







static c array = boost array
dynamic c array = stl vector
最近用vector代替c arrays,效率变差了好几倍,查到下面一篇很好的文章,从文章中我们可以得到一些很重要的结论
如果是出于效率考虑
1 如果有海量的小数组,请不要使用vector, 因为在此的效率影响很大, 直接放到stack里。
2 如果没有安全考虑,用动态的c array代替大量数据的vector。
Inserting and retrieving elements in an STL vector is just as fast as doing it ina regular plain C array. This of course requires that you have turn on optimization.
However a STL vector has a number of attributes which potentially makes it slower than a C array:
-
A vector does not store its data in a continuous chunk of memory. Pointers to the start and end of the vector will be stored in a different location from the data itself.
-
An STL vector always allocates memory for its data on the heap. Heap allocation is slower than stack allocation.
To test how this would work in practice I created a program that would iterate over a large array, do some calculations on it and return small parts of it into either a plain C array or a STL vector.
for (int k = 0; k < rep; ++k) {
for (int i = 0; i < count; i += inc) {
double buffer[inc];
base->GetData(Range(i, i + inc - 1), buffer);
}
}
base is an object containing and array of data. We access parts of this array by specifying a range. The data in the range is returned inbuffer. To test the STL vector we use this code in the inner loop instead>
vector<double> buffer(inc);
base->GetData(Range(i, i + inc - 1), buffer.begin());
A simple calculation is performed on each element
void Data::GetData(Range r, double *buffer) {
double *p = d + r.min;
double *q = d + r.max + 1;
while (p != q) {
double a = ((*p)+3) * (*p) + 4; // simple calc
*buffer++ = a;
++p;
}
}
The rep variable is used to perform everything several times over so that the cache will be warmed up.inc defines the size of the buffer used to store results from GetData.count is the total number of element. In all the tests we have kept count to a constant of 1 million double values. By varying the size inc of the buffer we get these results:
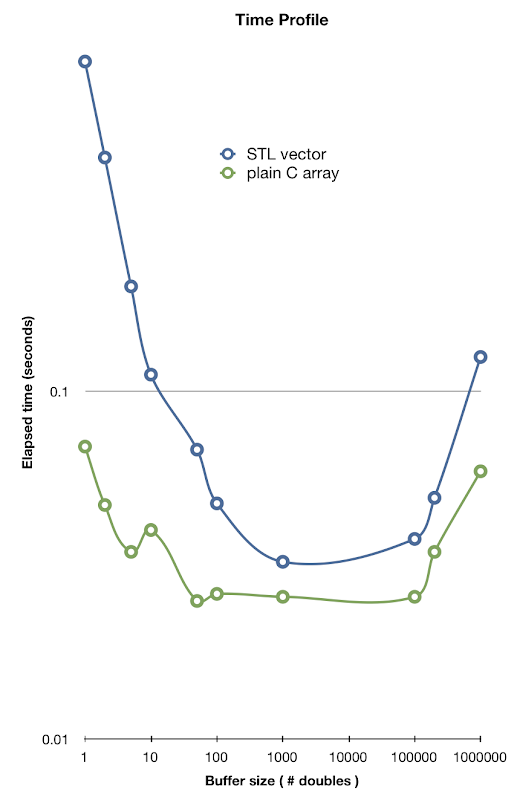
The scale is logarithmic along X and Y axis. At low buffer size we get an overhead in the virtual function call for the C array buffer. That is why larger buffers give better performance. However only buffers of 5-10 in size is needed for maximum performance. For STL vector we need buffers with size 1000 before we get comparable performance to plain C array. The reason for this is the overhead of the memory allocation and deallocation on the heap. This creates a very high overhead for small buffer sizes.
As the buffers get above 150 000 elements we see performance degrading again. This is likely because at that size the buffers can not fit into the cache. With smaller buffer sizes both the array and vector version will typically reuse the same memory already present on the stack. I tried printing out the address of the arrays allocated for STL vector and for small arrays we get the same address each time. This means that at each loop iteration we can reuse memory already in cache to write to.
Bottom line is:
-
At very small buffer sizes (1-5) overhead of function call (virtual) is noticeable.
-
At small buffers sizes (1 - 1000) we have overhead of memory allocation and deallocation for STL vector.
-
For large buffers we get overhead of cache misses
http://assoc.tumblr.com/post/411601680/performance-of-stl-vector-vs-plain-c-arrays















 1839
1839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









