








 超级会员免费看
超级会员免费看

 本文深入探讨了Linux内核协议栈中TCP层的TSO(TCP Segmentation Offload)和GSO(Generic Segmentation Offload)机制,分析了它们的基本概念、TCP延迟分段判定过程,以及在数据发送路径上的处理。TSO和GSO旨在减少CPU资源消耗,通过硬件或软件延迟分段提高网络传输效率。
本文深入探讨了Linux内核协议栈中TCP层的TSO(TCP Segmentation Offload)和GSO(Generic Segmentation Offload)机制,分析了它们的基本概念、TCP延迟分段判定过程,以及在数据发送路径上的处理。TSO和GSO旨在减少CPU资源消耗,通过硬件或软件延迟分段提高网络传输效率。
目录
TSO相关的内容充斥着TCP的整个发送过程,弄明白其机制对理解TCP的发送过程至关重要。
1 基本概念
我们知道,网络设备一次能够传输的最大数据量就是MTU,即IP传递给网络设备的每一个数据包不能超过MTU个字节,IP层的分段和重组功能就是为了适配网络设备的MTU而存在的。从理论上来讲,TCP可以不关心MTU的限定,只需要按照自己的意愿随意的将数据包丢给IP,是否需要分段可以由IP透明的处理,但是由于TCP是可靠性的流传输,如果是在IP层负责传输那么由于仅有首片的IP报文中含有TCP,后面的TCP报文如果在传输过程中丢失,通信的双方是无法感知的,基于此TCP在实现时总是会基于MTU设定自己的发包大小,尽量避免让数据包在IP层分片,也就是说TCP会保证一个TCP段经过IP封装后传给网络设备时,数据包的大小不会超过网络设备的MTU。
TCP的这种实现会使得其必须对用户空间传入的数据进行分段,这种工作很固定,但是会耗费CPU时间,所以在高速网络中就想优化这种操作。优化的思路就是TCP将大块数据(远超MTU)传给网络设备,由网络设备按照MTU来分段,从而释放CPU资源,这就是TSO(TCP Segmentation Offload)的设计思想。
显然,TSO需要网络设备硬件支持。更近一步,TSO实际上是一种延迟分段技术,延迟分段会减少发送路径上的数据拷贝操作,所以即使网络设备不支持TSO,只要能够延迟分段也是有收益的,而且也不仅仅限于TCP,对于其它L4协议也是可以的,这就衍生出了GSO(Generic Segmentation Offload)。这种技术是指尽可能的延迟分段,最好是在设备驱动程序中进行分段处理,但是这样一来就需要修改所有的网络设备驱动,不太现实,所以再提前一点,在将数据递交给网络设备的入口处由软件进行分段(见dev_queue_xmit()),这正是Linux内核的实现方式。
关于TSO/GSO两个字段的详细介绍参见:TSO GSO - codestacklinuxer - 博客园
2 TCP延迟分段判定
对于TCP来讲,无论最终延迟分段是由TSO(网络设备)实现,还是由软件来实现(GSO),TCP的处理都是一样的。下面来看看TCP到底是如何判断自己是否可以延迟分段的。
static inline int sk_can_gso(const struct sock *sk)
{
//实际上检查的就是sk->sk_route_caps是否设定了sk->sk_gso_type能力标记
return net_gso_ok(sk->sk_route_caps, sk->sk_gso_type);
}
static inline int net_gso_ok(int features, int gso_type)
{
int feature = gso_type << NETIF_F_GSO_SHIFT;
return (features & feature) == feature;
}
sk_route_caps字段代表的是路由能力;sk_gso_type表示的是L4协议期望底层支持的GSO技术。这两个字段都是在三次握手过程中设定的,客户端和服务器端的初始化分别如下。
2.1 客户端初始化
客户端是在tcp_v4_connect()中完成的,相关代码如下:
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
...
//设置GSO类型为TCPV4,该类型值会体现在每一个skb中,底层在
//分段时需要根据该类型区分L4协议是哪个,以做不同的处理
sk->sk_gso_type = SKB_GSO_TCPV4;
//见下面
sk_setup_caps(sk, &rt->u.dst);
...
