x
∗
x^*
x∗,该点处函数值是最小的。
根据上面的思想,我们需要做的只有两点:一是往哪个方向找点;二是找到方向后,你应该以什么样的规则去确定要找的点,也即是步长。目前我们所了解的绝大部分迭代优化算法都是围绕方向和步长这两点来做文章。
例子:不一定恰当,但有助于你理解。想像一下你在登一座未开发的山,你的目标是找到山的最高点(你把山倒过来看,那么最高点就是我们要的
x
∗
x^*
x∗)。首先你要做的是确定从哪个方向登山,因为有的方向路线比较陡峭,有的方向比较平坦,陡峭的方向当然有助于你快速到达最高点。其次你要做的是确定每步跨多大,即步长。如果你每步都是2米的步长去走,虽然你会以更快的速度接近你要的点,但也很有可能越过最高点。
2. Newton方向的解释与推导
根据上面迭代的基本思想,Newton方法之所以叫Newton方法,因为他找了一个方向,该方向称之为Newton方向。那么何为Newton方向方向呢?
2.1 二阶近似角度
假设迭代到第k步,点从
k
−
1
k-1
k−1步的
x
(
k
−
1
)
=
x
x^{(k-1)}=x
x(k−1)=x 变为
x
(
k
)
=
x
+
v
x^{(k)}=x+v
x(k)=x+v,此时函数值为
f
(
x
+
v
)
f(x+v)
f(x+v),其二阶Taylor近似为:
f
(
x
+
v
)
≈
f
^
(
x
+
v
)
=
f
(
x
)
+
∇
f
(
x
)
T
v
+
1
2
v
T
∇
2
f
(
x
)
v
f(x + v) \approx \hat f(x + v)=f(x)+\nabla f{(x)^T}v + \frac{1}{2}{v^T}{\nabla ^2}f(x)v
f(x+v)≈f^(x+v)=f(x)+∇f(x)Tv+21vT∇2f(x)v 显然,上式是关于
v
v
v的二次凸函数。如果在点
x
(
k
)
x^{(k)}
x(k)处函数值最小,那么应该有其一阶导等于0。因此,我们对
v
v
v求一阶偏导并令其等于0有:
∇
f
(
x
)
+
∇
2
f
(
x
)
v
=
0
\nabla f{(x)}+{\nabla ^2}f(x)v=0
∇f(x)+∇2f(x)v=0求得
v
v
v等于:
v
=
−
[
∇
2
f
(
x
)
]
−
1
∇
f
(
x
)
v=- [{\nabla ^2}f{(x)]^{ - 1}}\nabla f(x)
v=−[∇2f(x)]−1∇f(x)。好了,
−
[
∇
2
f
(
x
)
]
−
1
∇
f
(
x
)
- [{\nabla ^2}f{(x)]^{ - 1}}\nabla f(x)
−[∇2f(x)]−1∇f(x)即为牛顿方向,记为
Δ
x
n
t
\Delta {x_{nt}}
Δxnt。(注意:方向一定是个向量)
通过上述分析,我们可以看出 牛顿方向的一些本质。具体见下图:
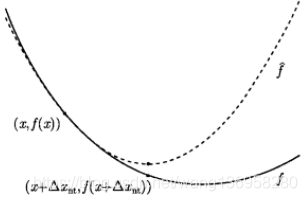
上图中,实线是实际的函数,虚线是该函数的二阶近似,我们可以直观的看出,如果
f
f
f是二次的,那么
x
+
Δ
x
n
t
x+\Delta x_{nt}
x+Δxnt就是最优点
x
∗
x^*
x∗,即使
f
f
f不是二次的,当
x
x
x靠近
x
∗
x^*
x∗时,
x
+
Δ
x
n
t
x+\Delta x_{nt}
x+Δxnt也是
x
∗
x^*
x∗的一个比较好的估计。
2.2 线性化最优性条件的角度
我们知道对于可微函数,其最优解的充分条件是
x
∗
x^*
x∗处的梯度为0,即
∇
f
(
x
∗
)
\nabla f({x^*})
∇f(x∗),我们对其进行线性化(即一阶展开):
∇
f
(
x
+
v
)
≈
∇
f
(
x
)
+
∇
2
f
(
x
)
v
=
0
\nabla f(x + v) \approx \nabla f(x) + {\nabla ^2}f(x)v=0
∇f(x+v)≈∇f(x)+∇2f(x)v=0同样我们可以求得
v
=
−
[
∇
2
f
(
x
)
]
−
1
∇
f
(
x
)
v=- [{\nabla ^2}f{(x)]^{ - 1}}\nabla f(x)
