








 超级会员免费看
超级会员免费看

 GRO(Generic Receive Offload)是软件实现的LGO优化,减少CPU使用量。它合并类似网络包,形成大数据包传递给协议栈。在NAPI驱动中,通过napi_gro_receive等函数处理数据包,包括dev_gro_receive、inet_gro_receive和tcp4_gro_receive等步骤。GRO旨在提高接收数据包的性能,通过ethtool启用或禁用。
GRO(Generic Receive Offload)是软件实现的LGO优化,减少CPU使用量。它合并类似网络包,形成大数据包传递给协议栈。在NAPI驱动中,通过napi_gro_receive等函数处理数据包,包括dev_gro_receive、inet_gro_receive和tcp4_gro_receive等步骤。GRO旨在提高接收数据包的性能,通过ethtool启用或禁用。
目录
GRO(Generic Receive Offloading)是 LGO(Large Receive Offload,多数是在 NIC 上实现的一种硬件优化机制)的一种软件实现,从而能让所有 NIC 都支持这个功能。网络上大部分 MTU 都是 1500 字节,开启 Jumbo Frame 后能到 9000 字节,如果发送的数据超过 MTU 就需要切割成多个数据包。通过合并「足够类似」的包来减少传送给网络协议栈的包数,有助于减少 CPU 的使用量。GRO 使协议层只需处理一个 header,而将包含大量数据的整个大包送到用户程序。如果用 tcpdump 抓包看到机器收到了不现实的、非常大的包,这很可能是系统开启了 GRO。GRO 和「硬中断合并」的思想类似,不过阶段不同。「硬中断合并」是在中断发起之前,而 GRO 已经在软中断处理中了。
GRO(Generic Receive Offload)的主要功能将多个 TCP/UDP 数据聚合在一个skb结构,然后作为一个大数据包交付给上层的网络协议栈,以减少上层协议栈处理skb的开销,提高系统接收数据包的性能。合并了多个skb的超级 skb能够一次性通过网络协议栈,从而减轻CPU负载。
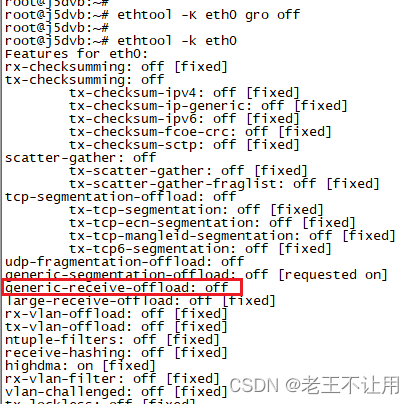
GRO是针对网络收包流程进行改进的,并且只有NAPI类型的驱动才支持此功能。因此如果要支持GRO,不仅要内核支持,驱动也必须调用相应的接口来开启此功能。用ethtool -K ethX gro on/off来开启/关闭 GRO,如果报错就说明网卡驱动本身就不支持GRO。
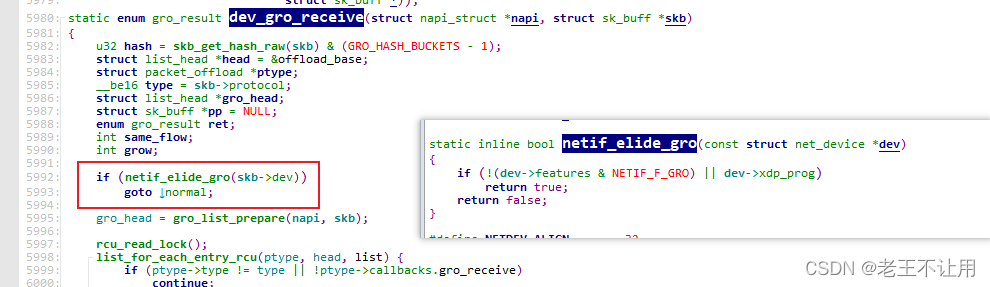
在调用 dev_gro_receive 函数收包时会判断是否支持GRO,逻辑如下:
GRO与TSO类似,但TSO只支持发送数据包。支持GRO的驱动会在NAPI的回调poll方法中读取数据包,然后调用GRO的接口napi_gro_receive或者napi_gro_frags来将数据包送进协议栈。
下面分析GRO处理数据包的流程(linux内核版本:5.10.59)。网卡驱动在收包时会调用napi_gro_receive函数接收数据:
1 napi_gro_receive
static inline void skb_gro_reset_offset(struct sk_buff *skb, u32 nhoff)
{
const struct skb_shared_info *pinfo = skb_shinfo(skb);
const skb_frag_t *frag0 = &pinfo->frags[0];
NAPI_GRO_CB(skb)->data_offset = 0;
NAPI_GRO_CB(skb)->frag0 = NULL;
NAPI_GRO_CB(skb)->frag0_len = 0;
//skb_headlen为0,则说明包头保存在skb_shinfo中
if (!skb_headlen(skb) && pinfo->nr_frags &&
!PageHighMem(skb_frag_page(frag0)) &&
(!NET_IP_ALIGN || !((skb_frag_off(frag0) + nhoff) & 3))) {
NAPI_GRO_CB(skb)->frag0 = skb_frag_address(frag0);
NAPI_GRO_CB(skb)->frag0_len = min_t(unsigned int,
skb_frag_size(frag0),
skb->end - skb->tail);
}
}
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
gro_result_t ret;
skb_mark_napi_id(skb, napi);
trace_napi_gro_receive_entry(skb);
skb_gro_reset_offset(skb, 0);
ret = napi_skb_finish(napi, skb, dev_gro_receive(napi, skb));
trace_napi_gro_receive_exit(ret);
return ret;
}
EXPORT_SYMBOL(napi_gro_receive);GRO将数据送进协议栈的点有两处:
一个是在napi_skb_finish里,它会通过判断dev_gro_receive的返回值,来决定是否需要将数据包送入进协议栈;
还有一个点是当napi的循环执行完毕执行 napi_complete 的时候。先来看 napi_skb_finish 函数:
2 napi_skb_finish
static gro_result_t napi_skb_finish(struct napi_struct *napi,
struct sk_buff *skb,
gro_result_t ret)
{
switch (ret) {
case GRO_NORMAL://将数据包送进协议栈
gro_normal_one(napi, skb, 1);
break;
case GRO_DROP:
kfree_skb(skb);
break;
case GRO_MERGED_FREE://表示skb可以被free,因为GRO已经将skb合并并保存起来
if (NAPI_GRO_CB(skb)->free == NAPI_GRO_FREE_STOLEN_HEAD)
napi_skb_free_stolen_head(skb);
else
__kfree_skb(skb);
break;
case GRO_HELD://这个表示当前数据已经被GRO保存起来,但是并没有进行合并,因此skb还需要保存。
case GRO_MERGED:
