







一、简介
EM(Expectation-Maximum)算法也称期望最大化算法,曾入选“数据挖掘十大算法”中,可见EM算法在机器学习、数据挖掘中的影响力。EM算法是最常见的隐变量估计方法,在机器学习中有极为广泛的用途,例如常被用来学习高斯混合模型(Gaussian mixture model,简称GMM)的参数;隐式马尔科夫算法(HMM)、LDA主题模型的变分推断等等。本文就对EM算法的原理做一个详细的总结。
二、EM算法推导
一般的用Y=(y1, y2,…, yn)表示观测数据,用H=(h1, h2,…,hn)表示隐变量数据,用Z(z1, z2, … , zm)表示每个hi的所有可能取值的集合,所以Z可以称之为隐变量分布,因为每个hj都来自Z。
观测数据Y是我们可以直接看见并使用的,但是隐藏数据H我们却不知道,所以我们只能求观测数据Y的对数似然函数log P(Y;θ)的极大化来求最优参数θ。
##########分析一下观测数据Y、隐变量数据H和隐变量分布Z之间的关系###########
隐变量数据H和观测数据Y之间的关系如下:
观测数据 yj 在隐变量数据 hj 的基础上得到,其中hj∈Z。最重要的是观测数据Y可知,隐变量分布Z也可知,但是隐变量数据H不可知。
这里举一个隐变量数据和观测数据的例子,假设有3枚硬币A, B, C,我们先抛硬币A,根据硬币A的结果决定接下来抛硬币B还是硬币C。如果硬币A正面朝上,我们就抛硬币B,若硬币B正面朝上记yj=1,若硬币B反面朝上记yj=0;如果硬币A反面朝上,我们就抛硬币C,若硬币C正面朝上记yj=1,若硬币C反面朝上记yj=0。假设进行5次上述试验,我们得到 观测数据Y=(1, 0, 0, 0, 1),如果用H=(h1, h2, h3, h4, h5)表示隐变量数据,那么每个hi的所有可能取值的集合Z=(A正,A反),所以H有25 种可能,隐变量数据可以是H=(A正,A正,A反,A正,A反) ,这只是25 中的一种。
#################################结束################################
先来求一下观测数据Y=(y1, y2,…, yn)的似然函数:
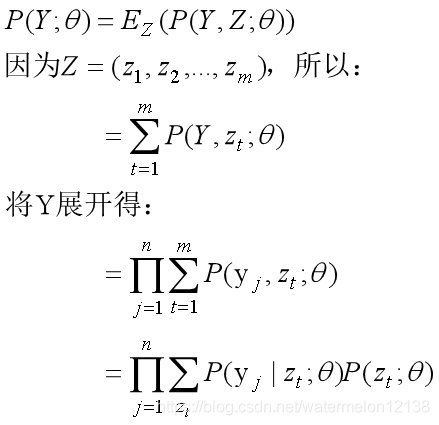
公式的前半部分用到了联合概率与边缘概率的转换,公式的后半部分则是根据具体的数据来展开。
所以观测数据Y的对数似然函数log P(Y;θ)可以表示为:
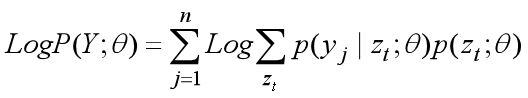
我们将观测数据Y的对数似然函数log P(Y;θ)记作L(θ),即L(θ) = Log P(Y;θ)。
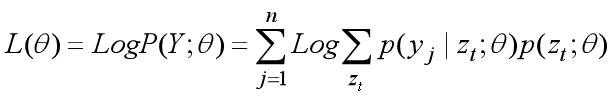
EM算法通过迭代逐步极大化L(θ)来一步步优化参数θ,比如第 i 次迭代我们得到参数的估计值为θ(i),那么我们希望在第 i+1 次迭代得到的参数估计值θ(i+1)能使得L(θ)能再次增加,即L(θ(i+1)) > L(θ(i)),就这样一步步使得L(θ)达到极大。
因为L(θ)的式子已经固定,现在考虑怎么保证 i+1次 迭代时L(θ)可以再增加,EM算法用了一个比较巧妙的方法,那就是求L(θ)的下界,即L(θ) ≥ 下界,只要保证每次迭代时L(θ)的下界取极大,就可以保证L(θ)一直在增加。
现在来求一下在第 i+1次迭代时L(θ)的下界,只要保证每一次迭代L(θ)的下界都取极大,就能保证L(θ) 在每一次迭代过程中有尽可能的增长。
####################################################################
先介绍一下Jensen不等式
Jensen不等式定义如下:
定义(1):
如果f(x)是凸函数,xi(i=1, 2,…, m)来自f(x)的定义域,λi(i=1, 2,…, m) ≥ 0且相加之和等于1,则有如下不等式成立:
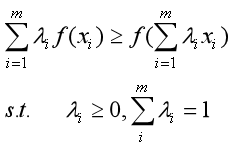
当且仅当xi≡ C(恒等于常数C)时,等号成立。
注:如果f(x)是凹函数则不等号反向。
定义(2):
如果f(x)是凸函数,将定义(1)中的 xi 看作随机变量X的每种取值,将λi看作随机变量X的每种取值xi 对应的概率,则有如下不等式成立:
E[f(X)] ≥ f(E[X])
当且仅当随机变量X是常量时,该式取等号。其中,E(X)表示X的数学期望。
注:如果f(x)是凹函数则不等号反向。