v=−[∇2f(x)]−1∇f(x),即
Δ
x
n
t
\Delta x_{nt}
Δxnt。
注:牛顿方向具有仿射不变性,此处就不细讲了。
3. Newton减量
我们将 λ ( x ) = ( ∇ f ( x ) T [ ∇ 2 f ( x ) ] − 1 ∇ f ( x ) ) 1 2 \lambda (x) = {(\nabla f{(x)^T}[{\nabla ^2}f{(x)]^{ - 1}}\nabla f(x))^{\frac{1}{2}}} λ(x)=(∇f(x)T[∇2f(x)]−1∇f(x))21称为 x x x处的Newton减量。减量的作用在于设计迭代的停止准则。我们有:
f
(
x
)
−
f
^
(
x
+
v
)
=
f
(
x
)
−
f
(
x
)
−
∇
f
(
x
)
T
v
−
1
2
v
T
∇
2
f
(
x
)
v
=
−
∇
f
(
x
)
T
{
−
[
∇
2
f
(
x
)
]
−
1
∇
f
(
x
)
}
−
1
2
{
−
[
∇
2
f
(
x
)
]
−
1
∇
f
(
x
)
}
T
∇
2
f
(
x
)
{
−
[
∇
2
f
(
x
)
]
−
1
∇
f
(
x
)
}
=
∇
f
(
x
)
T
[
∇
2
f
(
x
)
]
−
1
∇
f
(
x
)
−
1
2
∇
f
(
x
)
T
{
[
∇
2
f
(
x
)
]
−
1
}
T
∇
2
f
(
x
)
[
∇
2
f
(
x
)
]
−
1
∇
f
(
x
)
=
∇
f
(
x
)
T
[
∇
2
f
(
x
)
]
−
1
∇
f
(
x
)
−
1
2
∇
f
(
x
)
T
[
∇
2
f
(
x
)
]
−
1
∇
f
(
x
)
=
1
2
∇
f
(
x
)
T
[
∇
2
f
(
x
)
]
−
1
∇
f
(
x
)
=
1
2
λ
(
x
)
2
f(x) - \hat f(x+v) = f(x) - f(x)-\nabla f{(x)^T}v - \frac{1}{2}{v^T}{\nabla ^2}f(x)v \\ =-\nabla f{(x)^T}\{- [{\nabla ^2}f{(x)]^{ - 1}}\nabla f(x) \}-\frac{1}{2}\{- [{\nabla ^2}f{(x)]^{ - 1}}\nabla f(x) \}^T {\nabla ^2}f(x)\{- [{\nabla ^2}f{(x)]^{ - 1}}\nabla f(x) \} \\ =\nabla f{(x)^T}[{\nabla ^2}f{(x)]^{ - 1}}\nabla f(x)-\frac{1}{2}\nabla f(x)^{T} \{ [{\nabla ^2}f{(x)]^{ - 1}}\}^T{\nabla ^2}f(x) [{\nabla ^2}f{(x)]^{ - 1}}\nabla f(x) \\ =\nabla f{(x)^T}[{\nabla ^2}f{(x)]^{ - 1}}\nabla f(x)-\frac{1}{2}\nabla f{(x)^T}[{\nabla ^2}f{(x)]^{ - 1}}\nabla f(x)\\ =\frac{1}{2}\nabla f{(x)^T}[{\nabla ^2}f{(x)]^{ - 1}}\nabla f(x) =\frac{1}{2}\lambda {(x)^2}
f(x)−f^(x+v)=f(x)−f(x)−∇f(x)Tv−21vT∇2f(x)v=−∇f(x)T{−[∇2f(x)]−1∇f(x)}−21{−[∇2f(x)]−1∇f(x)}T∇2f(x){−[∇2f(x)]−1∇f(x)}=∇f(x)T[∇2f(x)]−1∇f(x)−21∇f(x)T{[∇2f(x)]−1}T∇2f(x)[∇2f(x)]−1∇f(x)=∇f(x)T[∇2f(x)]−1∇f(x)−21∇f(x)T[∇2f(x)]−1∇f(x)=21∇f(x)T[∇2f(x)]−1∇f(x)=21λ(x)2
其中,第二个等号是将
v
v
v值代入进去,第三个等号涉及
(
A
B
)
T
=
B
