




js刷Leecode时常用到的数据结构和内置方法以及一些常见的算法 …持续更新中…
1. js的sort()方法
首先sort()若无参数,则是按照字母顺序进行排序
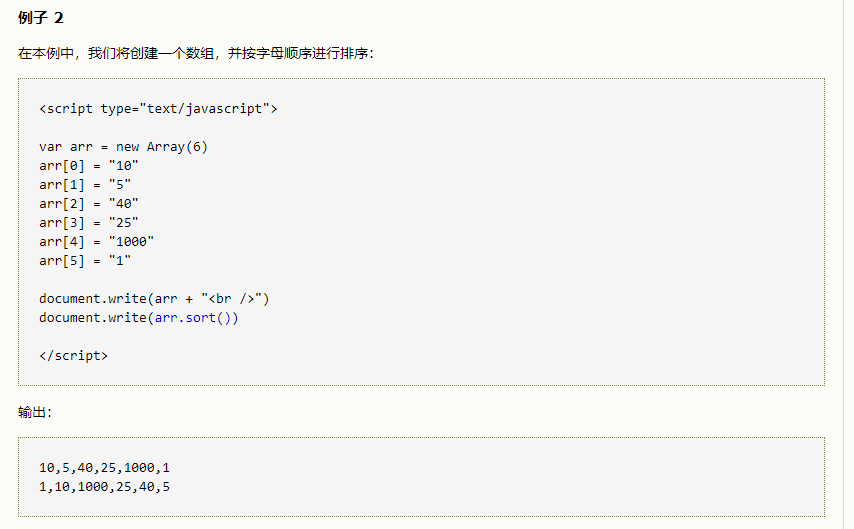
若对数字进行从小到大进行排序,则必须传入一个排序函数:
var arr = new Array(6)
arr[0] = "10"
arr[1] = "5"
arr[2] = "40"
arr[3] = "25"
arr[4] = "1000"
arr[5] = "1"
arr.sort((a,b)=>{
return a-b; //从小到大进行排序
return b-a; //从大到小进行排序
});
2.什么是 for…of 循环 for…in循环
for...of 语句创建一个循环来迭代可迭代的对象。在 ES6 中引入的 for...of 循环,以替代 for...in 和 forEach() ,并支持新的迭代协议。for...of 允许你遍历 Arrays(数组), Strings(字符串), Maps(映射), Sets(集合)等可迭代的数据结构等。
语法
for (variable of iterable) {
statement
}
- variable:每个迭代的属性值被分配给该变量。
- iterable:一个具有可枚举属性并且可以迭代的对象。
// array-example.js
const iterable = ['mini', 'mani', 'mo'];
for (const value of iterable) {
console.log(value);
}
// Output:
// mini
// mani
// mo
for…in遍历的变量是数组的索引
var mycars = ["Saab", "Volvo", "BMW"];
mycars.color = "white"
for (var x in mycars)
{
console.log(mycars[x]);
}
2.map()方法
//返回一个新数组
let arr1 = arr.map(el=>{
return el*el;
})
//返回一个新对象
let obj1 = obj.map(()=>{
return {
name:"",
id:""
}
})
3.let和var的区别
建议,一般在写算法题时,一般都用let不用var
1、作用域不同
var是函数作用域,let是块作用域。
在函数中声明了var,整个函数内都是有效的,比如说在for循环内定义的一个var变量,实际上其在for循环以外也是可以访问的
而let由于是块作用域,所以如果在块作用域内定义的变量,比如说在for循环内,在其外面是不可被访问的,所以for循环推荐用let
2、let不能在定义之前访问该变量,但是var可以。
let必须先声明,在使用。而var先使用后声明也行,只不过直接使用但没有定义的时候,其值是undefined。var有一个变量提升的过程,当整个函数作用域被创建的时候,实际上var定义的变量都会被创建,并且如果此时没有初始化的话,则默认为初始化一个undefined
3、let不能被重新定义,但是var是可以的
4,js中的除法不是结果不是整数
比如 3/2=1.5.
在js中一般用右移运算符 3>>1 结果就是1
当然也可以使用parseInt函数,比如:parseInt(3/2);其就是一个整数1
5.js中创建二维数组
js不能使用 let arr = new Array[2][2];来创建数组
正确写法:
方法一:创建一个n*n数组
let nums = new Array(n); //先创建一个一维数组
//在一维数组的每一个元素都是一个n为数组
for (let i = 0; i < n; i++) {
nums[i] = new Array(n);
}
方法二:
let towMetric = new Array(5).fill(0).map(ele=>new Array(5).fill(0)); //创建一个5行5列的二维数组
6.数组的一些函数
reverse()函数
//reverse()
let arr = [ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











