







Redis是单线程,Redis是很快的,是基于内存操作,CPU不是redis的瓶颈。Redis的瓶颈是根据机器的内存和网络的带宽。
Redis单线程为什么还那么快?
我们经常的误区:
1.高性能分服务器一定是多线程的。(这个是不一定的)
2.多线程一定比单线程效率高(错误的) 当一个cpu时候多线程cup上下会切换,单线程效率会更高。
Redis是将所有的数据放在了内存中,所以说使用单线程操作效率是最高的,多线程(cup会上下切换:这是一个耗时的操作!!)对于内存没有上下文切换效率是最高的,多次读写都是在一个cpu上的。
1.Redis简单实用(Linux)
Redis的基础命令
-
redis-cli -p 6379
#使用redis客户端进行连接
-
-
ping
#测试连接
-
-
set
name kuangshen
-
-
get
name
-
-
#获取所有的key
-
get *
-
-
#关闭redis服务
-
shutdowm
查看所有的服务命令: ps -ef|gerp redis
2.Redis基础操作
Redis,默认有16个数据库,默认使用的是第0个数据库
-
#选择第三个数据库
-
SELECT
3
-
-
#获取数据库中所有key
-
Keys *
-
-
#清除库中所有的值
-
flushdb
-
-
#清楚全部数据库数据
-
flusAll
3.Redis基本的数据类型
-
#判断当前key是否存在
-
exists
name
-
#移除当前key
-
move
name
-
#设置当前key 过期
-
expier
name 10
-
#查看当前key的剩余时间
-
ttl
name
-
#查看当前key是什么类型
-
type
name
1.String(字符串类型)
APPEND KEY "str" 在当前key后面追加字符串。 STRLEN KEY 查看当前key所对应value的长度。
incr KEY 计数器+1 decr KEY 计数器-1
INCRBY KEY 10 计数器 +10 DECRBY KEY 10 计数器-10
GETRANGE KEY 0 3 截取key字符串[0,3]之间类似java 截取字符串。
SETRANGE KEY a b 把key中的a替换为b
setex key 30 "value" 设置过期时间30s自动删除 setnx key 30 "value" 设置过期时间如果这个key不存在才能设置,key值存在无法设置(分布式锁中常用)
mset k1 v1 k2 v2 k3 v3 批量设值 mget k1 k2 k3 批量获取值 msetnx k1 v1 k4 v4 设置值如果存在将无法设置。msetnx是一个原子性操作,要么成功要么失败
mset user:1:name zhangsan user1:age 18 这里的key是一个巧妙的设计: user{id}:{filed}
getset key value 先get在set 如果get时值为null则不进行set,如果get是有值则进行set操作。
2.List基本数据类型列表。数据值可以重复存在的
在redis里面我们可以把list玩成 栈 队列 阻塞队列!所有的list命令都是用 l(L) 开头的
lpush list one 将一个值或多个值插入列表的头部(左)下标0 rpush list one 将一个值或多个值插入列表的尾部(右)下标最后一个
lrange list 0 3 获取list中下标[0,3]之间的值 Llen list 获取list的长度 lindex list 3 获取下标为3的一个值(通过下标获取值)
LPOP list 移除最左边的某一个值 RPOP list 移除最右边(最后面)的一个值 Lrem list 1 one 删除list中1个one值(可以移除多个)
Ltrim list 0 3 截取list中下标[0,3]中的值[0,3]以外的全部删除
reoplpush list1 list2 移除列表最后一个元素移动到新的list列表中:案例 list1中最后一个元素移动到了list2中
lest list 0 item 将列表中指定下标的值替换为另外一个值(类似于更新操作),如果不存在这个下标值更新会报错,如果存在就更新当前下标值
linsert list before "hello" (linsert list after "hello") 将某个具体值插入到某个元素的前面或者后面
小结:
实际是个链表 前后都能插入,
如果key不存在,创建新的链表, 如果key存在则新增内容
如果移除所有的值,空链表,也代表不存在
在两边插入或改动,效率最高。中间元素操作效率会低一点。
消息队列(Lpush Rpop)栈(Lpush Lpop)
3.SET集合(值不能重复,无序)
sadd list "hello" set集合中添加一个元素 smembers list 查看指定set的所有值 sismember list hello 判断某一个值是否在set集合中!
scard list 获取set集合中元素个数
srem list hello 移除set集合中指定的元素
srandmember list 随机抽选出1个元素 srandmember list 3 随机抽选出3个元素(可以指定个数)
spop list 随机删除一些set集合中的元素
sadd list "hello" 将一个指定的值移动到set集合 smove list1 list2 "hello yidong" 将一个指定的值移动到另一个set集合 set集合1(list1) 移动到set集合2(list2)中
sdiff list1 list2 差集(list1中存在的而list2中不存在的) sinter list1 list2 交集(共同好友)list1和list2共同存在的 sunion list1 list2 并集list1和list2加一起的值
4.Hash哈希 Map key-map !
hset myhash key1 value1 key2 value2 set多个key-value hget myhash key1 key2 获取多个字段值 hgetall myhash 获取全部键值
hdel myhash key1 删除myhash中指定的key字段,对应的value值也就消失了! hlen myhash 获取表字段的数量
hexists myhash key 判断hash中指定的值是否存在 hkeys myhash 获取所有的key值 hvals 获取所有的values 值
hincr myhash key 1(-1) 只定key自增 1 (减1) hsetnx myhash key hello 如果不存在则可以设置,如果存在则不可以设置
hash变更数据user name age 尤其是用户信息之类的,经常变动的信息!hash更适合于对象存储,String更适合于字符串存储。
5.Zset(有序集合)
在set基础上增加了一个值set k1 v1 zset k1 score v1
zadd myset 2 two 3 three 添加多个值two添加到第2个位置 three添加到第3个位置
ZRANGEBYSCORE myset -inf +inf 显示全部的数据从小到大根据score排序 ZREVRANGE myset 0 -1 显示全部的数据从大到小根据score排序
ZRANGEBYSCORE myset -inf +inf withsorces 显示全部的数据从大到小根据score排序,并显示sorce值
ZRANGEBYSCORE myset -inf 2500 withsorces 显示score小于2500一下的值和score值
zrem myset xiaohong 移除有序集合中指定的一个元素 zcard myset 获取集合中的个数
zcount myset 1 3 获取指定区间中的值数量个数
以上也可以参考官方文档http://www.redis.cn/commands.html
4.三种特殊的数据类型
1.geospatial 地理位置(常用来做 :朋友定位,附近人,求两位置之间之间距离)3.2版本推出
只有6个命令