T
A
T
(AB)^T=B^TA^T
(AB)T=BTAT矩阵转置知识,第四个等号涉及
[
∇
2
f
(
x
)
]
−
1
[{\nabla ^2}f{(x)]^{ - 1}}
[∇2f(x)]−1是一个对称阵,对称阵的转置等于其本身。因此,
1
2
λ
(
x
)
2
\frac {1}{2}\lambda {(x)^2}
21λ(x)2是对
f
(
x
)
−
f
(
x
(
k
)
)
f(x)-f(x^{(k)})
f(x)−f(x(k))的估计值,即我们可以将其作为迭代停止条件:当
1
2
λ
(
x
)
2
⩽
ε
\frac {1}{2}\lambda {(x)^2} \leqslant \varepsilon
21λ(x)2⩽ε时,说明第
k
k
k步迭代的函数与上次相比差距非常小了,迭代结果已经非常接近函数的最小值了,迭代可以停止。
——————————————————————————————
Newton 算法
(1) 给定初始点
x
∈
d
o
m
f
x \in domf
x∈domf, 误差阈值
ε
\varepsilon
ε;
(2) 计算Newton方向和步长:
Δ
x
n
t
=
−
∇
f
(
x
)
[
∇
2
f
(
x
)
]
−
1
;
\Delta {x_{nt}}=- \nabla f(x)[{\nabla ^2}f{(x)]^{ - 1}};
Δxnt=−∇f(x)[∇2f(x)]−1;
λ
(
x
)
2
=
∇
f
(
x
)
T
[
∇
2
f
(
x
)
]
−
1
∇
f
(
x
)
;
\lambda {(x)^2}=\nabla f{(x)^T}[{\nabla ^2}f{(x)] ^{ - 1}}\nabla f(x);
λ(x)2=∇f(x)T[∇2f(x)]−1∇f(x);
(3) 停止准则:如果
1
2
λ
(
x
)
2
⩽
ε
\frac {1}{2}\lambda {(x)^2} \leqslant \varepsilon
21λ(x)2⩽ε时,退出,否则进入下一步;
(4) 确定步长
t
t
t:通过线性搜索或Armijo Rule搜索;
(5) 进入下一步迭代:
x
=
x
+
t
Δ
x
n
t
x=x+t\Delta {x_{nt}}
x=x+tΔxnt
(6)重复进行直至达到停止条件。
————————————————————————————
注意:我们一般称步长
t
=
1
t=1
t=1时,为纯Newton方法。
以上就是最为基础的Newton算法的原理,可以注意到,该方法的一个主要特点是要求海塞矩阵
∇
2
f
(
x
)
{\nabla ^2}f(x)
∇2f(x)可逆,因此如果某点处的海塞矩阵是奇异矩阵(即不可逆。虽然海塞矩阵是对称阵,但其特征值并非全部都是非零的),那么该方法将会失去效用,正因为如此,才有了后续的拟Newton方法。
4. 收敛性分析
关于Newton方法的收敛性分析(此处我们需要假定函数二次连续可微且具有强凸性)比较复杂。在此,我们只给出一些直观的结论,具体证明请查找相关书籍。
在介绍收敛性结论之前,先介绍关于
L
i
p
s
c
h
i
t
z
Lipschitz
Lipschitz连续。我们说一个函数
f
f
f是以
L
L
L为常数的
L
i
p
s
c
h
i
t
z
Lipschitz
Lipschitz连续的,即
∥
f
(
x
)
−
f
(
y
)
∥
2
⩽
L
∥
x
−
y
∥
2
{\left\| {f(x) - f(y)} \right\|_2} \leqslant L{\left\| {x - y} \right\|_2}
∥f(x)−f(y)∥2⩽L∥x−y∥2对任意的
x
,
y
∈
d
o
m
f
x,y\in dom f
x,y∈domf都成立,其中
L
L
L称
L
i
p
s
c
h
i
t
z
Lipschitz
Lipschitz常数。该连续是一种比较强的连续,函数有比较好的光滑性,因为上式要求函数值得变化是缓的。对于Newton方法的收敛性分析,我们还需要假设其海塞矩阵
∇
2
f
(
x
)
{\nabla ^2}f(x)
∇2f(x)是