################################结束##################################
L(θ)的表达式如下:
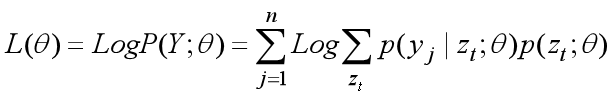
利用Jensen不等式求解第i+1次迭代时L(θ)的下界,过程如下。
首先根据Jensen不等式的定义1,构造出λi:
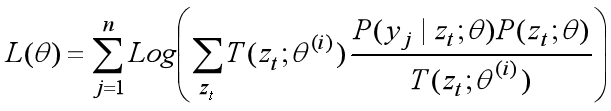
T(zt;θ(i))就是我们的λi,λi必须是一个已知的值,因为正在求第i+1次迭代时L(θ)的下界,所以参数θ在第 i 次的估计值θ(i) 是已知的,所以T(zt;θ(i))这个式子必须是在θ(i) 给定条件下它才是已知的。
将上式换一种记法表示如下: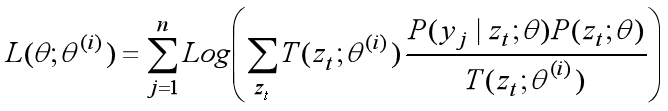
然后利用根据Jensen不等式的定义1得到第 i+1 次迭代时L(θ,θ(i) )的下界,过程如下:
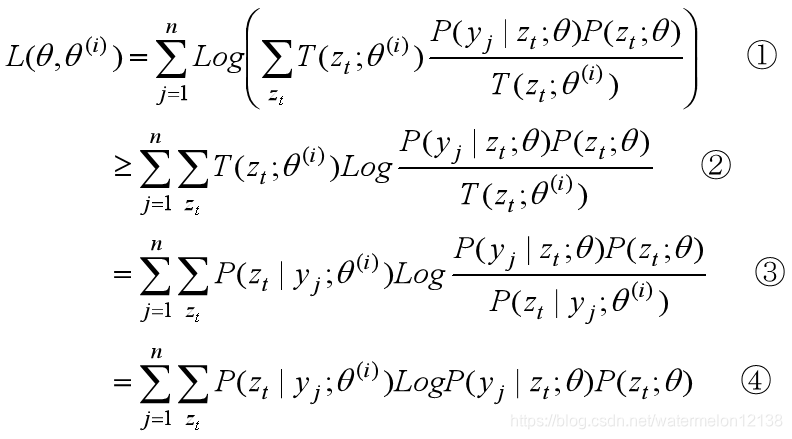
式1到式2:
将T(zt;θ(i))看作λ i ,将P(yj | zt;θ)P(zt;θ) / T(zt;θ(i))看作 xi, 根据Jensen不等式的定义1可得到。
式2到式3:
将θ(i)带入L(θ,θ(i))中得:
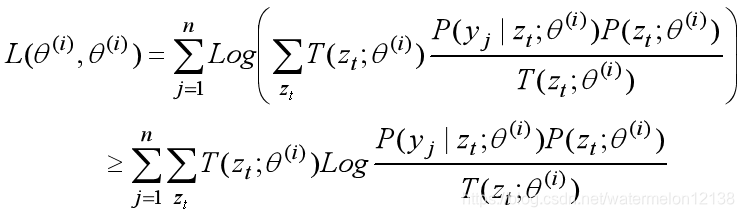
因为Jensen不等式成立的约束条件如下:
约束1:
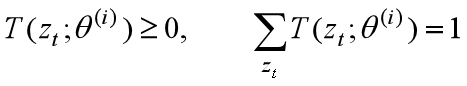
约束2:
Jensen不等式的等号成立条件是xi≡C,即
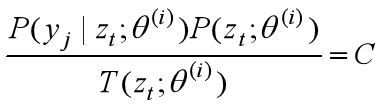
联合上述两个约束条件得:
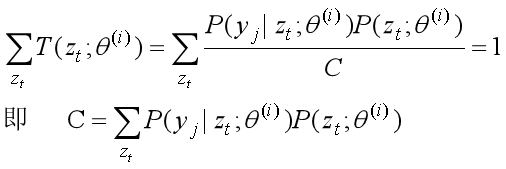
所以得:
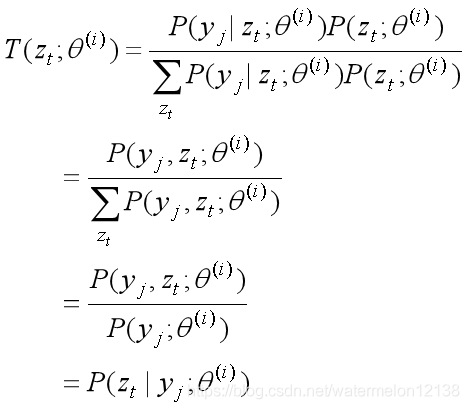
式3到式4:
因为这是第i+1次迭代时L(θ)的下界,所以第 i 次迭代参数θ的估计值θ(i) 是已知的,所以P(zt | yj;θ(i))和Log P(zt | yj;θ(i))是常数项,去掉式3中的常数项就得到了式4。