case GRO_CONSUMED:
break;
}
return ret;
}3 dev_gro_receive
dev_gro_receive函数用于合并skb,并决定是否将合并后的大skb送入网络协议栈:
INDIRECT_CALLABLE_DECLARE(struct sk_buff *inet_gro_receive(struct list_head *,
struct sk_buff *));
INDIRECT_CALLABLE_DECLARE(struct sk_buff *ipv6_gro_receive(struct list_head *,
struct sk_buff *));
static enum gro_result dev_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
u32 hash = skb_get_hash_raw(skb) & (GRO_HASH_BUCKETS - 1);
struct list_head *head = &offload_base;
struct packet_offload *ptype;
__be16 type = skb->protocol;
struct list_head *gro_head;
struct sk_buff *pp = NULL;
enum gro_result ret;
int same_flow;
int grow;
if (netif_elide_gro(skb->dev))//判断是否支持GRO
goto normal;
gro_head = gro_list_prepare(napi, skb);//比较GRO队列中的skb与当前skb在链路层是否属于同一个流
rcu_read_lock();
list_for_each_entry_rcu(ptype, head, list) {//遍历GRO处理函数注册队列
if (ptype->type != type || !ptype->callbacks.gro_receive)//查找网络层GRO处理函数
continue;
skb_set_network_header(skb, skb_gro_offset(skb));
skb_reset_mac_len(skb);
NAPI_GRO_CB(skb)->same_flow = 0;
//skb是GSO或skb有非线性空间的数据;这个skb已经是聚合状态了,不需要再次聚合
NAPI_GRO_CB(skb)->flush = skb_is_gso(skb) || skb_has_frag_list(skb);
NAPI_GRO_CB(skb)->free = 0;
NAPI_GRO_CB(skb)->encap_mark = 0;
NAPI_GRO_CB(skb)->recursion_counter = 0;
NAPI_GRO_CB(skb)->is_fou = 0;
NAPI_GRO_CB(skb)->is_atomic = 1;
NAPI_GRO_CB(skb)->gro_remcsum_start = 0;
/* Setup for GRO checksum validation */
switch (skb->ip_summed) {
case CHECKSUM_COMPLETE:
NAPI_GRO_CB(skb)->csum = skb->csum;
NAPI_GRO_CB(skb)->csum_valid = 1;
NAPI_GRO_CB(skb)->csum_cnt = 0;
break;
case CHECKSUM_UNNECESSARY:
NAPI_GRO_CB(skb)->csum_cnt = skb->csum_level + 1;
NAPI_GRO_CB(skb)->csum_valid = 0;
break;
default:
NAPI_GRO_CB(skb)->csum_cnt = 0;
NAPI_GRO_CB(skb)->csum_valid = 0;
}
pp = INDIRECT_CALL_INET(ptype->callbacks.gro_receive,
ipv6_gro_receive, inet_gro_receive,
gro_head, skb);//调用inet_gro_receive或ipv6_gro_receive合并skb
break;
}
rcu_read_unlock();
if (&ptype->list == head)
goto normal;
if (PTR_ERR(pp) == -EINPROGRESS) {
ret = GRO_CONSUMED;
goto ok;
}
same_flow = NAPI_GRO_CB(skb)->same_flow;
ret = NAPI_GRO_CB(skb)->free ? GRO_MERGED_FREE : GRO_MERGED;
if (pp) {
skb_list_del_init(pp);
napi_gro_complete(napi, pp);//更新聚合后的skb信息,将包送入协议栈
napi->gro_hash[hash].count--;
}
if (same_flow)//找到与当前skb属与同一个流的skb,此时当前skb已经聚合到所属的流中
goto ok;
if (NAPI_GRO_CB(skb)->flush)//skb不能聚合或GRO队列已满
goto normal;
if (unlikely(napi->gro_hash[hash].count >= MAX_GRO_SKBS)) {
gro_flush_oldest(napi, gro_head);
} else {
napi->gro_hash[hash].count++;
}
NAPI_GRO_CB(skb)->count = 1;
NAPI_GRO_CB(skb)->age = jiffies;
NAPI_GRO_CB(skb)->last = skb;
skb_shinfo(skb)->gso_size = skb_gro_len(skb);
list_add(&skb->list, gro_head);//将skb是一个新包,在gro_list中没有能与之合并的,需要加入到GRO队列中
ret = GRO_HELD;//存储当前包,不能释放
pull:
grow = skb_gro_offset(skb) - skb_headlen(skb);
if (grow > 0)//如果头不全部在线性区,则需要将其copy到线性区
gro_pull_from_frag0(skb, grow);
ok:
if (napi->gro_hash[hash].count) {
if (!test_bit(hash, &napi->gro_bitmask))
