







问题一:连接池泄漏
看到这个问题,我想很多人都说,都什么年代了,使用开源的现成连接池,怎么还会有这样的问题,又不是那些使用jdbc的年代了。那来看看现象吧。
场景:测试部用loadRunner往死里压,发现很多业务对象不断增长,但是按照业务场景来说,这些业务对象处理以后就自动释放了。(在本地的开发环境验证了是会自动释放的)
JProfiler截图:
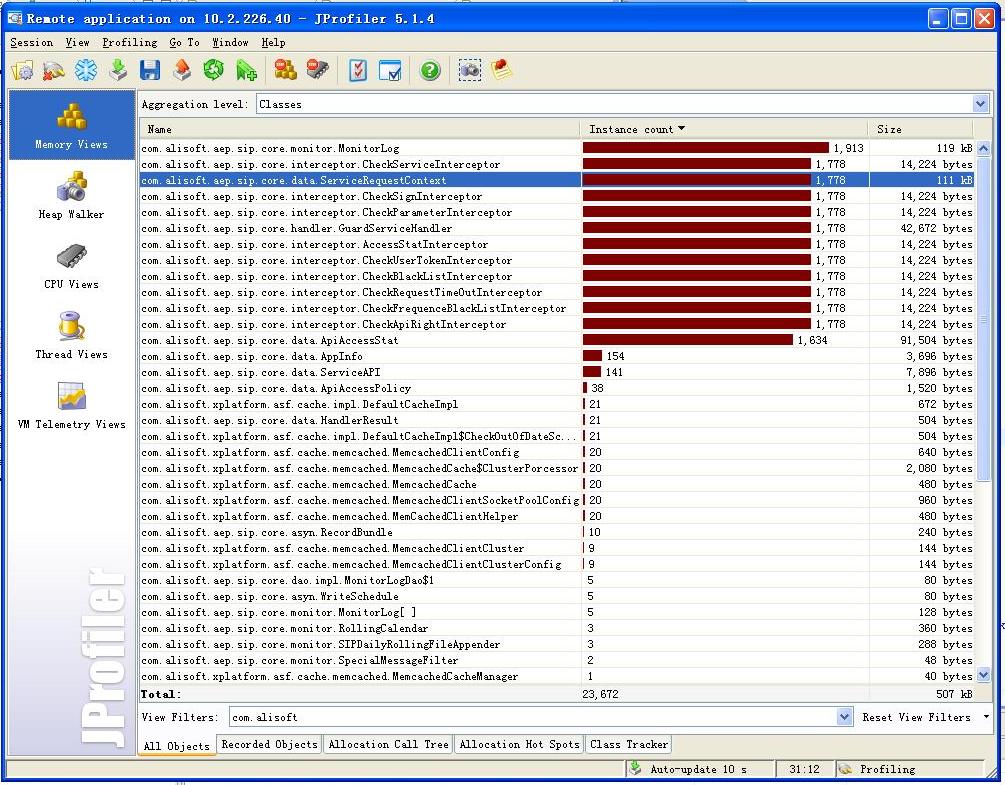
上图中可以看到有很多业务对象已经累积占用了不少内存,在让测试部同学停掉压力测试以后,等待了一会儿,然后用JProfiler主动发起垃圾回收,也看到了Jboss后台有GC回收的记录输出以后,发现这些对象依然存在,也就是说这些对象成为了Memory泄漏的诱因之一。但是就如我所说的,在本地测试以及白盒测试来看,这些对象在一次请求以后,处理完毕一定会被释放,没有被其他Map等Reference,然后通过JProfiler看了看这些对象的Allocation Call Tree,就是我们处理请求的Servlet作为源头的,但为什么Servlet没有被清理掉呢?接着来看看后面二张图
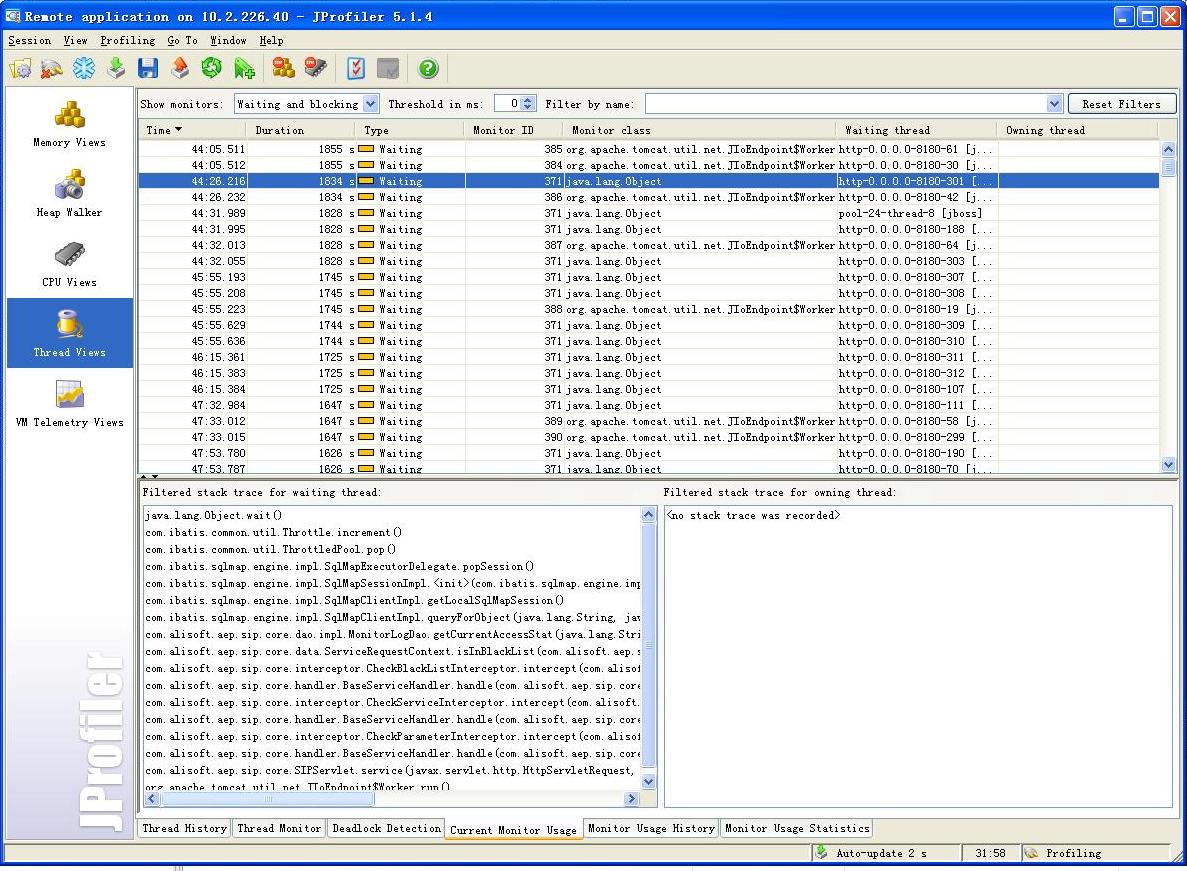
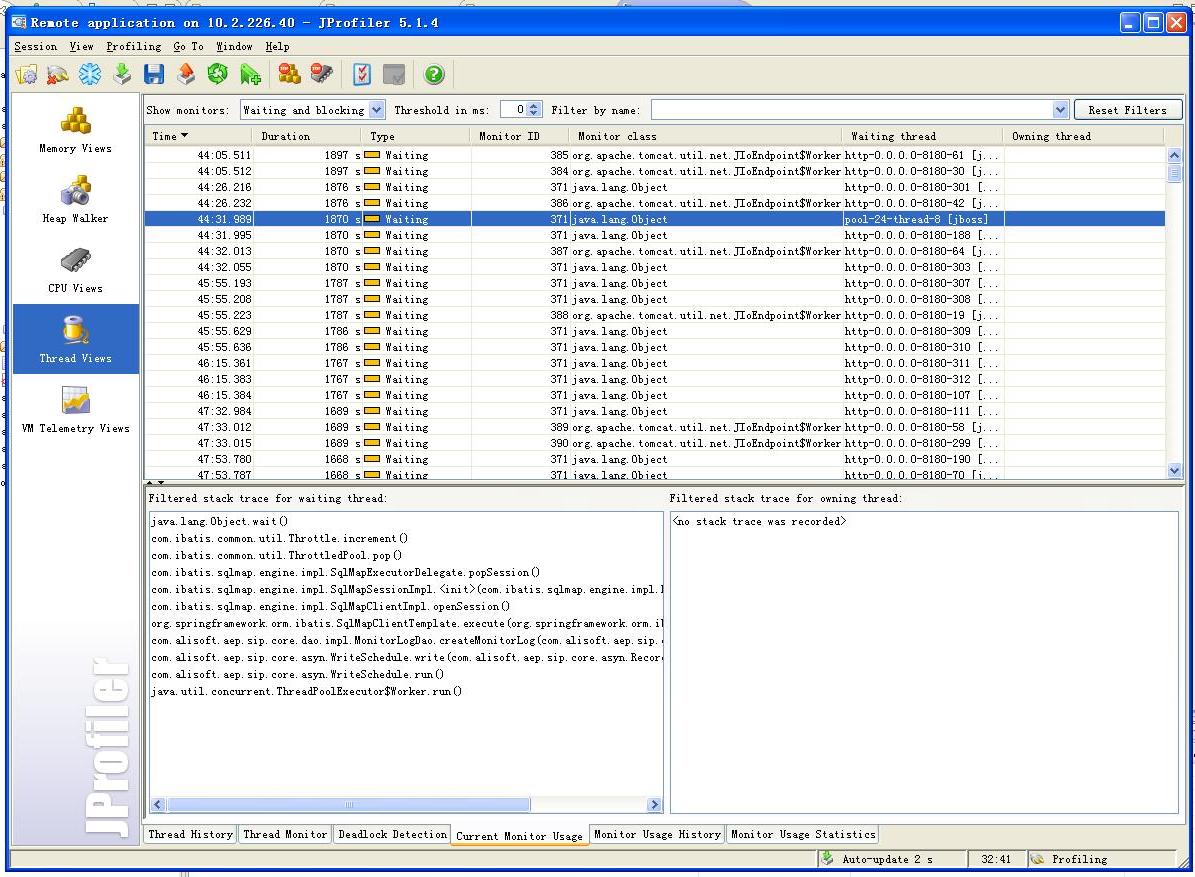 既然知道对象存在并且被Hold了,那么就去看看线程运行的状况,这一看发现有很多线程都处于Wait的状态(其实在server作dump也可以看到),这张图上就可以看到,我选择了其中一个wait的线程它处于等待状态的原因就是在ibatis的Throttle作increment的时候处于等待状态,看了看ibatis的代码,这部分代码其实是ibatis连接池的一段代码,在连接池被占满以后,处于等待释放的状态,也就是说程序把连接池耗尽了。