详细学习介绍http://redisdoc.com/geo/index.html
2.HyperLogLog基数统计的算法(常用来做 :统计UV独立访客)
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
详细介绍https://www.runoob.com/redis/redis-hyperloglog.html
3.bitmap通过最小的单位bit来进行0或者1的设置,表示某个元素对应的值或者状态。(常用来做 :用户在线状态,统计活跃用户,用户签到)
用法:setBit getBit bitCount bitOp
详细介绍https://blog.csdn.net/u011957758/article/details/74783347
5.Redis.config配置文件解读(不区分大小写)
1.INCLUDES(导入)
2.NETWORK网络
-
bind
127.0
.0
.1
#绑定的ip
-
protected-mode
yes
#保护模式
-
port
6379
#端口设置
3.GENERAL(通用)
-
daemonize
yes
#以守护进程方式运行,默认是no,我们需要自己开启为yes
-
pidfile /var/ryb/redis_6379.pid
#如果以后台的方式运行,我们需要指定一个pid文件!

4.snapshotting(快照-持久化用到)rdb aof
持久化,在规定的时间内.执行了多少次操作,则会持久化到文件rdb. aof
redis是内存数据库,如果没有持久化,那么数据断电及失

5.REPLCATION复制,主从复制
6.SECURITY安全(可以设置密码,默认没有)
-
redis命令设置
-
-
config
get requirepass
#获取redis密码
-
-
config
set requirepass
"123456"
#设置redis密码
-
7.CLIENTS限制
maxckient 10000 #设置能连接redis的最大客户端数量
maxmemort <bates> #redis配置最大额内存容量

8.APPEND ONLY 模式 aof配置
-
appendonly
no
#默认不开启aof模式,默认使用rdb方式持久化的,在大部分情况下rdb够用.
-
appendfilename
"appendonly.aof"
#持久化文件名字