__set_bit(hash, &napi->gro_bitmask);
} else if (test_bit(hash, &napi->gro_bitmask)) {
__clear_bit(hash, &napi->gro_bitmask);
}
return ret;
normal:
ret = GRO_NORMAL;
goto pull;
}
static void gro_pull_from_frag0(struct sk_buff *skb, int grow)
{
struct skb_shared_info *pinfo = skb_shinfo(skb);
BUG_ON(skb->end - skb->tail < grow);
memcpy(skb_tail_pointer(skb), NAPI_GRO_CB(skb)->frag0, grow);//将第一个页的内容转移到线性空间
skb->data_len -= grow;
skb->tail += grow;
skb_frag_off_add(&pinfo->frags[0], grow);
skb_frag_size_sub(&pinfo->frags[0], grow);
if (unlikely(!skb_frag_size(&pinfo->frags[0]))) {//第一个页的内容已经全部转移到线性空间
skb_frag_unref(skb, 0);
memmove(pinfo->frags, pinfo->frags + 1,
--pinfo->nr_frags * sizeof(pinfo->frags[0]));//数组内容向前移动
}
}4 inet_gro_receive
inet_gro_receive 函数是网络层skb聚合处理函数:
struct sk_buff *inet_gro_receive(struct list_head *head, struct sk_buff *skb)
{
const struct net_offload *ops;
struct sk_buff *pp = NULL;
const struct iphdr *iph;
struct sk_buff *p;
unsigned int hlen;
unsigned int off;
unsigned int id;
int flush = 1;
int proto;
off = skb_gro_offset(skb);
hlen = off + sizeof(*iph);//MAC + IP头长度
iph = skb_gro_header_fast(skb, off);
if (skb_gro_header_hard(skb, hlen)) {
iph = skb_gro_header_slow(skb, hlen, off);
if (unlikely(!iph))
goto out;
}
proto = iph->protocol;
rcu_read_lock();
ops = rcu_dereference(inet_offloads[proto]);//找到传输层注册的处理函数
if (!ops || !ops->callbacks.gro_receive)
goto out_unlock;
if (*(u8 *)iph != 0x45)//不是IPv4且头长度不是20字节
goto out_unlock;
if (ip_is_fragment(iph))
goto out_unlock;
if (unlikely(ip_fast_csum((u8 *)iph, 5)))//检验和非法
goto out_unlock;
id = ntohl(*(__be32 *)&iph->id);
flush = (u16)((ntohl(*(__be32 *)iph) ^ skb_gro_len(skb)) | (id & ~IP_DF));
id >>= 16;
list_for_each_entry(p, head, list) {
struct iphdr *iph2;
u16 flush_id;
if (!NAPI_GRO_CB(p)->same_flow)//与当前包不是一个流
continue;
iph2 = (struct iphdr *)(p->data + off);
/* The above works because, with the exception of the top
* (inner most) layer, we only aggregate pkts with the same
* hdr length so all the hdrs we'll need to verify will start
* at the same offset.
*/
if ((iph->protocol ^ iph2->protocol) |
((__force u32)iph->saddr ^ (__force u32)iph2->saddr) |
((__force u32)iph->daddr ^ (__force u32)iph2->daddr)) {//三元组不匹配,与当前包不是一个流
NAPI_GRO_CB(p)->same_flow = 0;
continue;
}
/* All fields must match except length and checksum. */
NAPI_GRO_CB(p)->flush |=
(iph->ttl ^ iph2->ttl) |
(iph->tos ^ iph2->tos) |
((iph->frag_off ^ iph2->frag_off) & htons(IP_DF));//检查ttl、tos、id顺序,如果不符合则不是一个流
NAPI_GRO_CB(p)->flush |= flush;
/* We need to store of the IP ID check to be included later
* when we can verify that this packet does in fact belong
* to a given flow.
*/
flush_id = (u16)(id - ntohs(iph2->id));
/* This bit of code makes it much easier for us to identify
* the cases where we are doing atomic vs non-atomic IP ID
* checks. Specifically an atomic check can return IP ID
* values 0 - 0xFFFF, while a non-atomic check can only
* return 0 or 0xFFFF.