既然知道对象存在并且被Hold了,那么就去看看线程运行的状况,这一看发现有很多线程都处于Wait的状态(其实在server作dump也可以看到),这张图上就可以看到,我选择了其中一个wait的线程它处于等待状态的原因就是在ibatis的Throttle作increment的时候处于等待状态,看了看ibatis的代码,这部分代码其实是ibatis连接池的一段代码,在连接池被占满以后,处于等待释放的状态,也就是说程序把连接池耗尽了。
为了验证是否是耗尽了,让DBA老大光辉给我看了看MySql(这部分当天的日志数据都保存在MySql中)的连接情况,发现只有8个连接,看来不是真的耗尽,应该是连接池泄露了。光辉告诉我,这八个连接都在做同一个查询,就是统计某一个API的访问记录次数和流量。在当前的业务流程中对于MySql主要做了两类操作:
1.访问控制计数器创建的统计查询。
由于要对Open API访问控制,采用了Memcache计数器方式来实现。当发现此类API没有创建过计数器,那么就分析MySql中的数据,创建计数器,后续的访问记录除了插入数据库以外还需要累加计数器,这样访问控制可以高效使用集中式计数器而不需要查询数据库。
2.日志批量异步写入。
对于Open API的记录采用了线程池中每一个线程维护一个内存分页,当页满或者到了刷新间隔时,一次性批量写入数据库,缓解数据库写入压力,这里采用了事务来批量提交。