}
2.2 服务器端初始化
服务器端是在收到客户端传来的ACK后即三次握手的最后一步,会新建一个sock并进行的初始化,相关代码如下:
struct sock *tcp_v4_syn_recv_sock(struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct dst_entry *dst)
{
...
//同上
newsk->sk_gso_type = SKB_GSO_TCPV4;
sk_setup_caps(newsk, dst);
...
}
2.3 sk_setup_caps()
设备和路由是相关的,L4协议会先查路由,所以设备的能力最终会体现在路由缓存中,sk_setup_caps()就是根据路由缓存中的设备能力初始化sk_route_caps字段。
enum {
SKB_GSO_TCPV4 = 1 << 0,
SKB_GSO_UDP = 1 << 1,
/* This indicates the skb is from an untrusted source. */
SKB_GSO_DODGY = 1 << 2,
/* This indicates the tcp segment has CWR set. */
SKB_GSO_TCP_ECN = 1 << 3,
SKB_GSO_TCPV6 = 1 << 4,
};
#define NETIF_F_GSO_SHIFT 16
#define NETIF_F_GSO_MASK 0xffff0000
#define NETIF_F_TSO (SKB_GSO_TCPV4 << NETIF_F_GSO_SHIFT)
#define NETIF_F_UFO (SKB_GSO_UDP << NETIF_F_GSO_SHIFT)
#define NETIF_F_TSO_ECN (SKB_GSO_TCP_ECN << NETIF_F_GSO_SHIFT)
#define NETIF_F_TSO6 (SKB_GSO_TCPV6 << NETIF_F_GSO_SHIFT)
#define NETIF_F_GSO_SOFTWARE (NETIF_F_TSO | NETIF_F_TSO_ECN | NETIF_F_TSO6)
void sk_setup_caps(struct sock *sk, struct dst_entry *dst)
{
__sk_dst_set(sk, dst);
//初始值来源于网络设备中的features字段
sk->sk_route_caps = dst->dev->features;