*/
if (!NAPI_GRO_CB(p)->is_atomic ||
!(iph->frag_off & htons(IP_DF))) {
flush_id ^= NAPI_GRO_CB(p)->count;
flush_id = flush_id ? 0xFFFF : 0;
}
/* If the previous IP ID value was based on an atomic
* datagram we can overwrite the value and ignore it.
*/
if (NAPI_GRO_CB(skb)->is_atomic)
NAPI_GRO_CB(p)->flush_id = flush_id;
else
NAPI_GRO_CB(p)->flush_id |= flush_id;
}
NAPI_GRO_CB(skb)->is_atomic = !!(iph->frag_off & htons(IP_DF));
NAPI_GRO_CB(skb)->flush |= flush;
skb_set_network_header(skb, off);
/* The above will be needed by the transport layer if there is one
* immediately following this IP hdr.
*/
/* Note : No need to call skb_gro_postpull_rcsum() here,
* as we already checked checksum over ipv4 header was 0
*/
skb_gro_pull(skb, sizeof(*iph));
skb_set_transport_header(skb, skb_gro_offset(skb));
pp = indirect_call_gro_receive(tcp4_gro_receive, udp4_gro_receive,
ops->callbacks.gro_receive, head, skb);//指向tcp4_gro_receive或tcp6_gro_receive
out_unlock:
rcu_read_unlock();
out:
skb_gro_flush_final(skb, pp, flush);
return pp;
}
EXPORT_SYMBOL(inet_gro_receive);5 tcp4_gro_receive
tcp4_gro_receive函数 是传输层skb聚合处理函数:
INDIRECT_CALLABLE_SCOPE
struct sk_buff *tcp4_gro_receive(struct list_head *head, struct sk_buff *skb)
{
/* Don't bother verifying checksum if we're going to flush anyway. */
if (!NAPI_GRO_CB(skb)->flush &&
skb_gro_checksum_validate(skb, IPPROTO_TCP,
inet_gro_compute_pseudo)) {
NAPI_GRO_CB(skb)->flush = 1;
return NULL;
}
return tcp_gro_receive(head, skb);
}
struct sk_buff *tcp_gro_receive(struct list_head *head, struct sk_buff *skb)
{
struct sk_buff *pp = NULL;
struct sk_buff *p;
struct tcphdr *th;
struct tcphdr *th2;
unsigned int len;
unsigned int thlen;
__be32 flags;
unsigned int mss = 1;
unsigned int hlen;
unsigned int off;
int flush = 1;
int i;
off = skb_gro_offset(skb);
hlen = off + sizeof(*th);
th = skb_gro_header_fast(skb, off);
if (skb_gro_header_hard(skb, hlen)) {
th = skb_gro_header_slow(skb, hlen, off);
if (unlikely(!th))
goto out;
}
thlen = th->doff * 4;
if (thlen < sizeof(*th))
goto out;
hlen = off + thlen;
if (skb_gro_header_hard(skb, hlen)) {
th = skb_gro_header_slow(skb, hlen, off);
if (unlikely(!th))
goto out;
}
skb_gro_pull(skb, thlen);
len = skb_gro_len(skb);
flags = tcp_flag_word(th);
list_for_each_entry(p, head, list) {
if (!NAPI_GRO_CB(p)->same_flow)//IP层与当前包不是一个流
continue;
th2 = tcp_hdr(p);
if (*(u32 *)&th->source ^ *(u32 *)&th2->source) {//源端口不匹配,与当前包不是一个流
NAPI_GRO_CB(p)->same_flow = 0;
continue;
}
goto found;
}
p = NULL;
goto out_check_final;
found:
/* Include the IP ID check below from the inner most IP hdr */
flush = NAPI_GRO_CB(p)->flush;
flush |= (__force int)(flags & TCP_FLAG_CWR);//发生了拥塞,那么前面被缓存的数据包需要马上被送入协议栈,以便进行TCP的拥塞控制
flush |= (__force int)((flags ^ tcp_flag_word(th2)) &
~(TCP_FLAG_CWR | TCP_FLAG_FIN | TCP_FLAG_PSH));//如果控制标志位除了CWR、FIN、PSH外有不相同的则需要马上被送入协议栈
flush |= (__force int)(th->ack_seq ^ th2->ack_seq);//确认号不相同则需要马上被送入协议栈,以便尽快释放TCP发送缓存中的空间
for (i = sizeof(*th); i < thlen; i += 4)
flush |= *(u32 *)((u8 *)th + i) ^
*(u32 *)((u8 *)th2 + i);
/* When we receive our second frame we can made a decision on if we
* continue this flow as an atomic flow with a fixed ID or if we use
* an incrementing ID.
