






项目中有时会遇到查找并删除重复记录的需求,下面谈谈如何实现
新创建一个表【item】
表结构:item_code varchar(20), value int(11), quantity int(11) where item_code is the primary key.
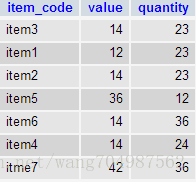
方法一:使用INNER JOIN和子查询
SELECT item_code, value, item.quantity
FROM item
INNER JOIN(
SELECT quantity
FROM item
GROUP BY quantity
HAVING COUNT(item_code) >1
)temp ON item.quantity= temp.quantity;输出结果:
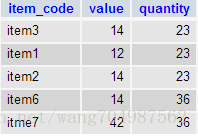
为了得到上面的结果,这里使用了INNER JOIN(内连接查询两个表中所有匹配的数据),再看一下子查询的SQL语句:
SELECT quantity
FROM item
GROUP BY quantity
HAVING COUNT(item_code) >1输出结果:

方法二:使用INNER JOIN和DISTINCT
SELECT distinct a.item_code, a.value, a.quantity
FROM item a
INNER JOIN item b ON a.quantity = b.quantity
WHERE a.item_code <> b.item_code输出结果:
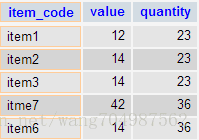
第二种方法直接使用INNER JOIN连接表item,但是使用DISTINCT去重,所以,同样能查处重复记录
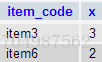
如果想按某个分类查询出重复记录的条数,SQL如下:
SELECT item_code, COUNT( quantity ) x
FROM item
GROUP BY quantity
HAVING x >1输出结果:
如果想查询重复记录的总数,SQL如下:
SELECT count(*) AS Total_duplicate_count
FROM
(SELECT item_code FROM item
GROUP BY quantity HAVING COUNT(quantity) > 1
)AS x输出结果:

说完查询,下面再来看看如何删除重复记录,大多时候,除了删除重复记录,还想保留一条记录,在测试前最好备份数据,看看如何实现
1. 如果想保留记录中id值最小的那条记录:
DELETE n1 FROM names n1, names n2 WHERE n1.id > n2.id AND n1.name = n2.name2. 如果想保留记录中id值最大的那条记录:
DELETE n1 FROM names n1, names n2 WHERE n1.id < n2.id AND n1.name = n2.name参考资料:
http://www.w3resource.com/mysql/advance-query-in-mysql/find-duplicate-data-mysql.php
http://stackoverflow.com/questions/4685173/delete-all-duplicate-rows-except-for-one-in-mysql















 1187
1187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