对于第一种操作,由于设计中MySql就只会保留当天的数据量,因此只有系统启动的时候做一次统计,对于数据库压力和Sql执行来说应该没有太大的压力,但是由于压力测试是从昨天下午就开始做的,里面的数据已经有上千万,因此这次重新启动开始做压力测试,导致了这个创建计数器的Sql执行很慢。同时日志的批量写入采用的是事务方式来提交,对于MySql其实自己还不是很深入,但是感觉上来说,问题应该出现在这里,由于查询的缓慢在加上事务批量的提交,可能会造成事务失败,同时没有正确的将释放资源的信号传递给ibatis,导致了看起来的连接资源耗尽。
我将数据库中的记录全部删除,然后重新启动,开始压力测试,问题不存在了,对象都及时得到回收。后续还会去跟进这个问题,在ibatis早期版本,同样是这个类出现了死锁的问题,后来升级得到了解决,但是也看到很多国外的朋友说道2.2和2.3其实还是有死锁的问题,不过我个人觉得可能还是和数据库也有一定关系。
疑问:
这个问题的背后我还有一点疑问,对于我们来说,如果一个普通的http请求,当超时以后肯定就会自动中断,但是在这个场景中,我足足等了1个小时还是没有释放,也就是说客户端其实已经断开了,但是JBoss好像并不会释放这些处理请求的事务,导致资源被卡。
问题二:LinkedBlockingQueue惹祸
自从Jdk1.5以后concurrent包为大家提供了很多便利高效的开发新模式,我在不少地方用到了LinkedBlockingQueue,作为消费者和生产者之间的数据通道,消费者们等待在LinkedBlockingQueue门口守候生产者提供数据,获取数据后就开始并行处理。这里我会采用queue.poll(100,TimeUnit.MILLISECONDS)这种方式来半阻塞的获取数据。