*/
if (NAPI_GRO_CB(p)->flush_id != 1 ||
NAPI_GRO_CB(p)->count != 1 ||
!NAPI_GRO_CB(p)->is_atomic)
flush |= NAPI_GRO_CB(p)->flush_id;
else
NAPI_GRO_CB(p)->is_atomic = false;
mss = skb_shinfo(p)->gso_size;
flush |= (len - 1) >= mss;
flush |= (ntohl(th2->seq) + skb_gro_len(p)) ^ ntohl(th->seq);
#ifdef CONFIG_TLS_DEVICE
flush |= p->decrypted ^ skb->decrypted;
#endif
if (flush || skb_gro_receive(p, skb)) {//flush非0意味着需要将skb立即送入协议栈;这样的包不能调用skb_gro_receive进行合并
mss = 1;
goto out_check_final;
}
tcp_flag_word(th2) |= flags & (TCP_FLAG_FIN | TCP_FLAG_PSH);
out_check_final:
flush = len < mss;
flush |= (__force int)(flags & (TCP_FLAG_URG | TCP_FLAG_PSH |
TCP_FLAG_RST | TCP_FLAG_SYN |
TCP_FLAG_FIN));//如果包中有URG、PSH、RST、SYN、FIN标记中的任意一个,则将合并后的包立即交付协议栈
if (p && (!NAPI_GRO_CB(skb)->same_flow || flush))
pp = p;
out:
NAPI_GRO_CB(skb)->flush |= (flush != 0);
return pp;
}这里有一个疑问:为什么匹配TCP流时只检查源端口而不检查目的端口?猜测:因为检查了seq和ack_seq。源IP和源端口相同意味着包来自与同一台主机,这种情况下seq和ack_seq都匹配且目的端口不同的概率极低,所以不用检查目的端口。
6 skb_gro_receive
skb_gro_receive函数用于合并同流的skb:
int skb_gro_receive(struct sk_buff *p, struct sk_buff *skb)
{
struct skb_shared_info *pinfo, *skbinfo = skb_shinfo(skb);
unsigned int offset = skb_gro_offset(skb);
unsigned int headlen = skb_headlen(skb);
unsigned int len = skb_gro_len(skb);
unsigned int delta_truesize;
struct sk_buff *lp;
if (unlikely(p->len + len >= 65536 || NAPI_GRO_CB(skb)->flush))
return -E2BIG;
lp = NAPI_GRO_CB(p)->last;
pinfo = skb_shinfo(lp);
if (headlen <= offset) {//有一部分头在page中
skb_frag_t *frag;
skb_frag_t *frag2;
int i = skbinfo->nr_frags;
int nr_frags = pinfo->nr_frags + i;
if (nr_frags > MAX_SKB_FRAGS)
goto merge;
offset -= headlen;
pinfo->nr_frags = nr_frags;
skbinfo->nr_frags = 0;
frag = pinfo->frags + nr_frags;
frag2 = skbinfo->frags + i;
do {//遍历赋值,将skb的frag加到pinfo的frgas后面
*--frag = *--frag2;
} while (--i);
skb_frag_off_add(frag, offset);//去除剩余的头,只保留数据部分
skb_frag_size_sub(frag, offset);
/* all fragments truesize : remove (head size + sk_buff) */
delta_truesize = skb->truesize -
SKB_TRUESIZE(skb_end_offset(skb));
skb->truesize -= skb->data_len;
skb->len -= skb->data_len;
skb->data_len = 0;
NAPI_GRO_CB(skb)->free = NAPI_GRO_FREE;
goto done;
} else if (skb->head_frag) {//支持分散-聚集IO
int nr_frags = pinfo->nr_frags;
skb_frag_t *frag = pinfo->frags + nr_frags;
struct page *page = virt_to_head_page(skb->head);
unsigned int first_size = headlen - offset;
unsigned int first_offset;
if (nr_frags + 1 + skbinfo->nr_frags > MAX_SKB_FRAGS)
goto merge;
first_offset = skb->data -
(unsigned char *)page_address(page) +
offset;
pinfo->nr_frags = nr_frags + 1 + skbinfo->nr_frags;
__skb_frag_set_page(frag, page);
skb_frag_off_set(frag, first_offset);
skb_frag_size_set(frag, first_size);
memcpy(frag + 1, skbinfo->frags, sizeof(*frag) * skbinfo->nr_frags);
/* We dont need to clear skbinfo->nr_frags here */
delta_truesize = skb->truesize - SKB_DATA_ALIGN(sizeof(struct sk_buff));
NAPI_GRO_CB(skb)->free = NAPI_GRO_FREE_STOLEN_HEAD;
goto done;
}
merge:
delta_truesize = skb->truesize;
if (offset > headlen) {
unsigned int eat = offset - headlen;
skb_frag_off_add(&skbinfo->frags[0], eat);
skb_frag_size_sub(&skbinfo->frags[0], eat);
skb->data_len -= eat;
skb->len -= eat;
offset = headlen;
}
__skb_pull(skb, offset);
if (NAPI_GRO_CB(p)->last == p)
skb_shinfo(p)->frag_list = skb;//将旧GRO队列头放入frag_list队列中
else
NAPI_GRO_CB(p)->last->next = skb;//将包放入GRO队列中
NAPI_GRO_CB(p)->last = skb;
__skb_header_release(skb);
lp = p;
done:
NAPI_GRO_CB(p)->count++;
p->data_len += len;
p->truesize += delta_truesize;
p->len += len;
if (lp != p) {
lp->data_len += len;
lp->truesize += delta_truesize;
lp->len += len;
}
NAPI_GRO_CB(skb)->same_flow = 1;//标识当前skb已经找到同流的skb并进行了合并
return 0;
}可见当网卡支持分散-聚集IO时,GRO会将多个skb合并到一个skb的frag page数组中,否则会合并到skb的的frag_list中。
即使在上述流程中skb被放入GRO队列中保存而没有被立即送入协议栈,它们也不会在队列中滞留太长时间,因为在收包软中断中会调用napi_gro_flush函数将GRO队列中的包送入协议栈:
7 napi_gro_flush
static void __napi_gro_flush_chain(struct napi_struct *napi, u32 index,
bool flush_old)
{
struct list_head *head = &napi->gro_hash[index].list;
struct sk_buff *skb, *p;
list_for_each_entry_safe_reverse(skb, p, head, list) {
if (flush_old && NAPI_GRO_CB(skb)->age == jiffies)
return;
skb_list_del_init(skb);
napi_gro_complete(napi, skb);//将包送入协议栈
napi->gro_hash[index].count--;
}
if (!napi->gro_hash[index].count)
__clear_bit(index, &napi->gro_bitmask);
}
/* napi->gro_hash[].list contains packets ordered by age.
