








1.绪论
订阅号很早就有了,我最近闲了无事就像探索探索可以怎么玩。首先联想到就是微软小冰智能问答系统,还有很早时候有一个公众号提供了,根据c、c++函数名返回API具体用法的功能。那么这两个类似的功能如何实现呢。
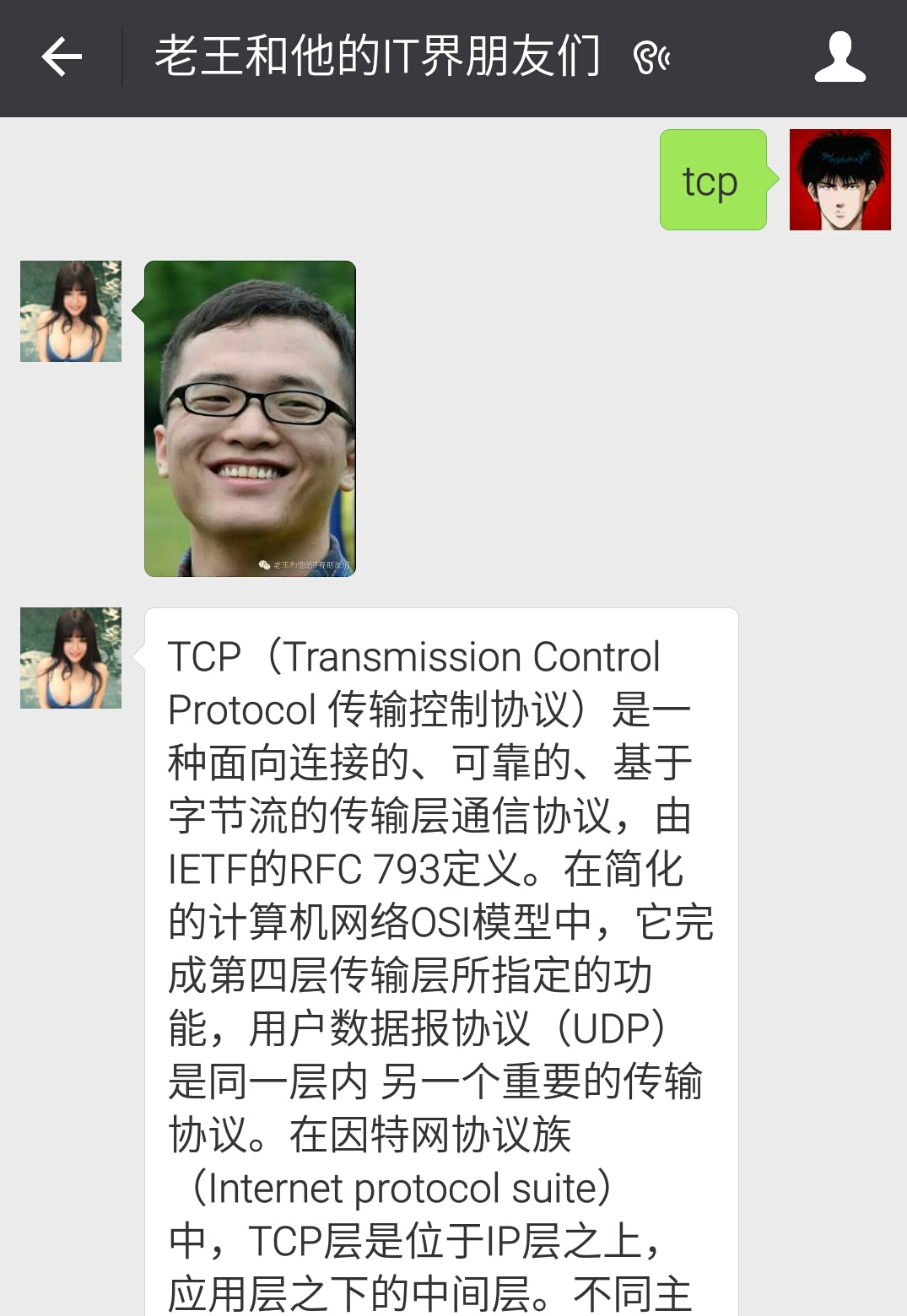
2.接入智能问答系统
首先个人需要申请一个公众号,接着在图灵机器人的官网:http://www.tuling123.com/
注册一个号,选择添加微信公众号,直接扫码关联,ok,智能问答系统接入成功!
