







目前用于语义分割研究的两个最重要数据集是VOC2012和MSCOCO。
语义分割的方法主要包括两大类:基于解码的方法和基于上下文信息的方法
语义分割的通用框架:前端用FCN进行特征粗提取,后端使用条件随机场CRF或者马尔科夫随机场MRF优化前端输出,最后得到分割图。
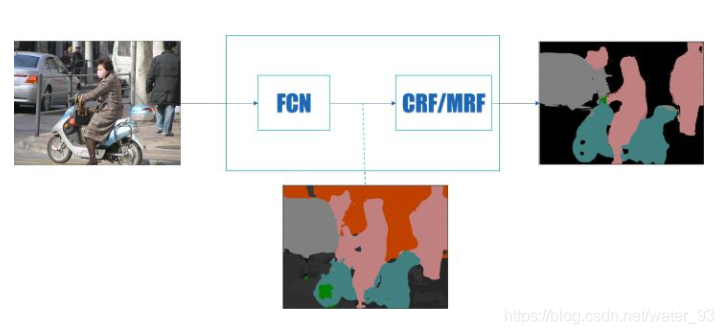
1、FCN:修改VGG网络,基于解码的方法
FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样,使它恢复到和输入图像相同的尺寸,从而可以对每个像素都产生了一个类别预测。FCN的重点是卷积化、上采样、跳跃结构。最后如何对每个像素进行分类预测得到分割图像:逐个像素求出在1000张图片中该像素位置的最大值(概率)作为该像素的分类。缺点是对各个像素进行分类,忽略了像素和像素之间的位置关系,上采样的图像边界模糊。
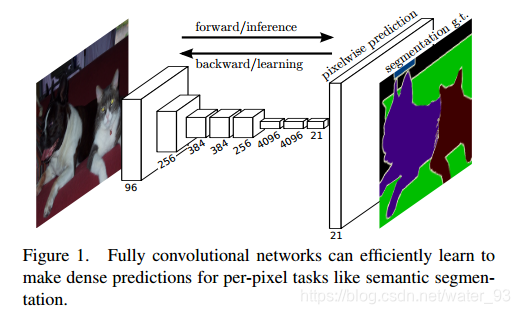
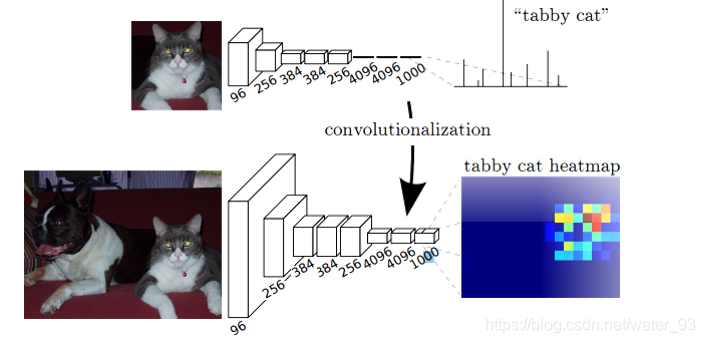
1)卷积化(Convolutional)
把全连接层去掉换成卷积层,使得网络可以接受任意大小的图像作为输入。
简单来说卷积化就是将其最后三层全连接层全部替换成卷积层。前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个类别的概率(全连接层+softmax输出)。FCN将这3层表示为卷积层,卷积核的大小(通道数,宽,高)分别为(4096,1,1)、(4096,1,1)、(1000,1,1)。
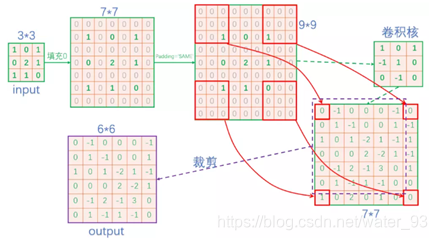
2)上采样:先padding填充0,然后进行卷积,最后进行crop裁减。
填充0 --- 卷积 --- 裁减
上采样的卷积核:作者论文中kernel是可以被训练的,也可以是固定的,即默认的二维bilinear kernel
3)跳跃结构
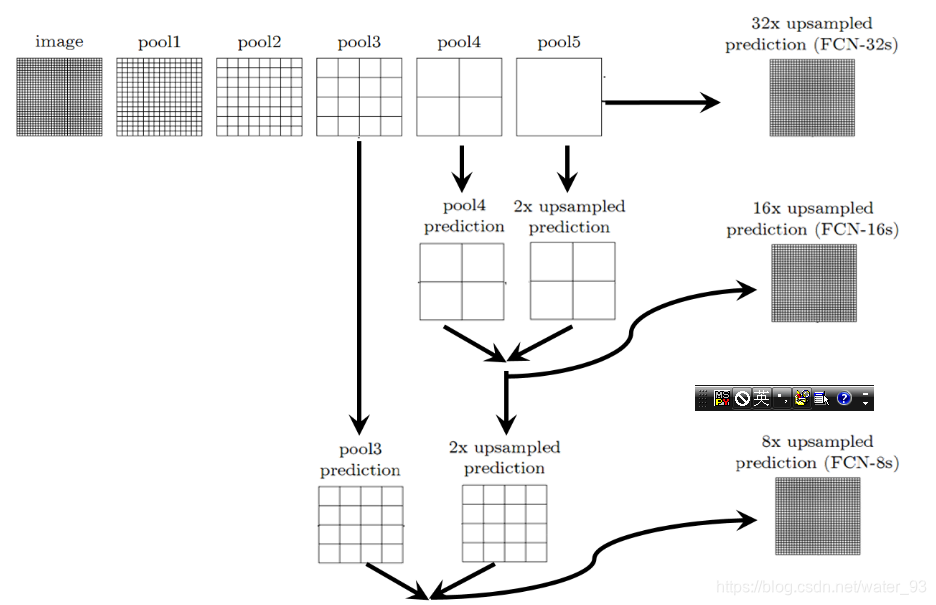
特征融合(相加):不同大小的特征map进行上采样,并进行融合;例如pool4层卷积后的结果和pool5层2倍上采样的结果相加,然后上采样到输入图像尺寸得到FCN-16s分割结果。
较浅的卷积层感受域比较小,学习感知细节部分的能力强,较深的卷积层感受域相对较大,适合学习较为整体的、相对更宏观一些的特征。所以在较深的卷积层上进行反卷积还原,自然会丢失很多细节特征。














 1114
1114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