* youngest packets at the head of it.
* Complete skbs in reverse order to reduce latencies.
*/
void napi_gro_flush(struct napi_struct *napi, bool flush_old)
{
unsigned long bitmask = napi->gro_bitmask;
unsigned int i, base = ~0U;
while ((i = ffs(bitmask)) != 0) {
bitmask >>= i;
base += i;
__napi_gro_flush_chain(napi, base, flush_old);
}
}
EXPORT_SYMBOL(napi_gro_flush);包加入GRO队列的时间比当前仅晚1个jiffies也会被视作旧包并交付协议栈处理,可见如果软中断每个jiffies都调用一次napi_gro_flush函数的话,开启GRO功能最多增加1个jiffies(1ms或10ms)的延迟 .
8 napi_gro_complete
napi_gro_complete 函数会先处理一下聚合包各层协议的首部信息,再将包交付网络协议栈:
INDIRECT_CALLABLE_DECLARE(int inet_gro_complete(struct sk_buff *, int));
INDIRECT_CALLABLE_DECLARE(int ipv6_gro_complete(struct sk_buff *, int));
static int napi_gro_complete(struct napi_struct *napi, struct sk_buff *skb)
{
struct packet_offload *ptype;
__be16 type = skb->protocol;
struct list_head *head = &offload_base;
int err = -ENOENT;
BUILD_BUG_ON(sizeof(struct napi_gro_cb) > sizeof(skb->cb));
if (NAPI_GRO_CB(skb)->count == 1) {
skb_shinfo(skb)->gso_size = 0;
goto out;
}
rcu_read_lock();
list_for_each_entry_rcu(ptype, head, list) {
if (ptype->type != type || !ptype->callbacks.gro_complete)
continue;
err = INDIRECT_CALL_INET(ptype->callbacks.gro_complete,
ipv6_gro_complete, inet_gro_complete,//指向inet_gro_complete或ipv6_gro_complete
skb, 0);
break;
}
rcu_read_unlock();
if (err) {
WARN_ON(&ptype->list == head);
kfree_skb(skb);
return NET_RX_SUCCESS;
}
out:
gro_normal_one(napi, skb, NAPI_GRO_CB(skb)->count);
return NET_RX_SUCCESS;
}
/* Queue one GRO_NORMAL SKB up for list processing. If batch size exceeded,
* pass the whole batch up to the stack.
*/
更新当前 napi->rx_count 计数, 当数量达到gro_normal_batch时,将调用 gro_normal_list 函数,将多个包一次性送到协议栈。
static void gro_normal_one(struct napi_struct *napi, struct sk_buff *skb, int segs)
{
list_add_tail(&skb->list, &napi->rx_list);
napi->rx_count += segs;
if (napi->rx_count >= gro_normal_batch)
gro_normal_list(napi);
}
9 inet_gro_complete
inet_gro_complete函数处理网络层首部信息:
int inet_gro_complete(struct sk_buff *skb, int nhoff)
{
__be16 newlen = htons(skb->len - nhoff);
struct iphdr *iph = (struct iphdr *)(skb->data + nhoff);
const struct net_offload *ops;
int proto = iph->protocol;
int err = -ENOSYS;
if (skb->encapsulation) {
skb_set_inner_protocol(skb, cpu_to_be16(ETH_P_IP));
skb_set_inner_network_header(skb, nhoff);
}
csum_replace2(&iph->check, iph->tot_len, newlen);//重新计算IP检验和,因为聚合在一起的包共用一个IP头
iph->tot_len = newlen;//重新计算包长
rcu_read_lock();
ops = rcu_dereference(inet_offloads[proto]);
if (WARN_ON(!ops || !ops->callbacks.gro_complete))
goto out_unlock;
/* Only need to add sizeof(*iph) to get to the next hdr below
* because any hdr with option will have been flushed in
* inet_gro_receive().
