







1 分析
首先对网页url进行分析。我们将第二页、第三页最后s=44改为s=0时,我们刚好获取的为第一页数据,所以我们总结出商品的页数为链接最后的s=44*ii为页数为[0,1,2,3…]
#第一页链接
#https://s.taobao.com/search?q=%E8%B6%85%E7%9F%AD%E8%A3%99&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180202&ie=utf8
#第二页链接
#https://s.taobao.com/search?q=%E8%B6%85%E7%9F%AD%E8%A3%99&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180202&ie=utf8&bcoffset=4&ntoffset=4&p4ppushleft=1%2C48&s=44
#第三页链接
#https://s.taobao.com/search?q=%E8%B6%85%E7%9F%AD%E8%A3%99&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180202&ie=utf8&bcoffset=4&ntoffset=4&p4ppushleft=1%2C48&s=88
其次对图片地址进行分析,使用chrome检查,我们得到元素位置如下,将其copy出来,加上http:浏览器打开即是我们想要的图片数据,但是图片并不是大图,我们注意到_360x360Q90.jpg_.webp,可能为将图片压缩,我们将其删除,同时加上http:,打开发现是大图。
#图片地址
#//g-search1.alicdn.com/img/bao/uploaded/i4/i1/2110184062/TB2ETSrXvnW1eJjSZFqXXa8sVXa_!!2110184062.jpg_360x360Q90.jpg_.webp
#//g-search3.alicdn.com/img/bao/uploaded/i4/i3/88504238/TB22FQtaPgy_uJjSZKPXXaGlFXa_!!88504238.jpg_360x360Q90.jpg_.webp即我们想要的图片地址为:
#http://g-search1.alicdn.com/img/bao/uploaded/i4/i1/2110184062/TB2ETSrXvnW1eJjSZFqXXa8sVXa_!!2110184062.jpg那么我们的解题思路已经出现:
获取每页的链接—对每页的源码正则提取图片地址—将图片地址加上http:—最后下载这个链接保存为jpg格式。
2 代码
在获取某一个产品的图时,会出现报错<urlopen error [Errno 61] Connection refused> python,没找到原因,但不影响程序的整体效果,可能是此产品的问题,使用try,except,使程序继续运行即可。其中代理服务器为可选。
#!/user/bin/env python
#-*- coding:utf-8 -*-
#auth:M10
import re
import urllib.request
import urllib.error
import time
keyword = "超短裙"
real_word = urllib.request.quote(keyword)#将关键词转换为link所识别的
def get_pics():
for i in range(0,10):
url = 'http://s.taobao.com/search?q='+real_word+'&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180202&ie=utf8&bcoffset=4&ntoffset=4&p4ppushleft=1%2C48&s='+str(i*44)#根据每一页的规律