其实在昨天已经听说LinkedBlockingQueue可能存在着内存泄露的问题,看了看很多网上的人也都提到了这个问题,在1.5种没有得到解决,在1.6中会去fix这个问题,但是没有证据,也不好乱加断定。在问题一搞好以后,然后继续查找潜在bug,这时候不经意的发现有一个对象随着时间的推移始终在增加,但是由于单个对象占的内存不大,因此没有很明显的体现出来,但是对象实例的增加却是很明显的,看看下面两张图:
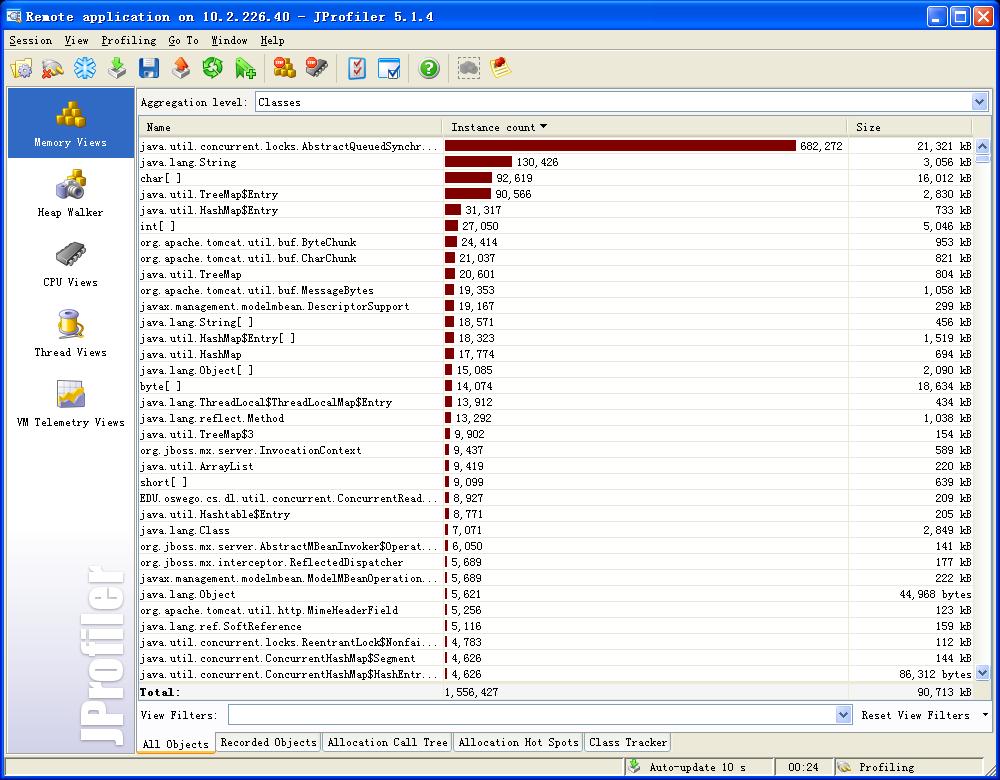
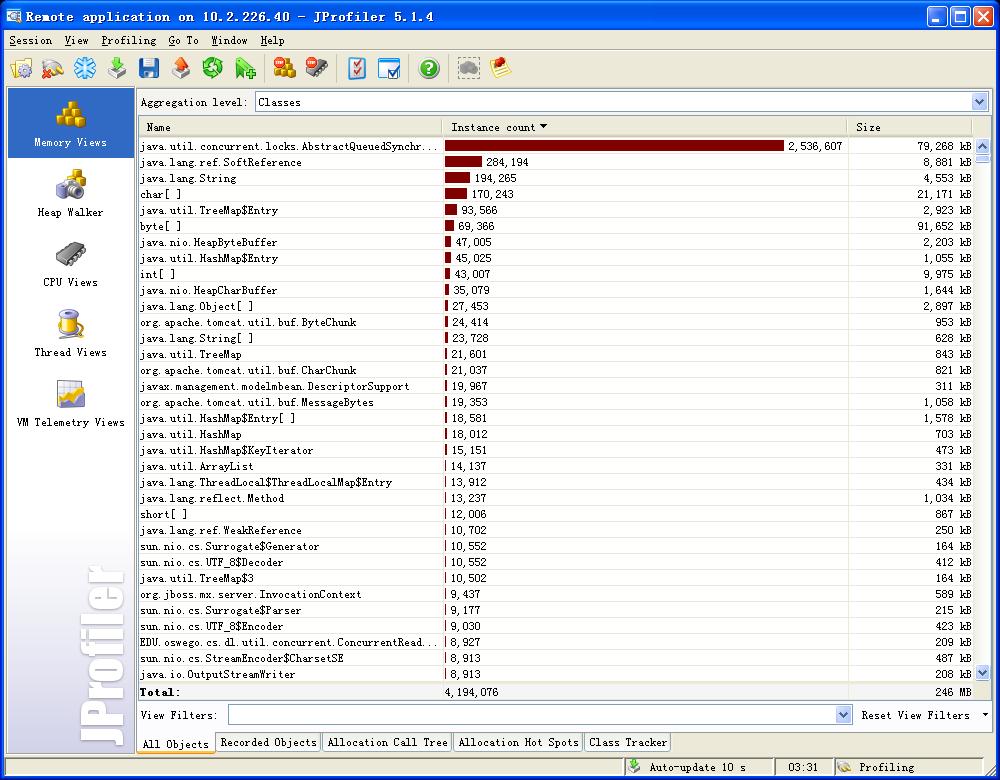 这两张图的间隔时间2小时左右,可以发现这个对象的instance已经有了很大的增长,同时内存也吃了不少,看了看创建这个对象的Tree,发现就是poll这个方法,也就是我线程池中线程周期性扫描的结果。这期间没有任何访问,仅仅就是放着不动,就有如此大量的增长。我尝试将poll(100,TimeUnit.MILLISECONDS)换成poll()全阻塞方式,对象增长依旧。因此可以看出来服务器的Memory Leak很大程度上由这部分引起,早先没有发现,因为是SIP上线不久,没有太多用户,而这阵子用户越来越多,加上API中的更新类请求比较吃内存,就容易发现此类问题。
这两张图的间隔时间2小时左右,可以发现这个对象的instance已经有了很大的增长,同时内存也吃了不少,看了看创建这个对象的Tree,发现就是poll这个方法,也就是我线程池中线程周期性扫描的结果。这期间没有任何访问,仅仅就是放着不动,就有如此大量的增长。我尝试将poll(100,TimeUnit.MILLISECONDS)换成poll()全阻塞方式,对象增长依旧。因此可以看出来服务器的Memory Leak很大程度上由这部分引起,早先没有发现,因为是SIP上线不久,没有太多用户,而这阵子用户越来越多,加上API中的更新类请求比较吃内存,就容易发现此类问题。