*/
err = INDIRECT_CALL_2(ops->callbacks.gro_complete,
tcp4_gro_complete, udp4_gro_complete,//指向tcp4_gro_complete或tcp6_gro_complete
skb, nhoff + sizeof(*iph));
out_unlock:
rcu_read_unlock();
return err;
}
EXPORT_SYMBOL(inet_gro_complete);10 tcp4_gro_complete
tcp4_gro_complete 函数处理TCP首部信息:
INDIRECT_CALLABLE_SCOPE int tcp4_gro_complete(struct sk_buff *skb, int thoff)
{
const struct iphdr *iph = ip_hdr(skb);
struct tcphdr *th = tcp_hdr(skb);
th->check = ~tcp_v4_check(skb->len - thoff, iph->saddr,
iph->daddr, 0);//重算聚合后的包的TCP检验和
skb_shinfo(skb)->gso_type |= SKB_GSO_TCPV4;
if (NAPI_GRO_CB(skb)->is_atomic)
skb_shinfo(skb)->gso_type |= SKB_GSO_TCP_FIXEDID;
return tcp_gro_complete(skb);
}
int tcp_gro_complete(struct sk_buff *skb)
{
struct tcphdr *th = tcp_hdr(skb);
skb->csum_start = (unsigned char *)th - skb->head;
skb->csum_offset = offsetof(struct tcphdr, check);
skb->ip_summed = CHECKSUM_PARTIAL;
skb_shinfo(skb)->gso_segs = NAPI_GRO_CB(skb)->count;
if (th->cwr)
skb_shinfo(skb)->gso_type |= SKB_GSO_TCP_ECN;
if (skb->encapsulation)
skb->inner_transport_header = skb->transport_header;
return 0;
}
EXPORT_SYMBOL(tcp_gro_complete);可见,GRO的基本原理是将MAC层、IP层和TCP层都能合并的包的头只留一个,数据部分在frag数组或frag_list中存储,这样大大提高了包携带数据的效率。
在完成GRO处理后,skb会被交付到Linux网络协议栈入口进行协议处理。聚合后的skb在被送入到网络协议栈后,在网络层协议、TCP协议处理函数中会调用pskb_may_pull函数将GRO skb的数据整合到线性空间:
11 tcp_v4_rcv
int tcp_v4_rcv(struct sk_buff *skb)
{
struct net *net = dev_net(skb->dev);
struct sk_buff *skb_to_free;
int sdif = inet_sdif(skb);
int dif = inet_iif(skb);
const struct iphdr *iph;
const struct tcphdr *th;
bool refcounted;
struct sock *sk;
int ret;
if (skb->pkt_type != PACKET_HOST)
goto discard_it;
/* Count it even if it's bad */
__TCP_INC_STATS(net, TCP_MIB_INSEGS);
if (!pskb_may_pull(skb, sizeof(struct tcphdr)))//将TCP基本首部整合到线性空间
goto discard_it;
th = (const struct tcphdr *)skb->data;
if (unlikely(th->doff < sizeof(struct tcphdr) / 4))
goto bad_packet;
if (!pskb_may_pull(skb, th->doff * 4))//将TCP全部首部数据整合到线性空间
goto discard_it;12 pskb_may_pull
static inline bool pskb_may_pull(struct sk_buff *skb, unsigned int len)
{
if (likely(len <= skb_headlen(skb)))//线性区中的数据长度够pull len个字节
return true;
if (unlikely(len > skb->len))//skb中数据总长度小于len,包异常
return false;
return __pskb_pull_tail(skb, len - skb_headlen(skb)) != NULL;//需要增加线性区中的数据
}
/* Moves tail of skb head forward, copying data from fragmented part,
* when it is necessary.
* 1. It may fail due to malloc failure.
* 2. It may change skb pointers.
*
* It is pretty complicated. Luckily, it is called only in exceptional cases.
*/
void *__pskb_pull_tail(struct sk_buff *skb, int delta)
{
/* If skb has not enough free space at tail, get new one
* plus 128 bytes for future expansions. If we have enough
* room at tail, reallocate without expansion only if skb is cloned.
*/
int i, k, eat = (skb->tail + delta) - skb->end;
if (eat > 0 || skb_cloned(skb)) {//如果空间不足或是有共享空间
if (pskb_expand_head(skb, 0, eat > 0 ? eat + 128 : 0,
GFP_ATOMIC))
return NULL;
}
BUG_ON(skb_copy_bits(skb, skb_headlen(skb),//将非线性空间中的数据填充到线性空间
skb_tail_pointer(skb), delta));
/* Optimization: no fragments, no reasons to preestimate
* size of pulled pages. Superb.
*/
if (!skb_has_frag_list(skb))//frag_list中没有skb
goto pull_pages;
/* Estimate size of pulled pages. */
eat = delta;
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {
int size = skb_frag_size(&skb_shinfo(skb)->frags[i]);
if (size >= eat)//仅使用frags中的数据就填满了pull的长度
goto pull_pages;
eat -= size;
}
/* If we need update frag list, we are in troubles.
* Certainly, it is possible to add an offset to skb data,
* but taking into account that pulling is expected to
* be very rare operation, it is worth to fight against
* further bloating skb head and crucify ourselves here instead.