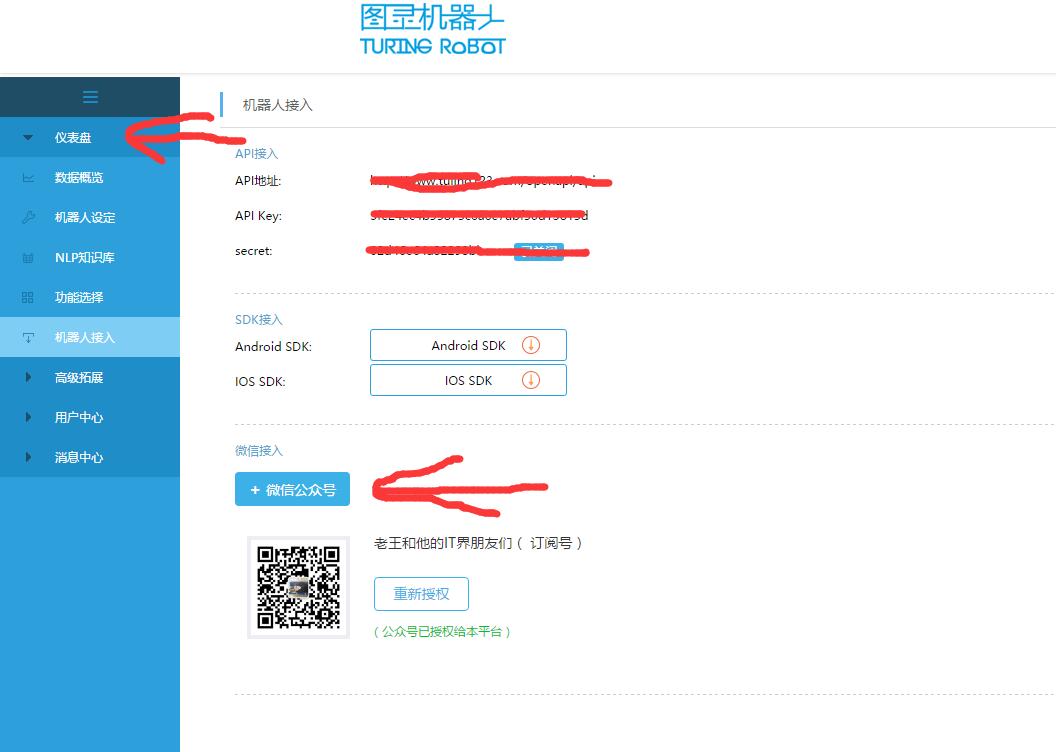
其实这个呢,是图灵机器人获取了微信的第三方接口,替你管理了微信号的消息回复功能,并且提供了下面的基本功能:其实比较简单,一些复杂的问题比如:给我订个到上海的机票,直接会回复去哪网的链接。相信这是图灵机器人的主要赚钱点,哈哈。

3.实现计算机专业英语辞典
那么类似提供c、c++ API 查询的功能是如何实现的呢?对于一个智能问答系统,API查询的功能其实可以抽象成一问一答的形式来做,由于暂时没有这方面的语料库,对于我们的公众号来说,哪一种功能比较类似呢?我想到了添加一个计算机专业英语的英译汉词典
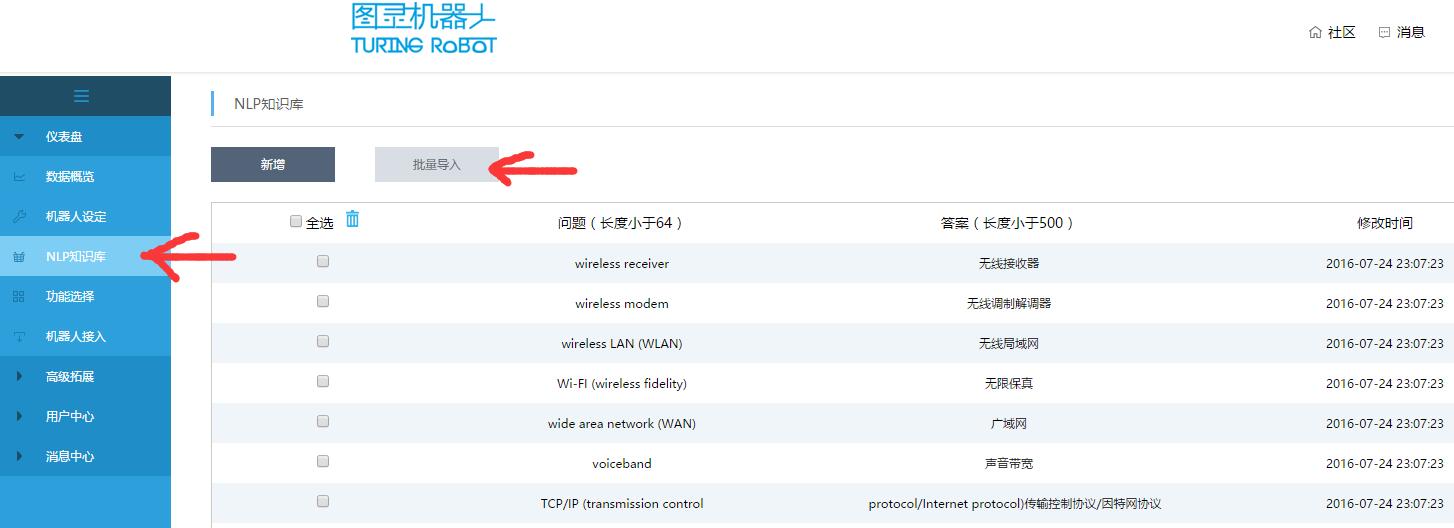
首先我们来看看,图灵机器人提供的知识库模板:
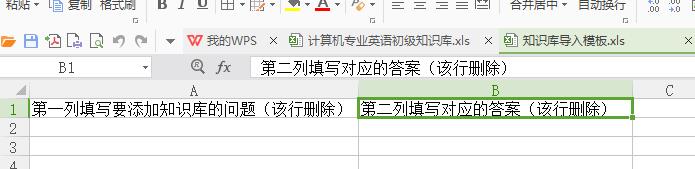
很好理解,其实就是两列文本,第一列为问题,比如你叫什么,第二列为答案。
这样的文本格式和词典也很好对应。于是我们上网找到一个txt格式的计算机专业英语基础英译汉词典:
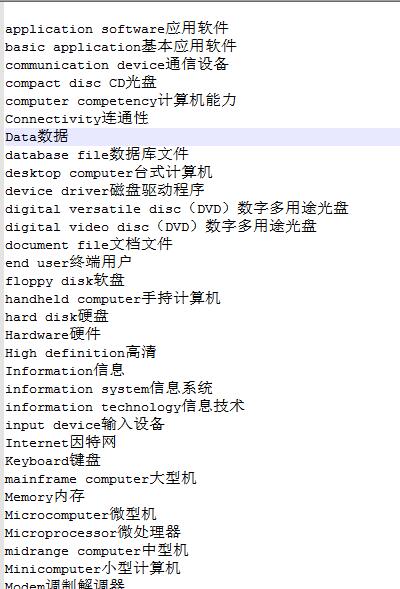
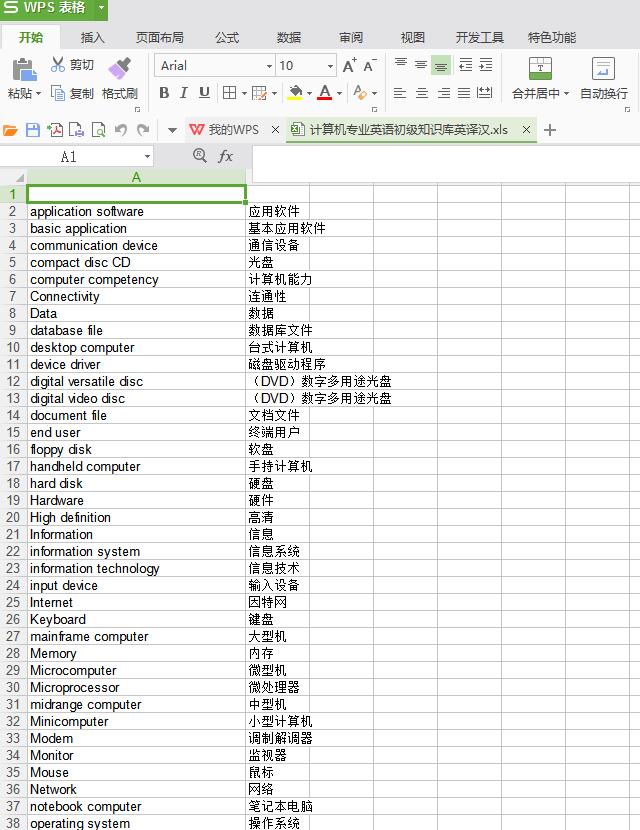
观察发现,前面是英文后面是汉语释义,很好弄,python正则匹配一下,区分出英文和汉字出现的位置,完后写到xls格式的文件中对应的单词和释义就好了:结构如下(问题对应单词,答案对应释义)
| 问题 | 答案 |
|---|---|
| 单词 | 释义 |
**另外一个需要注意的点就是文件编码,python默认都是utf-8的。
所以一般咱们txt这块处理中文都是得用gbk系列的(比如gb2312),在python中处理的时候都转换成unicode统一搞**