那么是否1.6就解决了这个问题呢,开始使用机器上1.6_01的版本,发现问题依旧,去sun下载了最新的1.6_07,发现的却会回收,但是回收和增长都存在,具体数据描述举例如下:
1. 1000 instance 31k
2. 200 instance 6k (回收了一部分)
3. 1500 instance 46k(发现增长的比以前还多)
4. 300 instance 9k (回收了一部分)
5. 2000 instance 62k (发现增长的比以前还多)
也就是说,回收时有发生,但是总体趋势还是在上升,这个真的还需要好好测试,有兴趣的同学也可以试验一下我的测试方式,就仅仅只需要使用一个LinkedBlockingQueue,然后定时的去pool,1.5绝对增长的不小。
对于这个问题,我只能再去验证,如果发现真的暂时不可避免,那么只有考虑替代方案了。
这是今天作了Memory Leak的一些分享,希望也能给其他遇到或者将会遇到问题的同学一个分享,说一句,如果有条件的话用JProfiler去分析性能绝对是不错的,没有条件么就dump,gc输出来查找问题。
今天早晨看到有个朋友给我留了言,说到用take方法来替换poll方法,原先我只是看中了poll的timeout,其实在现在的场景用take也可以满足,早晨测试了一下,take完全没有那个问题,因此还是把poll替换成为了take。

















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