证毕
令Q(θ,θ(i))表示第 i+1 次迭代时L(θ)的下界,则Q(θ,θ(i)) = 式4,即
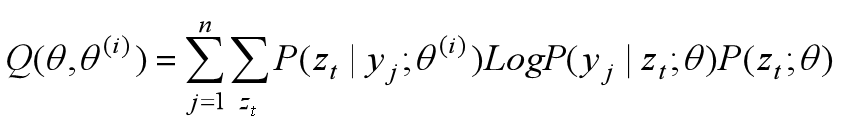
那么使得Q(θ,θ(i))取极大的参数θ就是第 i+1 次迭代的最优参数估计值θ(i+1) ,即
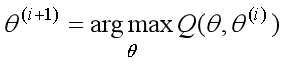
上述过程就是EM算法的一次迭代过程,E步(求期望)是得到Q(θ, θ(i))表达式,M步是求解Q(θ, θ(i))的极大化。EM算法是不断求解下界的极大化来逼近求解对数似然函数极大化的算法。
三、EM算法的收敛性
这里给出两个定理。
定理1:
设P(Y;θ)是观测数据Y的似然函数,θ(i) (i=1, 2,…)为EM算法得到的参数估计序列,P(Y;θ(i))为对应的似然函数序列,那么似然函数序列是单调递增序列即P(Y;θ(i+1)) ≥ P(Y;θ(i))。
定理2:
设P(Y;θ)是观测数据Y的似然函数,L(θ)=Log P(Y;θ)是观测数据的对数似然函数,θ(i) (i=1, 2,…)为EM算法得到的参数估计序列,L(θ(i))(i=1, 2,…)为对应的对数似然函数序列。则有:
(1)如果观测数据的似然函数P(Y;θ)有上界,那么对数似然函数序列L(θ(i))(i=1, 2,…)是收敛的。
(2)在一定条件下,EM算法得到的参数估计序列θ(i) (i=1, 2,…)的收敛值θ*是L(θ)的稳定点。
EM算法的收敛性包含了对数似然函数序列L(θ(i))(i=1, 2,…)的收敛性和参数估计序列θ(i) (i=1, 2,…)的收敛性,前者并不蕴含后者。上述定理只能保证参数估计序列收敛到对数似然函数序列的稳定点,不能保证收敛到对数似然函数序列的极大值点。
四、EM算法
输入:观测变量数据Y,隐变量分布Z
输出:模型参数θ
(1)选择参数的初值θ(0) ,开始迭代。
(2)E步:记θ(i) 为第 i 次迭代参数θ的估计值,则在第 i+1 次迭代时计算Q(θ, θ(i))。
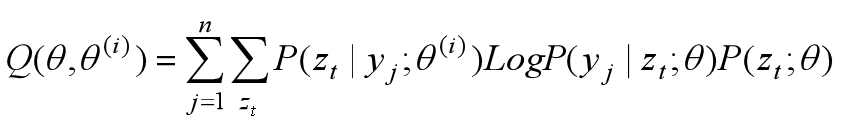
(3)M步:求Q(θ, θ(i))的极大化,确定第 i+1 次迭代参数θ的估计值。