* Pure masohism, indeed. 8)8)
*/
if (eat) {//整理frag_list队列
struct sk_buff *list = skb_shinfo(skb)->frag_list;
struct sk_buff *clone = NULL;
struct sk_buff *insp = NULL;
do {
if (list->len <= eat) {
/* Eaten as whole. */
eat -= list->len;
list = list->next;
insp = list;
} else {
/* Eaten partially. */
if (skb_shared(list)) {
/* Sucks! We need to fork list. :-( */
clone = skb_clone(list, GFP_ATOMIC);
if (!clone)
return NULL;
insp = list->next;
list = clone;
} else {
/* This may be pulled without
* problems. */
insp = list;
}
if (!pskb_pull(list, eat)) {
kfree_skb(clone);
return NULL;
}
break;
}
} while (eat);
/* Free pulled out fragments. */
while ((list = skb_shinfo(skb)->frag_list) != insp) {//释放已经合并的skb
skb_shinfo(skb)->frag_list = list->next;
kfree_skb(list);
}
/* And insert new clone at head. */
if (clone) {
clone->next = list;
skb_shinfo(skb)->frag_list = clone;
}
}
/* Success! Now we may commit changes to skb data. */
pull_pages:
eat = delta;
k = 0;
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {
int size = skb_frag_size(&skb_shinfo(skb)->frags[i]);
if (size <= eat) {//释放已经合并的page
skb_frag_unref(skb, i);
eat -= size;
} else {
skb_frag_t *frag = &skb_shinfo(skb)->frags[k];
*frag = skb_shinfo(skb)->frags[i];
if (eat) {
skb_frag_off_add(frag, eat);
skb_frag_size_sub(frag, eat);
if (!i)
goto end;
eat = 0;
}
k++;
}
}
skb_shinfo(skb)->nr_frags = k;
end:
skb->tail += delta;
skb->data_len -= delta;
if (!skb->data_len)
skb_zcopy_clear(skb, false);
return skb_tail_pointer(skb);
}
EXPORT_SYMBOL(__pskb_pull_tail);
/**
* skb_copy_bits - copy bits from skb to kernel buffer
* @skb: source skb
* @offset: offset in source
* @to: destination buffer
* @len: number of bytes to copy
*
* Copy the specified number of bytes from the source skb to the
* destination buffer.
*
* CAUTION ! :
* If its prototype is ever changed,
* check arch/{*}/net/{*}.S files,
* since it is called from BPF assembly code.
*/
int skb_copy_bits(const struct sk_buff *skb, int offset, void *to, int len)
{
int start = skb_headlen(skb);
struct sk_buff *frag_iter;
int i, copy;
if (offset > (int)skb->len - len)
goto fault;
/* Copy header. */
if ((copy = start - offset) > 0) {
if (copy > len)
copy = len;
skb_copy_from_linear_data_offset(skb, offset, to, copy);
if ((len -= copy) == 0)
return 0;
offset += copy;
to += copy;
}
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {//将frags数组中数据整理到线性区
int end;
skb_frag_t *f = &skb_shinfo(skb)->frags[i];
WARN_ON(start > offset + len);
end = start + skb_frag_size(f);
if ((copy = end - offset) > 0) {
u32 p_off, p_len, copied;
struct page *p;
u8 *vaddr;
if (copy > len)
copy = len;
skb_frag_foreach_page(f,
skb_frag_off(f) + offset - start,
copy, p, p_off, p_len, copied) {
vaddr = kmap_atomic(p);
memcpy(to + copied, vaddr + p_off, p_len);//复制页中数据到线性区
kunmap_atomic(vaddr);
}
if ((len -= copy) == 0)//copy的长度如果达到了要pull的长度,则可以结束了
return 0;
offset += copy;
to += copy;
}
start = end;
}
skb_walk_frags(skb, frag_iter) {//frags队列中的page都已经合入线性区,但还是没有凑够要pull的长度,需要整理frag_list队列
int end;
WARN_ON(start > offset + len);
end = start + frag_iter->len;
if ((copy = end - offset) > 0) {
if (copy > len)
copy = len;
if (skb_copy_bits(frag_iter, offset - start, to, copy))
goto fault;
if ((len -= copy) == 0)//copy的长度如果达到了要pull的长度,则可以结束了
return 0;
offset += copy;
to += copy;
}
start = end;
}
if (!len)
return 0;
fault:
return -EFAULT;
}
EXPORT_SYMBOL(skb_copy_bits);pskb_may_pull的整合保证了TCP首部数据全部被放入线性空间,从而使GRO不影响TCP协议的处理。在应用进程使用系统调用收数据时,会将仍然分散在不连续空间中的数据copy到应用进程的缓存空间中。应用进程会使用tcp_recvmsg函数收取数据:
13 tcp_recvmsg
int tcp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
size_t len, int nonblock, int flags, int *addr_len)
{
...
if (!(flags & MSG_TRUNC)) {
err = skb_copy_datagram_msg(skb, offset, msg, used);//copy数据到用户缓存
if (err) {
/* Exception. Bailout! */
if (!copied)
copied = -EFAULT;
break;
}
}
...skb_copy_datagram_msg函数可以将skb的线性区和非线性区中的数据全部copy进用户缓存,Linux以GRO方式接收的数据会在这个函数中全部交付应用进程。

















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