//如果支持GSO,那么路由能力中的TSO标记也会设定,因为对于L4协议来讲,
//延迟分段具体是用软件还是硬件来实现自己并不关心
if (sk->sk_route_caps & NETIF_F_GSO)
sk->sk_route_caps |= NETIF_F_GSO_SOFTWARE;
//支持GSO时,sk_can_gso()返回非0。还需要对一些特殊场景判断是否真的可以使用GSO
if (sk_can_gso(sk)) {
//只有使用IPSec时,dst->header_len才不为0,这种情况下不能使用TSO特性
if (dst->header_len)
sk->sk_route_caps &= ~NETIF_F_GSO_MASK;
else
//支持GSO时,必须支持SG IO和校验功能,这是因为分段时需要单独设置每个
//分段的校验和,这些工作L4是没有办法提前做的。此外,如果不支持SG IO,
//那么延迟分段将失去意义,因为这时L4必须要保证skb中数据只保存在线性
//区域,这就不可避免的在发送路径中必须做相应的数据拷贝操作
sk->sk_route_caps |= NETIF_F_SG | NETIF_F_HW_CSUM;
}
}
上述代码中涉及到的几个能力的含义如下表所示:
| 能力 | 值 | 描述 |
|---|---|---|
| NETIF_F_GSO | 0x0000 0800 | 如果软件实现的GSO打开,设置该标记。在高版本内核中,该值在register_netdevice()中强制打开的 |
| NETIF_F_TSO | 0x0001 0000 | 网络设备如果支持TSO over IP,设置该标记 |
| NETIF_F_TSO_ECN | 0x0008 0000 | 网络设备如果支持设置了ECE标记的TSO,设置该标记 |
| NETIF_F_TSO6 | 0x0010 0000 | 网络设备如果支持TSO over IPv6,设置该标记 |
3 整体结构
TSO的处理会影响整个数据包发送路径,不仅仅是TCP层,下面先看一个整体的结构图,然后分析下TCP层发送路径上对TSO的处理,其它协议层的处理待后续补充。
注:图片来源于:linux tcp GSO和TSO实现 - yilong316 - 博客园
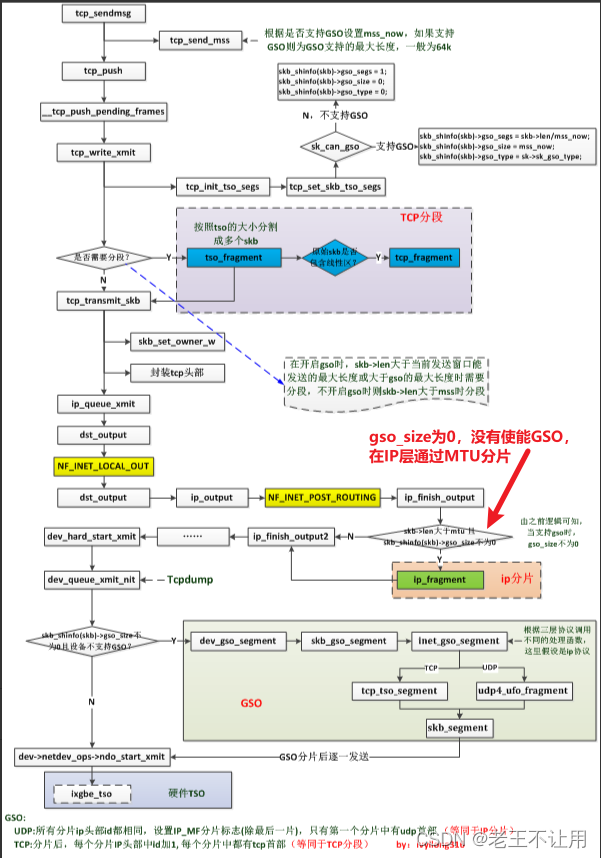
如上图所示,在TCP的发送路径上,有如下几个点设计TSO的处理:
- tcp_sendmsg() 中调用tcp_current_mss()确定一个skb最多可以容纳多少数据量,即确定tp->xmit_size_goal;该值就是GSO的大小通常为MSS的整数倍