python代码如下:主要使用了可以操作excel文件的xlwt库,和正则表达式库re
# -*- coding: utf-8 -*-
"""
Spyder Editor
write data to xls,2016.7.24
主要实现将一些其他格式的数据转化成,图灵机器人可以识别的xls格式数据
"""
import os
import xlwt
import re
knowledge = []
def set_style(name,height,bold = False):
style = xlwt.XFStyle() #初始化样式
font = xlwt.Font() #为样式创建字体
font.name = name
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style
def write_excel(knowledge):
#创建xls工作薄
workbook = xlwt.Workbook(encoding = 'utf-8')
#创建sheet
data_sheet = workbook.add_sheet('first')
for i in range(len(knowledge)):
data_sheet.write(i,0,knowledge[i][0])
data_sheet.write(i,1,knowledge[i][1])
#保存文件
workbook.save('answer.xls')
print "successful write!"
x=xlwt.Workbook()
s1=x.add_sheet('sheet1')
if __name__ == '__main__':
info = open("know.txt")
print "中文"
#a = info.readlines()
#print a
for line in info:
line = line.decode('GB2312').encode('utf-8')
#print line 这块也可以整行进行拆分
# letter_str = re.findall(r'([a-zA-Z]+)',line,re.MULTILINE)
#hanzi_str = re.findall(r"([\x80-\xff]+)", line,re.MULTILINE)
#找到第一个出现汉字字符的位置,进行截断,分成两部分,分别写到两列中
hanstr = ''
yingstr = ''
index = 0
for i in line:
an = re.match(r"([\x80-\xff]+)", i)#判断一下是中文
if an:
break
else:
index = index +1
yingstr = line[0:index]
hanstr = line[index:len(line)]
print index
print hanstr
str = [yingstr,hanstr]
knowledge.append(str)
write_excel(knowledge)
'''
下面使用库xlwt进行操作excel文件的一些代码,希望大家有空能够用到
style1=xlwt.XFStyle() #样式类
style1.font.colour_index=30 #字体颜色前景色为红
style1.font.bold=True #粗体
style1.pattern.pattern=1 #填充solid
style1.pattern.pattern_fore_colour=2 #填充颜色红色
style2=xlwt.easyxf('font:italic on;pattern:pattern solid,fore-colour yellow')
