







一直以来,都想好好学习学习编译原理。但是一直各种理由没有静下心来好好看看。现在就用博客的形式,记录自己学习编译原理的点点滴滴。如有错误之处,还请指出。
习惯糗事百科的分割,咱就先来一个华丽丽的分隔符
===============================分隔符=============================================
对于我们常用的语言,C/C++,Java,C#等源程序是给我们IT狗自己看的,其实就是文本文件,可以使用vi,记事本等文本编辑程序打开、编辑。但是对于计算机来说,目前智能水平还不够(google阿法狗也就只能和人类下下围棋),无法理解我们IT狗所能看懂的源程序,怎么办呢?那就需要一个专门的程序来翻译我们IT狗能看懂的源程序,让计算机也能理解的语言。这个程序就是编译器,它对源程序的翻译过程,就是编译过程。
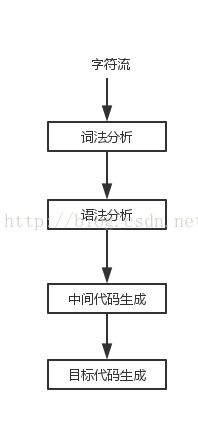
一个编译器的大致步骤如下:
例如:
int max(int a,int b)
{
int c = a>b?a:b;
}
int main()
{
int c=max(2,3);
return 0;
}
对于上述源代码,我们IT狗是很容易理解,以文本形式保存后,上述源代码在计算中存储的形式为:
69 64 74 20 66 7A 6B 74 30 ……
就是一连串的16进制的数字而已,也就是字符流。对于字符流,看不出关键字、运算符、标识符。那编译器第一步要做的工作就是词法分析,目的就是在连续的字符中识别出一个一个的符号,尽可能识别出符号的属性。例如:
69 64 74 => int (数字随便写的,只是演示作用)
20 66 7a => max
……
词法分析阶段,能够根据输入的字符流能够识别出符号的含义,它们所包含的关键字、数字、字符串、分隔符、数字等。
词法分析阶段以后,就是把对应的输出作为语法分析。语法分析的作用就是把从词法分析识别出的符号流中识别出符合编程语言语法的语句。语法分析的结果以树型结构保存,称之为语法树。语法树承载了源程序的全部信息,后续的转换工作就与源程序无关了。
在当前,我们有很多不同的硬件平台,intel、ARM、PowerPC,以及32位和64位等等,为了能够把我们的程序更好的在不同硬件平台上运行,编译器把语法树先转换为一个通用的,抽象的“CPU指令”,这就是中间代码最初的设计思路,然后根据具体选定的CPU,将中间代码落实到具体CPU的目标代码。
选定具体CPU,操作系统后,中间代码就转换为目标代码--汇编代码。然后汇编器依照选定操作系统的目标文件格式,将汇编文件转换为具体的目标文件。对于linux而言是.o文件,window系统是.obj文件。目标文件已经是选定CPU的机器指令了。
最后一步就是链接器把一个或多个目标文件链接成符合操作系统指定格式的可执行文件。通过操作系统,可执行程序就可以被载入内存执行了。
这就是编译器所做的工作。编译器其实也就是一个软件。














 1105
1105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