- tcp_write_xmit() 中调用tcp_init_gso_segs()设置skb中GSO字段,底层软件或者网卡将根据这些信息进行分段处理;
- 用 tso_fragment() 对数据包进行分段,见《linux内核协议栈 TCP层数据发送之发送新数》。
- 上面的流程图基于的内核版本为2.6.32,且在 ip_finish_output 中 ip_fragment 的调用逻辑笔误应该是 skb_is_gso 为 0,即不支持GSO在ip层通过MTU进行分片;skb_is_gso 不为 0,即支持GSO,在抽象设备层(net_device)分片(即进入网卡驱动前),代码如下:
//内核版本:2.6.32
static int ip_finish_output(struct sk_buff *skb)
{
#if defined(CONFIG_NETFILTER) && defined(CONFIG_XFRM)
/* Policy lookup after SNAT yielded a new policy */
if (skb_dst(skb)->xfrm != NULL) {
IPCB(skb)->flags |= IPSKB_REROUTED;
return dst_output(skb);
}
#endif
if (skb->len > ip_skb_dst_mtu(skb) && !skb_is_gso(skb))
return ip_fragment(skb, ip_finish_output2);
else
return ip_finish_output2(skb);
}在最新的内核版本 5.10.59 中gso的分片逻辑在 ip_finish_output_gso 中 实现
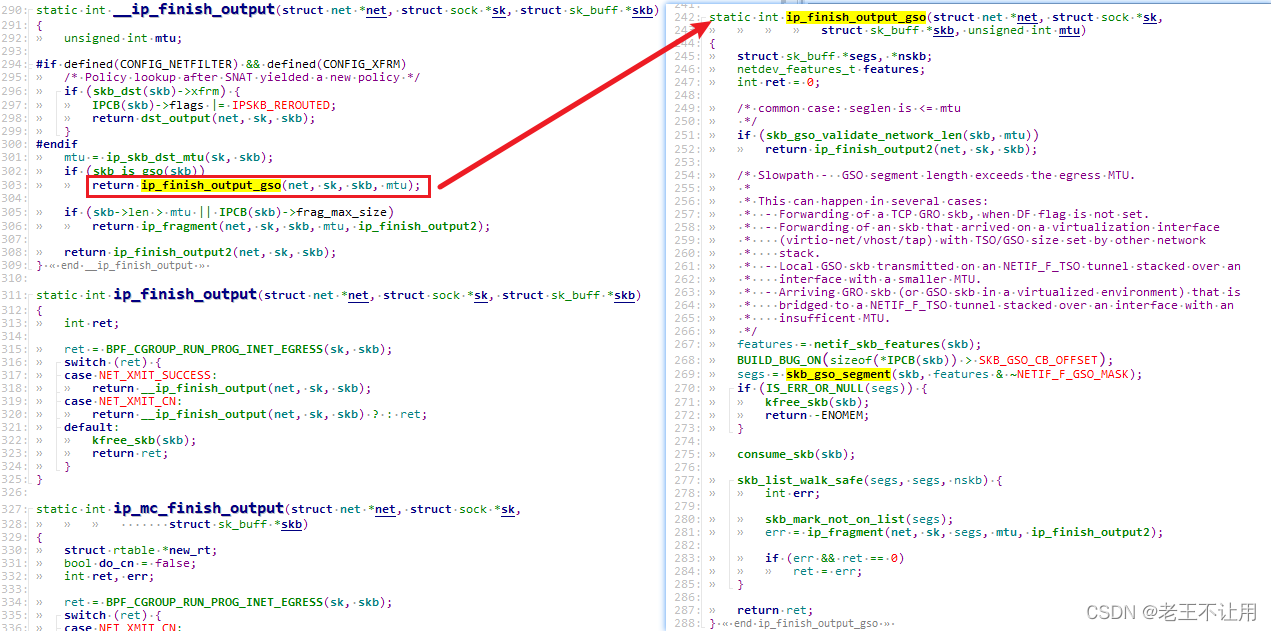
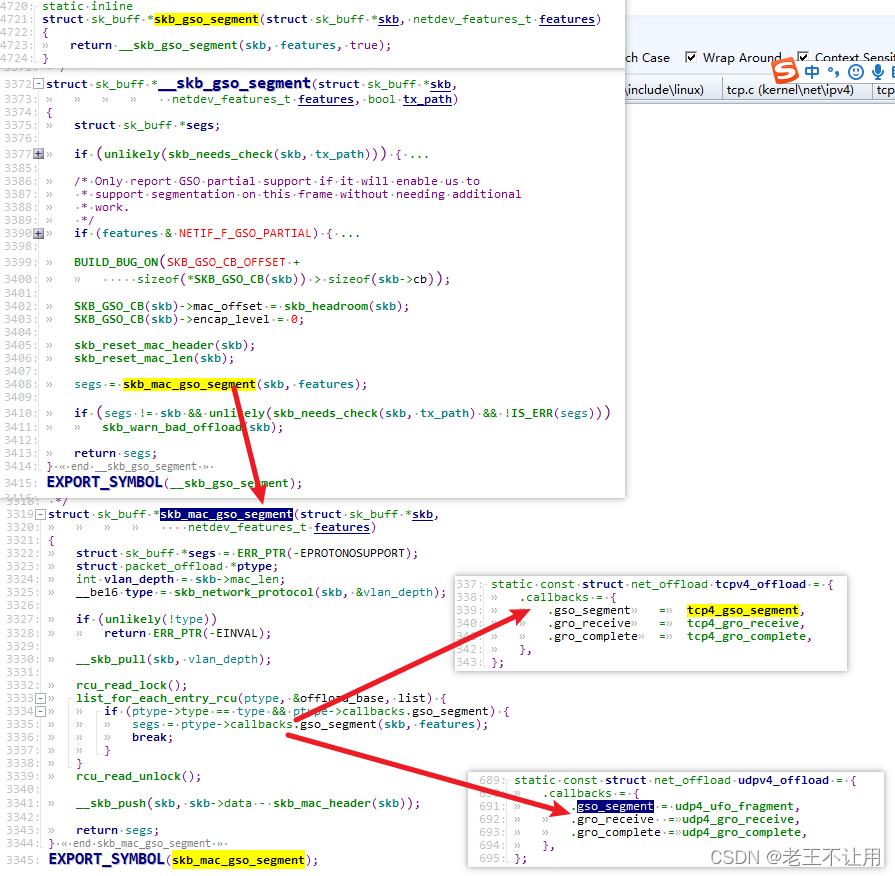
skb_gso_segment 函数的调用栈如下:
4. TCP发送路径TSO处理
4.1 tcp_sendmsg()
首先是 tcp_sendmsg(),该函数负责将用户空间的数据封装成一个个的skb,所以它需要要知道每个skb应该要容纳多少的数据量,这是通过tcp_current_mss()设定的,代码如下:
int tcp_sendmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg,
size_t size)
{
...