#快速生成样式
#参数字符串格式:
#"class1:key1 value1,key2 value2;class2:k1 v1,k2 v2;"
s1.write(0,0,"Hello",style1)#写入字符串
s1.write(1,0,True,style2)#写入真值
s1.write(2,0,3.1415926);s1.write(2,1,-5);s1.write(2,2,xlwt.Formula("2*A3*ABS(B3)"));
#使用公式计算
s1.write(3,0,'right',xlwt.easyxf("align:horiz right"))
#调整对齐方式
x.save('example.xls') #保存
'''处理好的文件:
然后导入图灵机器人的知识库:
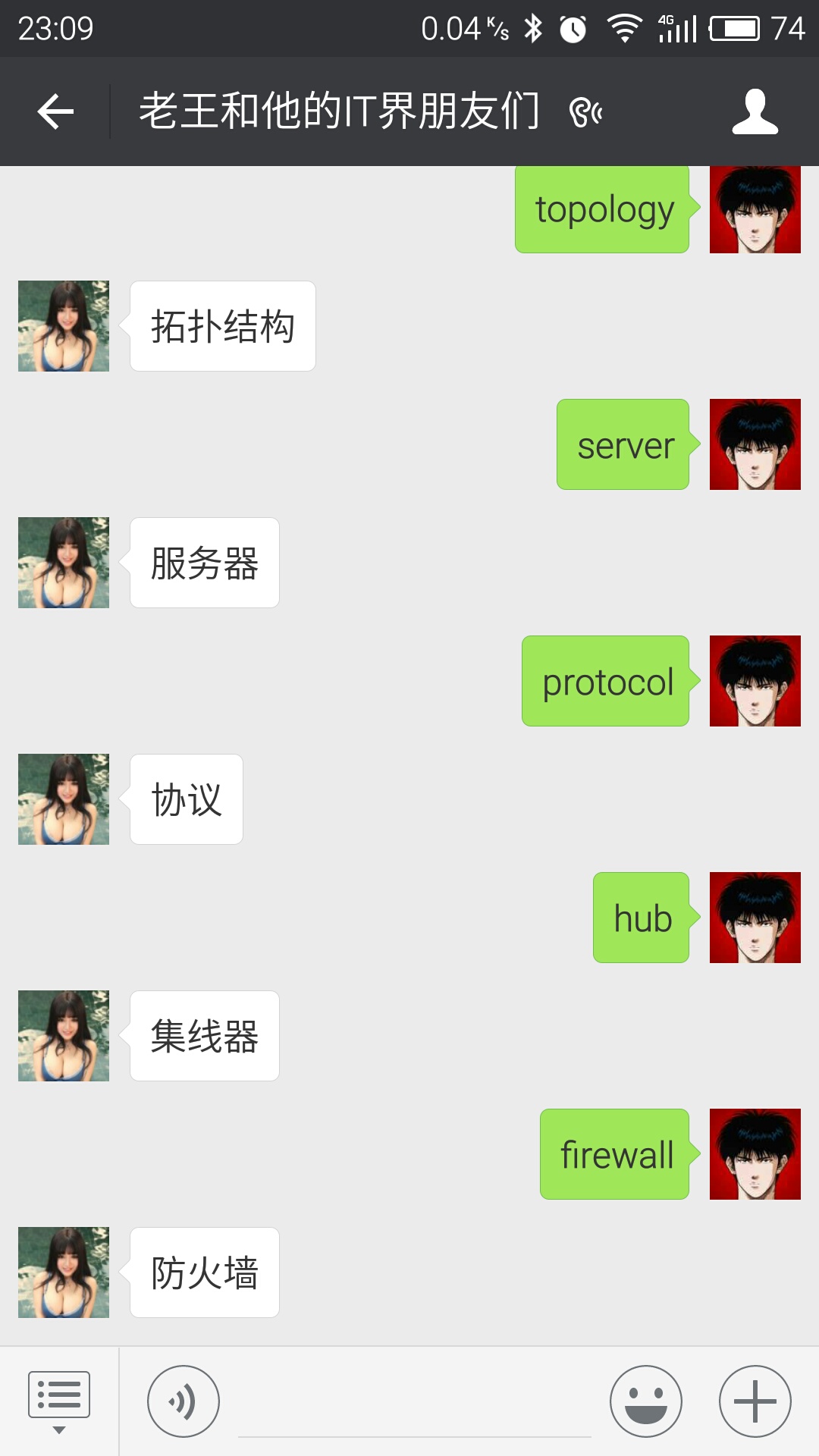
然后我们的订阅号就可以自动识别啦,那些查询的功能和词典大同小异,我想应该也是这么实现的吧。
4.实现效果
参考:(主要是编码转换和正则表达式)
http://bbs.csdn.net/topics/100172542
(正则表达式中汉语范围出自上面帖子的六楼,网上搜到的[\u4e00-\u9fa5]这个不是很好使,还请大牛指点一二)
http://blog.chinaunix.net/uid-21633169-id-4396998.html
xlwt使用介绍:
http://blog.csdn.net/wangkai_123456/article/details/50457284















 2556
2556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











