








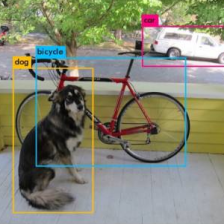
训练的结尾部分
还有最后一些损失信息的统计什么的,就在train_frcnn.py中:
# rpn_loss_cls rpn_loss_regr
losses[iter_num, 0] = loss_rpn[1]
losses[iter_num, 1] = loss_rpn[2]
# dense_class_4_loss dense_regress_4_loss dense_class_4_acc
losses[iter_num, 2] = loss_class[1]
losses[iter_num, 3] = loss_class[2]
losses[iter_num, 4] = loss_class[3]
iter_num += 1
# 输出各个指标累计loss的平均
progbar.update(iter_num,
[('rpn_cls', np.mean(losses[:iter_num, 0])), ('rpn_regr', np.mean(losses[:iter_num, 1])),
('detector_cls', np.mean(losses[:iter_num, 2])),
('detector_regr', np.mean(losses[:iter_num, 3]))])
if iter_num == epoch_length:
loss_rpn_cls = np.mean(losses[:, 0])
loss_rpn_regr = np.mean(losses[:, 1])
loss_class_cls = np.mean(losses[:, 2])
loss_class_regr = np.mean(losses[:, 3])
class_acc = np.mean(losses[:, 4])
# 计算正样本的比例
mean_overlapping_bboxes = float(sum(rpn_accuracy_for_epoch)) / len(rpn_accuracy_for_epoch)
rpn_accuracy_for_epoch = []
if C.verbose:
print('Mean number of bounding boxes from RPN overlapping ground truth boxes: {}'.format(
mean_overlapping_bboxes))
print('Classifier accuracy for bounding boxes from RPN: {}'.format(class_acc))
print('Loss RPN classifier: {}'.format(loss_rpn_cls))
print('Loss RPN regression: {}'.format(loss_rpn_regr))
print('Loss Detector classifier: {}'.format(loss_class_cls))
print('Loss Detector regression: {}'.format(loss_class_regr))
print('Elapsed time: {}'.format(time.time() - start_time))
# 当前总损失
curr_loss = loss_rpn_cls + loss_rpn_regr + loss_class_cls + loss_class_regr
iter_num = 0
start_time = time.time()
# 损失变小了就保存参数
if curr_loss < best_loss:
if C.verbose:
print('Total loss decreased from {} to {}, saving weights'.format(best_loss, curr_loss))
best_loss = curr_loss
model_all.save_weights(C.model_path)
break
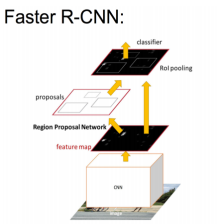
其实没什么绕的逻辑,都注释了,应该可以看明白的。好了基本的训练流程就讲完了,主要还是一些输入输出的形状比较绕,这个还真的多看看,多调试才能明白,测试那块我就不讲了,大同小异的。我就用比较好理解的方式做个总结吧,简单来说RPN用IOU来先筛选一次,然后做一次回归,然后再用非极大抑制进行筛选,最后再进行分类和回归网络的筛选和样本均衡,最后留下的才真正的进行分类和回归训练。其实我觉得思路不明白的时候可以看看论文,查查百度,多看几篇文章,多点理解。
我也看了很多文章参考,感谢他们提供的理解思路:
http://geyao1995.com/Faster_rcnn%E4%BB%A3%E7%A0%81%E7%AC%94%E8%AE%B0_test_2_roi_helpers/
https://blog.csdn.net/u011311291/article/details/81004067
https://yq.aliyun.com/articles/679245
https://blog.csdn.net/dta0502/article/details/79654931
https://blog.csdn.net/zijin0802034/article/details/77685438
https://zhuanlan.zhihu.com/p/31646362
https://www.cnblogs.com/wangyong/p/8513563.html
https://blog.csdn.net/g11d111/article/details/78829996
https://juejin.im/post/5d53f5da6fb9a06ad5471636
感悟
稀里糊涂的写了几篇文章,不知道要怎么写好,只能乱写,希望对大家理解有所帮助吧,其实我觉得更多的还是在这个过程中能更好的去理解这个算法,虽然只是一个几年前的算法,但是我觉得思想还是很经典的,而且也学到了目标检测的一些知识,也更加了解keras框架和numpy的一些操作,还是挺有意思的,后面有机会还会讲yolo和ssd,大家一起加油吧。本人只是个菜鸟,大神手下留情啊。
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵。














 996
996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