//tcp_current_mss()中会设置tp->xmit_size_goal
mss_now = tcp_current_mss(sk, !(flags&MSG_OOB));
//size_goal就是本次发送每个skb可以容纳的数据量,它是mss_now的整数倍,
//后面tcp_sendmsg()在组织skb时,就以size_goal为上界填充数据
size_goal = tp->xmit_size_goal;
...
}
4.1.1 tcp_current_mss
//在"TCP选项之MSS"笔记中已经分析过该函数确定发送MSS的部分,这里重点关注tp->xmit_size_goal的部分
unsigned int tcp_current_mss(struct sock *sk, int large_allowed)
{
struct tcp_sock *tp = tcp_sk(sk);
struct dst_entry *dst = __sk_dst_get(sk);
u32 mss_now;
u16 xmit_size_goal;
int doing_tso = 0;
mss_now = tp->mss_cache;
//不考虑MSG_OOB相关,从前面的介绍中我们可以知道都是支持GSO的
if (large_allowed && sk_can_gso(sk) && !tp->urg_mode)
doing_tso = 1;
//下面三个分支是MSS相关
if (dst) {
u32 mtu = dst_mtu(dst);
if (mtu != inet_csk(sk)->icsk_pmtu_cookie)
mss_now = tcp_sync_mss(sk, mtu);
}
if (tp->rx_opt.eff_sacks)
mss_now -= (TCPOLEN_SACK_BASE_ALIGNED +
(tp->rx_opt.eff_sacks * TCPOLEN_SACK_PERBLOCK));
#ifdef CONFIG_TCP_MD5SIG
if (tp->af_specific->md5_lookup(sk, sk))
mss_now -= TCPOLEN_MD5SIG_ALIGNED;
#endif
//xmit_size_goal初始化为MSS
xmit_size_goal = mss_now;
//如果支持TSO,则xmit_size_goal可以更大
if (doing_tso) {
//65535减去协议层的头部,包括选项部分
xmit_size_goal = (65535 -
inet_csk(sk)->icsk_af_ops->net_header_len -
inet_csk(sk)->icsk_ext_hdr_len -
tp->tcp_header_len);
//调整xmit_size_goal不能超过对端接收窗口的一半
xmit_size_goal = tcp_bound_to_half_wnd(tp, xmit_size_goal);
//调整xmit_size_goal为MSS的整数倍
xmit_size_goal -= (xmit_size_goal % mss_now);
}
//将确定的xmit_size_goal记录到TCB中
tp->xmit_size_goal = xmit_size_goal;
return mss_now;
}
/* Bound MSS / TSO packet size with the half of the window */
static int tcp_bound_to_half_wnd(struct tcp_sock *tp, int pktsize)
{
//max_window为当前已知接收方所拥有的最大窗口值,这里如果参数pktsize超过
//了接收窗口的一半,则调整其大小最大为接收窗口的一半
if (tp->max_window && pktsize > (tp->max_window >> 1))
return max(tp->max_window >> 1, 68U - tp->tcp_header_len);
else
//其余情况不做调整
return pktsize;
}
4.2 tcp_write_xmit()
static int tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle)
{
...
unsigned int tso_segs;
while ((skb = tcp_send_head(sk))) {
...
