







最近在自己改写网络的过程中,发现了很多的问题,有一个比较大的问题就是过拟合问题,过拟合问题不仅出现在小数据量的训练中,在大数据量的训练中也有着同样的问题,今天测试了L1和L2正则化,效果还在实验中,如果效果比较好会在后面做及时的更新。
L1正则化:
L1 正则化公式也很简单,直接在原来的损失函数基础上加上权重参数的绝对值:
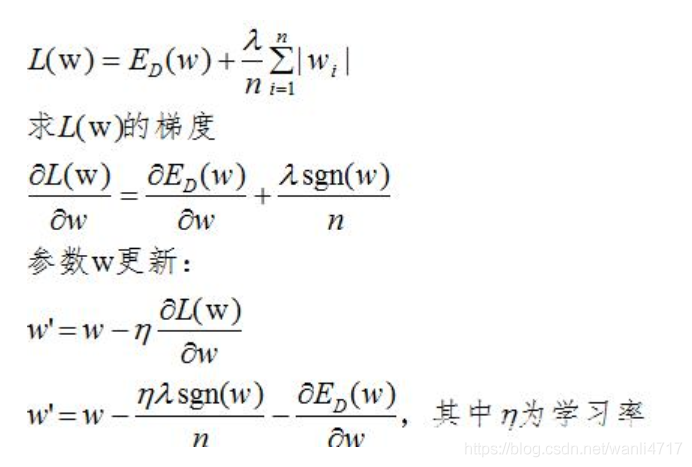
上式可知,当w大于0时,更新的参数w变小;当w小于0时,更新的参数w变大;所以,L1正则化容易使参数变为0,即特征稀疏化。
L2正则化:
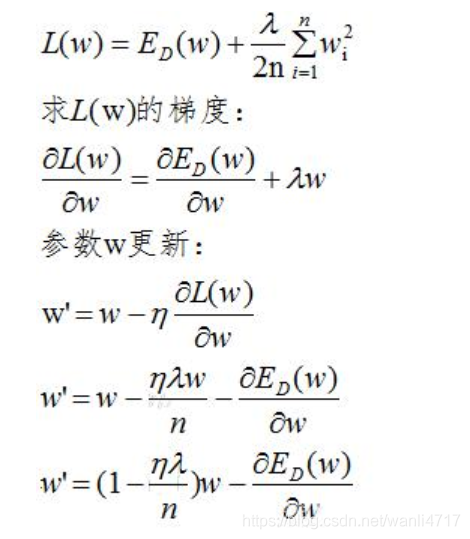
由上式可知,正则化的更新参数相比于未含正则项的更新参数多了
项,当w趋向于0时,参数减小的非常缓慢,因此L2正则化使参数减小到很小的范围,但不为0。
在pytorch中没有明确的添加L1和L2正则化的方法,但是可以直接的采用优化器自带的weight_decay选项来制订权重衰减,相当于L2正则化中的λ,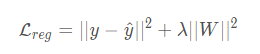
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-5)上面这是Adam优化器的一种达到L2正则化效果的一种方式。pytorch中还有很多这样的优化器,如SGD,Adadelta,Adam,Adagrad,RMSprop等,使用它很简单,你需要传入一个可迭代的参数列表(里面必须都是Variable类型的)进行优化,然后你可以指定一些优化器的参数,如学习率,动量,权值衰减等。
参考:














 3901
3901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