5.缓存穿透,击穿,雪崩
1.穿透(查不到导致)
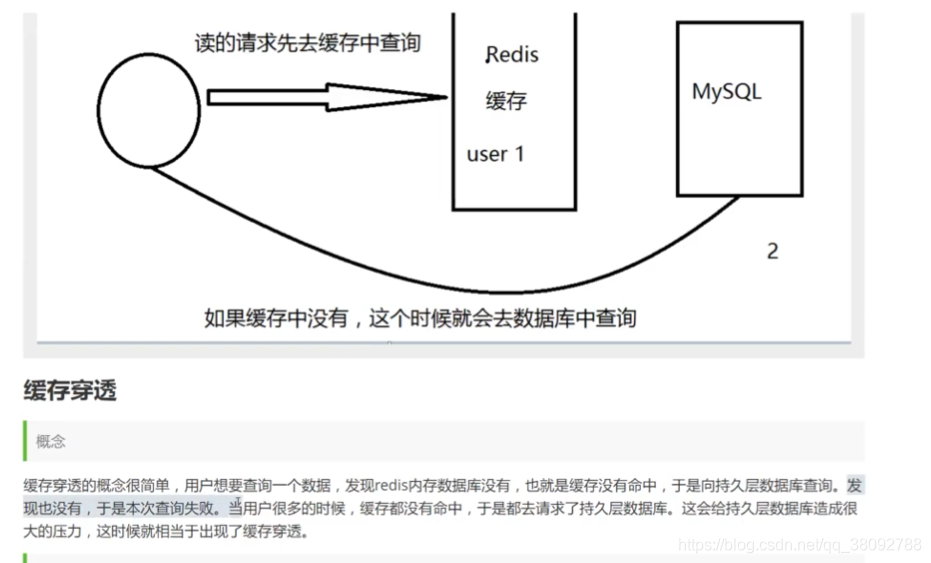
解决方案:
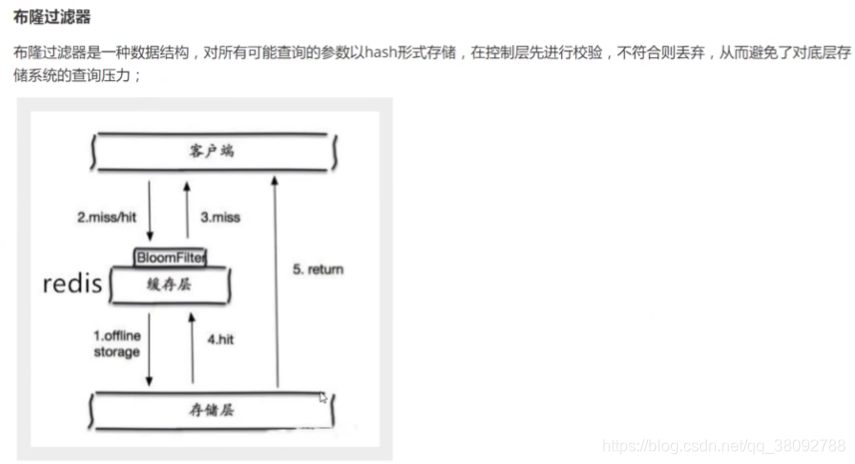
1.布隆过滤器
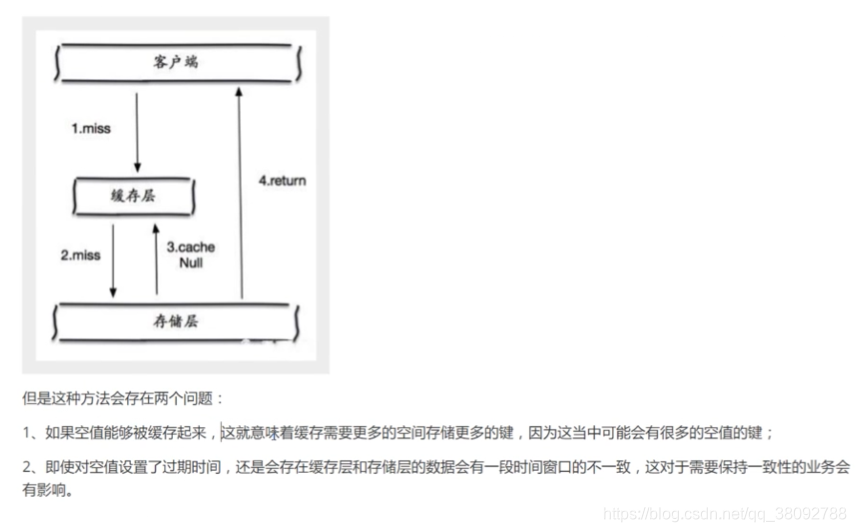
2.缓存空对象

2.击穿 量太大造成(都去请求一个位置,例子:某某明星出轨然后)
解决方案:
1.设置热点数据永不过期
![]()
2.加互斥锁(在缓存后面加锁,只保证一个线程进去)

3.雪崩
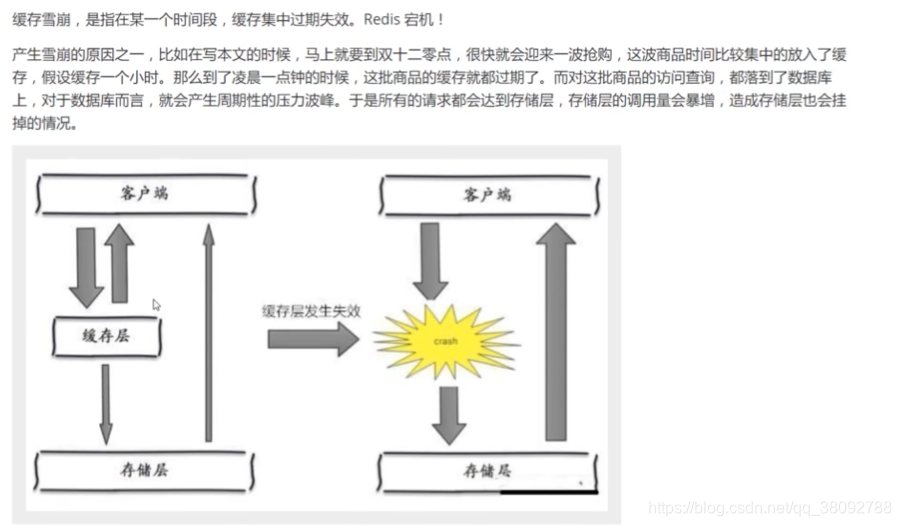















 651
651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