//用MSS初始化skb中的gso字段,返回本skb将会被分割成几个TSO段传输
tso_segs = tcp_init_tso_segs(sk, skb, mss_now);
BUG_ON(!tso_segs);
...
if (tso_segs == 1) {
//Nagle算法检测,如果已经有小数据段没有被确认,则本次发送尝试失败
if (unlikely(!tcp_nagle_test(tp, skb, mss_now,
(tcp_skb_is_last(sk, skb) ? nonagle : TCP_NAGLE_PUSH)))) {
break;
}
} else {
if (tcp_tso_should_defer(sk, skb))
break;
}
//limit是本次能够发送的字节数,如果skb的大小超过了limit,那么需要将其切割
limit = mss_now;
if (tso_segs > 1)
limit = tcp_mss_split_point(sk, skb, mss_now, cwnd_quota);
if (skb->len > limit && unlikely(tso_fragment(sk, skb, limit, mss_now)))
break;
...
}
...
}
4.2.1 tcp_init_tso_segs()
该函数设置skb中的GSO相关字段信息,并且返回
/* This must be invoked the first time we consider transmitting
* SKB onto the wire.
*/
static int tcp_init_tso_segs(struct sock *sk, struct sk_buff *skb, unsigned int mss_now)
{
int tso_segs = tcp_skb_pcount(skb);
//cond1: tso_segs为0表示该skb的GSO信息还没有被初始化过
//cond2: MSS发生了变化,需要重新计算GSO信息
if (!tso_segs || (tso_segs > 1 && tcp_skb_mss(skb) != mss_now)) {
tcp_set_skb_tso_segs(sk, skb, mss_now);
tso_segs = tcp_skb_pcount(skb);
}
//返回需要分割的段数
return tso_segs;
}
/* Due to TSO, an SKB can be composed of multiple actual
* packets. To keep these tracked properly, we use this.
*/
static inline int tcp_skb_pcount(const struct sk_buff *skb)
{
//gso_segs记录了网卡在传输当前skb时应该将其分割成多少个包进行
return skb_shinfo(skb)->gso_segs;
}
/* This is valid iff tcp_skb_pcount() > 1. */
static inline int tcp_skb_mss(const struct sk_buff *skb)
{
//gso_size记录了该skb应该按照多大的段被切割,即上次的MSS
return skb_shinfo(skb)->gso_size;
}
//设置skb中的GSO信息,所谓GSO信息,就是指skb_shared_info中的
//gso_segs、gso_size、gso_type三个字段
static void tcp_set_skb_tso_segs(struct sock *sk, struct sk_buff *skb, unsigned int mss_now)
{
//如果该skb数据量不足一个MSS,或者根本就不支持GSO,那么就是一个段
if (skb->len <= mss_now || !sk_can_gso(sk)) {
/* Avoid the costly divide in the normal non-TSO case.*/
//只需设置gso_segs为1,另外两个字段在这种情况下无意义
skb_shinfo(skb)->gso_segs = 1;
skb_shinfo(skb)->gso_size = 0;
skb_shinfo(skb)->gso_type = 0;
} else {
//计算要切割的段数,就是skb->len除以MSS,结果向上取整
skb_shinfo(skb)->gso_segs = DIV_ROUND_UP(skb->len, mss_now);
skb_shinfo(skb)->gso_size = mss_now;
//gso_type来自于TCB,该字段的初始化见上文
skb_shinfo(skb)->gso_type = sk->sk_gso_type;
}
}4.2.2 tso_fragment()
tso_fragment() 对数据包进行分段,见《linux内核协议栈 TCP层数据发送之发送新数》。

















 1603
1603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









