







大数据技术这几年来被炒得火热,一方面也真的是数据量越来越大,传统的海量数据处理技术已经不能够满足当前的业务场景;另一反面,也是由于蕴藏在大量数据中的价值越来越引起人们的重视。
大数据技术的兴起,与人工智能技术的兴起是相辅相成的。大数据处理技术的及时、高效,更方便人工智能的网格计算,越来越多的中小型创业公司也加入了大数据圈。可能一个比较有趣的问题就是,中小型公司哪里能够获取到数据?更何谈大数据?现在的中小型企业比较热衷的方向是BI,也就是商业智能,商业智能、精准广告投递这方面中小型企业、创业公司做的还是不错的,主要是提供某种解决方案,而不是直接拿数据来解决问题。
那么,我们姑且来看看,大公司是怎么高效利用这些海量数据的,也从中,窥探一下大数据技术的“钱沿”:
1.斗鱼大数据架构
我们先来看一张,斗鱼大数据架构图:
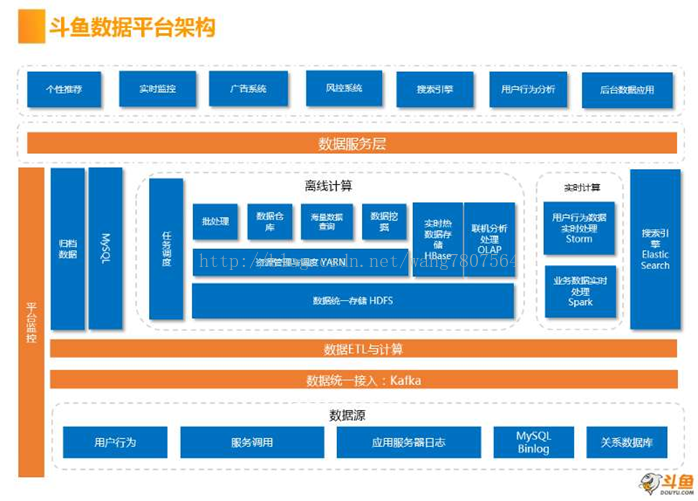
这张图是斗鱼官方提供的,不是我自己想象着画的,斗鱼数据平台部总监吴锐成曾经在文章中详细谈到过斗鱼的大数据解决方案。
我们姑且从这张图中照猫画虎,尝试着强行分析一波:
- 斗鱼的数据来源是多样的,都送到统一数据平台进行收集、分析,这些数据包括了服务器日志,MySQL的二进制日志,用户行为等,来源还是很丰富的。
- 在数据处理平台和数据源中,增加一个消息中间件,对于这种大吞吐量的场景,大数据环境用的最多的消息中间件就是kafka了,kafka的特点就是吞吐量很大,这种
- 消息队列本身就是Hadoop生态系统中的一员,在这种业务场景下,其他的诸如RM,AM这种,相对得用的要少很多。
- kafka这种消息中间件是基于zookeeper的,主要利用的就是zookeeper的一致配置等一致性特性,也就是说,kafka是一个分布式的集群,这种集群本身就自带着Zookeeper高可用的光环,在面对海量数据的业务压力时,能够从容应对。原先很多场合,都是flume+kafka这种架构模式,由flume进行数据采集,kafka承担消费者,这里面的数据源必然是一个生产者,但是具体的生产过程是怎样的在这张图中没有体现出来,可能是flume,也可能是自己开发的JAVA处理程序,也可能是其他的什么途径,这里就不猜测了。
- 在往上,就是对来自Kafka的数据进行一个数据清理,这当然是用ETL经典的解决方案,没有问题。
- 斗鱼的数据处理层还是很经典的:离线计算,流式计算,归档和MySQL持久化数据。
- 在离线处理这部分,就是使用经久不衰的Hadoop解决方案,HDFS+YARN+spark这种,然后,就可以对数据进行一个离线的数据挖掘。
- 在流式数据处理中,斗鱼的技术栈将Storm和Spark streaming都用上了,可能也是跟自己的业务场景比较复杂有关,对于一般的公司,业务场景也比较简单,Storm还是
- Spark streaming很容易就可以选择出来了,其实,在很多情境下,大部分的中小型公司这两个方案差别不是很大。
- 在这个比较经典的数据平台上,在搭建一个运维系统,这个运维系统应该是自行研制的,大家可以在左侧看到这个运维系统。
- 就这个大数据处理平台来看,还是中规中矩的,同时,也看到了斗鱼的技术栈确实比较全面,也从侧面看到了斗鱼的业务场景确实不是单一的,还是比较复杂的。
应用这些大数据的能够解决的问题当然也很多了:
斗鱼房间观众这么多,键盘侠这么多,不监控一下怎么能行;主播不老实,表演一下黄鳝还得了?监控下黑卡刷鱼丸神马的~斗鱼在这个技术栈里面,可能还会包含一些图计算之类的小众应用场景,但是,对外并没有过明确的公布,这里我们也不去妄加推测。














 1568
1568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