求Q(θ, θ(i))的极大化时,可以分别对参数θ的每一项求偏导并导数等于0。
(4)重复步骤2和3,直到收敛。
五、例题
假设有3枚硬币A, B, C,它们正面朝上的概率分别是π,p,q。先进行如下试验:我们先抛硬币A,根据硬币A的结果决定接下来抛硬币B还是硬币C。如果硬币A正面朝上,我们就抛硬币B,若硬币B正面朝上记yj=1,若硬币B反面朝上记yj=0;如果硬币A反面朝上,我们就抛硬币C,若硬币C正面朝上记yj=1,若硬币C反面朝上记yj=0。独立的进行n次试验,这里n=10,得到如下观测结果:
1,1,0,1,0,0,1,0,1,1
根据这组观测结果,如何估计3枚硬币模型正面朝上的概率,即3枚硬币模型的参数。
解:
首先,弄清楚观测数据Y=(1,1,0,1,0,0,1,0,1,1),隐变量分布Z=(A正,A反)。
其次,求出第 i+1次迭代时的L(θ)的下界。这里参数θ=(π,p,q),其中θ(i)=(π(i),p(i),q(i))是参数θ第 i 次迭代时的估计值。
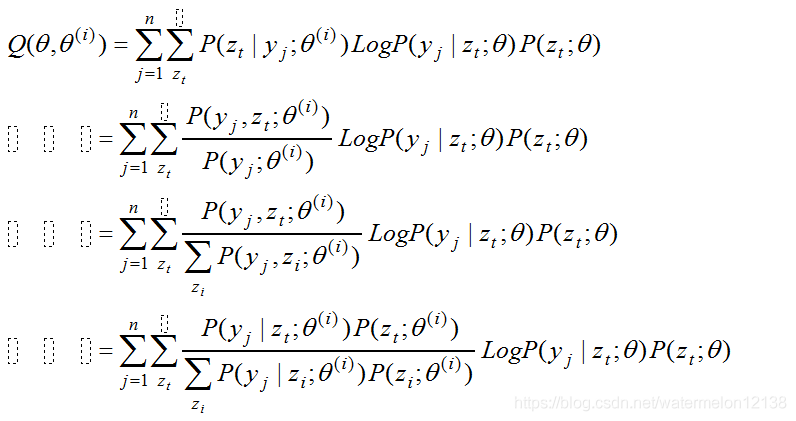
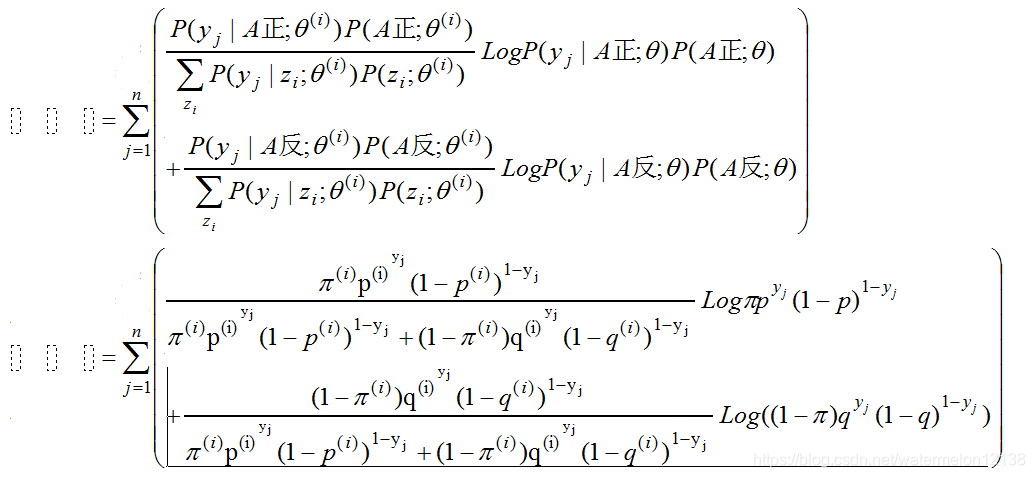
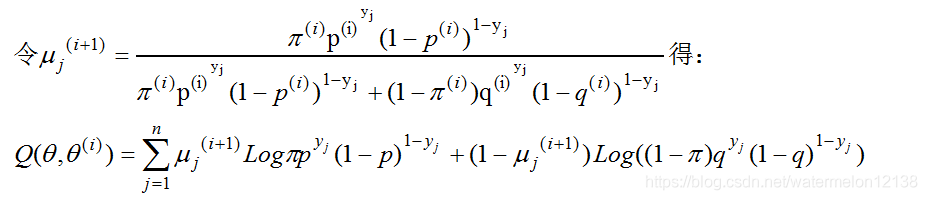
接着求出参数θ在第 i+1次迭代时的更新公式:


有了参数θ=(π,p,q)在每次迭代时的更新公式就就大功告成了,根据这道题的我们先给参数θ赋初值,即θ(0) =(0.5,0.5,0.5)。
现在开始从 i =0 时开始迭代,
π(1)=0.5,p(1)=0.6,q(1) =0.6
i =1时:
π(2)=0.5,p(2)=0.6,q(2) =0.6
i =2时:
π(1)=0.5,p(1)=0.6,q(1) =0.6
显然这已经收敛了,所以参数θ=(π,p,q)的极大似然估计为:
π^ =0.5,p^ =0.6,q^ =0.6
EM算法与选择的初值有关,不同的初值得到的参数估计值不同。
喜欢的话,麻烦可爱的你点个赞或者关注嗷。














 565
565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