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'referer':'https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=%E8%B6%85%E7%9F%AD%E8%A3%99&suggest=history_1&_input_charset=utf-8&wq=chaoduanq&suggest_query=chaoduanq&source=suggest'
}
time.sleep(2)
#proxy = urllib.request.ProxyHandler({'http':'60.23.46.24:80'})
#opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
#urllib.request.install_opener(opener)
request = urllib.request.Request(url,headers=header)
try:
data = urllib.request.urlopen(request, timeout=5).read().decode('utf-8', 'ignore')
except urllib.error.URLError as e:
print(e.reason)
print(e.code)
pat = '"pic_url":"(.*?).jpg"'#使用正则表达式获取图片地址
re_link = re.compile(pat).findall(data)
#print(re_link)
for j in range(0,len(re_link)):
time.sleep(2)
link = 'http:'+re_link[j]+'.jpg'
path = '/Users/wangxingfan/Desktop/data1/'+str(i)+str(j)+'.jpg'
try:
urllib.request.urlretrieve(link,path)#出错,不知道什么原因
except:
pass
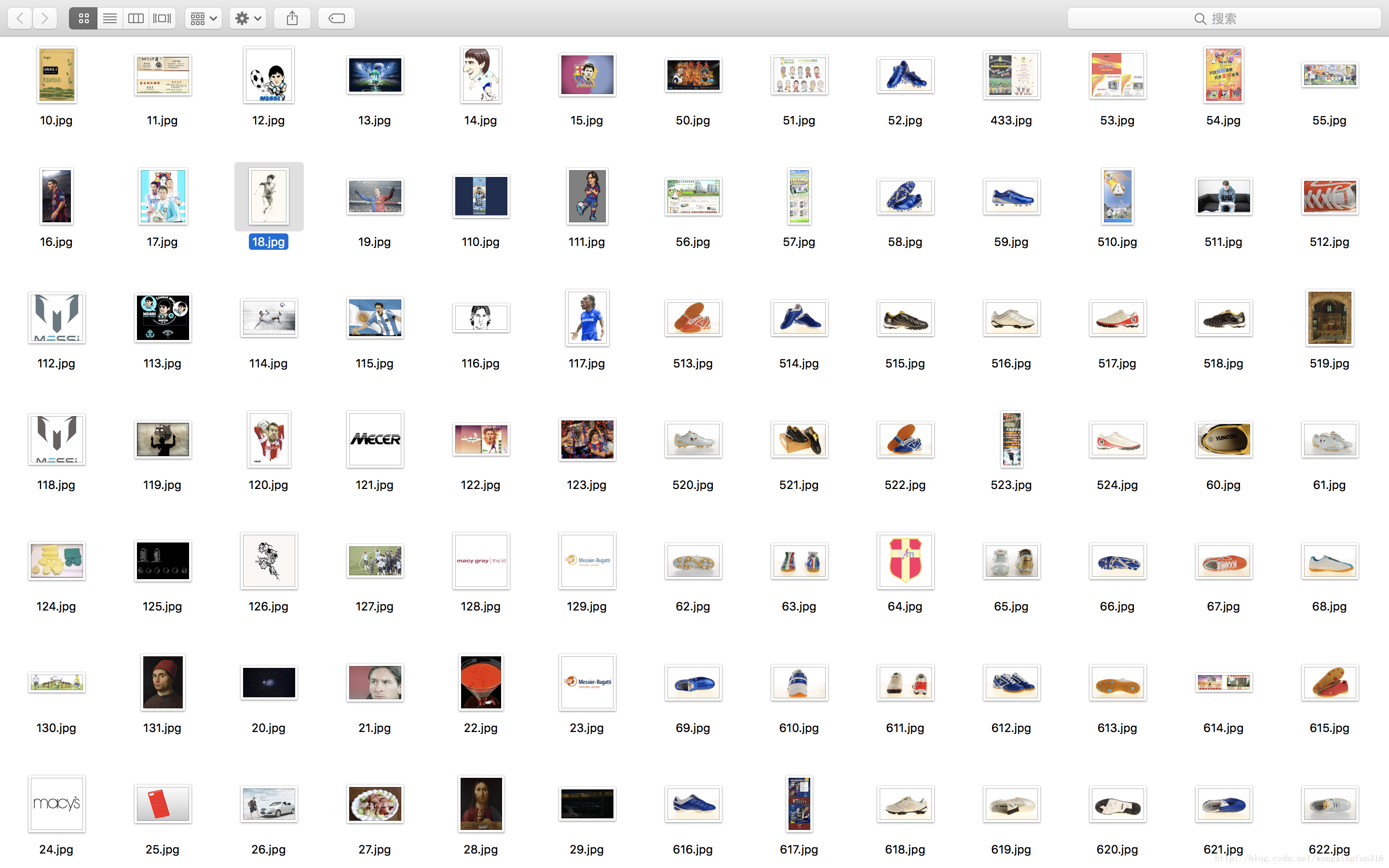
get_pics()3 运行结果

4 另一个例子
爬千图网,步骤基本一样。
#!/user/bin/env python
#-*- coding:utf-8 -*-
#auth:M10
import re
import urllib.request
import urllib.error
import time
def get_pics():
for i in range(1,7):
url = 'http://www.58pic.com/tupian/meixi-0-0-0'+str(i)+'.html'
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Referer':'http://www.58pic.com/tupian/meixi-0-0-1.html'
}
request = urllib.request.Request(url,headers=header)
try:
data = urllib.request.urlopen(request,timeout=5).read().decode('utf-8','ignore')
except urllib.error.URLError as e:
print(e.reason)
print(e.code)
pat = '"(http://pic.qiantucdn.com/58pic.*?)!/fw'
links = re.compile(pat).findall(data)
time.sleep(2)
for j in range(len(links)):
path = '/Users/wangxingfan/Desktop/data2/'+str(i)+str(j)+'.jpg'
try:
urllib.request.urlretrieve(links[j],path)
except:
pass
get_pics()














 3241
3241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