L
i
p
s
c
h
i
t
z
Lipschitz
Lipschitz连续的。
下面我们将说明Newton方法的收敛性结论:存在满足
0
<
η
⩽
m
2
L
0 < \eta \leqslant \frac{{{m^2}}}{L}
0<η⩽Lm2和
γ
>
0
\gamma > 0
γ>0的
η
\eta
η和
γ
\gamma
γ使下式成立:
(1)如果
∥
∇
f
(
x
(
k
)
)
∥
2
⩾
η
{\left\| {\nabla f({x^{(k)}}) } \right\|_2} \geqslant \eta
∇f(x(k))
2⩾η,则
∥
∇
f
(
x
(
k
+
1
)
)
−
f
(
x
(
k
)
)
∥
2
⩽
−
γ
{\left\| {\nabla f({x^{(k + 1)}}) - f({x^{(k)}})} \right\|_2} \leqslant - \gamma
∇f(x(k+1))−f(x(k))
2⩽−γ
(2)如果
∥
∇
f
(
x
(
k
)
)
∥
2
⩽
η
{\left\| {\nabla f({x^{(k)}}) } \right\|_2} \leqslant \eta
∇f(x(k))
2⩽η,则用Armijo搜索产生的
t
(
k
)
=
1
t^{(k)}=1
t(k)=1,且有
L
2
m
2
∥
∇
f
(
x
(
k
+
1
)
)
∥
2
⩽
(
L
2
m
2
∥
∇
f
(
x
(
k
)
)
∥
2
)
2
\frac{L}{{2{m^2}}}{\left\| {\nabla f({x^{(k + 1)}})} \right\|_2} \leqslant {\left( {\frac{L}{{2{m^2}}}{{\left\| {\nabla f({x^{(k)}})} \right\|}_2}} \right)^2}
2m2L
∇f(x(k+1))
2⩽(2m2L
∇f(x(k))
2)2
上述两个式子其实,描述了Newton方法收敛的两个阶段:第一个式子描述的是收敛速度较慢的阶段,我们一般称之为阻尼Newton阶段;第二个式子描述的是收敛速度非常快的的阶段,也我们常说的搜索点靠近最优点了,我们一般称之为二次收敛阶段,该阶段一般迭代次数大体上不会超过6次。
上述两个不等式的证明较为复杂,此处不做详细证明了。我们给出上式中一些参数的取值:
γ
=
α
β
η
2
m
M
2
\gamma = \alpha \beta {\eta ^2}\frac{m}{{{M^2}}}
γ=αβη2M2m,
η
=
min
{
1
,
3
(
1
−
2
α
)
}
m
2
L
\eta = \min \left\{ {1,3(1 - 2\alpha )} \right\}\frac{{{m^2}}}{L}
η=min{1,3(1−2α)}Lm2
其中,
α
\alpha
α和
β
\beta
β分别表示Armijo搜索方法中的两个参数,
m
m
m和
M
M
M是函数强凸性中的参数,即
m
I
≼
∇
2
f
(
x
)
≼
M
I
mI \preccurlyeq {\nabla ^2}f(x) \preccurlyeq MI
mI≼∇2f(x)≼MI;
L
L
L是
L
i
p
s
c
h
i
t
z
Lipschitz
Lipschitz常数。
————————————————————————————
总结: Newton方法的核心在于Newton方向,该方向我们可以从二阶近似的角度去推导,当步长为1时,我们称之为纯Newton方法;其次,通过收敛性分析,我们知道当搜索点靠近最优点时,Newton方法具有非常快的收敛速度(二次收敛),具有较好的性质,但同时我们也需要注意到其缺点:一是Newton方向中含有海塞矩阵的可逆矩阵,因此要求在当前点的海塞矩阵是非奇异的;二是当搜索点离最优点比较远时(即在阻尼Newton阶段),收敛速度将会非常慢(比线性收敛还慢);也正是有此缺点,才有了后续的一些拟Newton方法。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









