







对于之前写过的腐蚀膨胀加上一个小功能,或者直接单独看这个小功能也行。其实很简单,但我可能写得还不多,所以中间出过很多小问题,终于解决了。
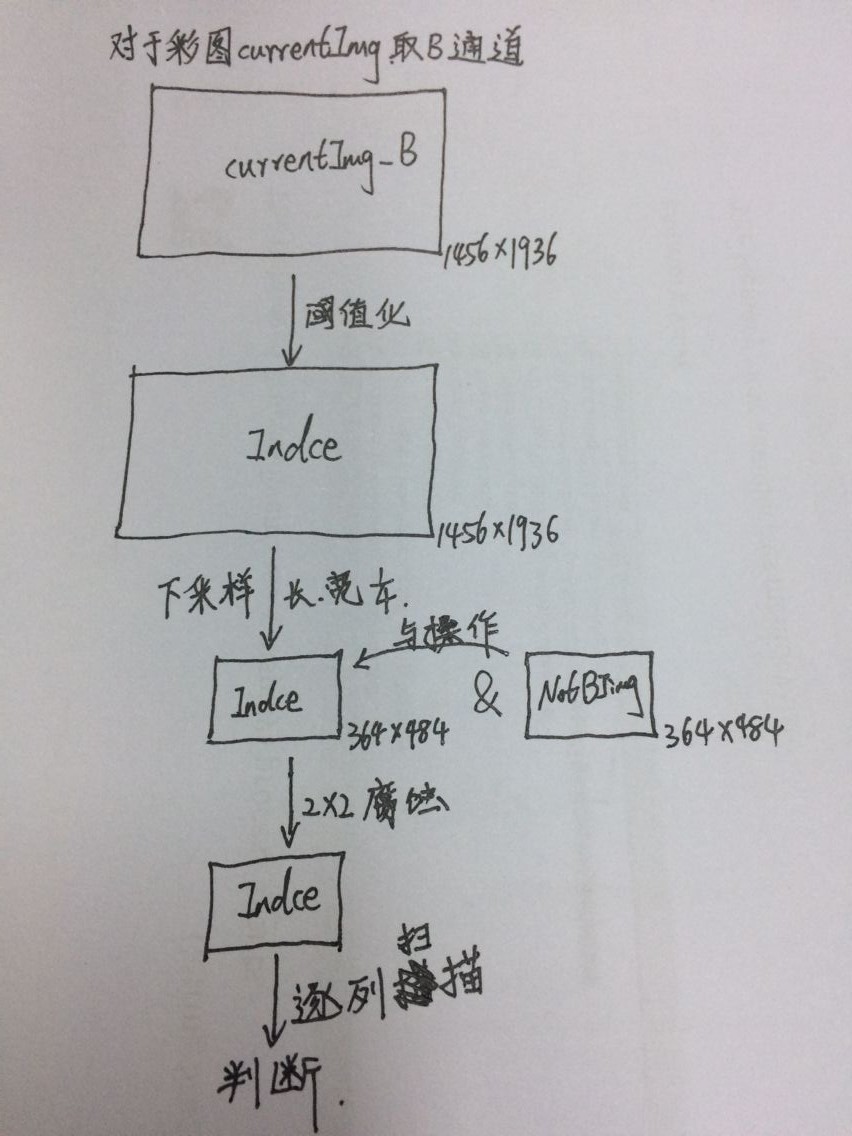
一、初步正确的版本是这样写的:(单线程下)
int main()
{
char front[100];
char back[100];
cl_uint platformNum;
cl_int status;
status=clGetPlatformIDs(0,NULL,&platformNum);
if(status!=CL_SUCCESS){
printf("cannot get platforms number.\n");
return -1;
}
cl_platform_id* platforms;
platforms=(cl_platform_id*)alloca(sizeof(cl_platform_id)*platformNum);
status=clGetPlatformIDs(platformNum,platforms,NULL);
if(status!=CL_SUCCESS){
printf("cannot get platforms addresses.\n");
return -1;
}
cl_platform_id platformInUse=platforms[0];
cl_device_id device;
status=clGetDeviceIDs(platformInUse,CL_DEVICE_TYPE_DEFAULT,1,&device,NULL);
cl_context context=clCreateContext(NULL,1,&device,NULL,NULL,&status);
cl_command_queue queue=clCreateCommandQueue(context,device,CL_QUEUE_PROFILING_ENABLE, &status);
std::ifstream srcFile("/home/jumper/OpenCL_projects/FluoreTest12Channels/objDetectandFluore.cl");
std::string srcProg(std::istreambuf_iterator<char>(srcFile),(std::istreambuf_iterator<char>()));
const char * src = srcProg.c_str();
size_t length = srcProg.length();
cl_program program=clCreateProgramWithSource(context,1,&src,&length,&status);
status=clBuildProgram(program,1,&device,NULL,NULL,&status);
if (status != CL_SUCCESS)
{
shrLogEx(LOGBOTH | ERRORMSG, status, STDERROR);
oclLogBuildInfo(program, oclGetFirstDev(context));
oclLogPtx(program, oclGetFirstDev(context), "oclfluore.ptx");
cout<<"build kernel error..."<<status<<endl;
return(EXIT_FAILURE);
}
//get the csv model from the disk.
const int rgbsize=256*256*256;
uchar* rgbarray = new uchar[rgbsize];
memset(rgbarray, 0, rgbsize * sizeof(uchar));
Ptr<ml::TrainData> ygdata=cv::ml::TrainData::loadFromCSV("/home/jumper/OpenCL_projects/FluoreTest12Channels/fluo_id.csv",0,-2,0);
Mat csvimg2=ygdata->getSamples();
int csvrows=csvimg2.rows; //csv points
//cout<<"primer csvrows:"<<csvrows<<endl;
for (int j = 0; j < csvrows; j++)
{
float* pixeldata = csvimg2.ptr<float>(j);
float x = pixeldata[0];
float y = pixeldata[1];
float z = pixeldata[2];
int newindex = x + y * 256 + z * 256 * 256;
rgbarray[newindex] = 255;
}
TickMeter tm;
tm.start();
//get the src images from the disk.
int imgwidth,imgheight;
imgheight=1456;
imgwidth=1936;
int pixels=imgheight*imgwidth;
int srcdatasize=pixels*3*sizeof(uchar);
cl_kernel kernel_imgProc=clCreateKernel(program,"imgProcess",NULL);
cl_mem rgbArray_buffer,srcdata_buffer,srcdata_back_buffer,sumArray_buffer;
rgbArray_buffer=clCreateBuffer(context,CL_MEM_READ_ONLY ,rgbsize*sizeof(uchar),0,&status);
status = clEnqueueWriteBuffer(queue, rgbArray_buffer, CL_FALSE, 0, rgbsize * sizeof(uchar), rgbarray, 0, NULL, NULL);
srcdata_buffer = clCreateBuffer(context, CL_MEM_READ_ONLY, srcdatasize, NULL,&status);
srcdata_back_buffer = clCreateBuffer(context, CL_MEM_READ_ONLY, srcdatasize, NULL,&status);
size_t sumsize=1454*2*sizeof(int);
sumArray_buffer = clCreateBuffer(context, CL_MEM_WRITE_ONLY| CL_MEM_ALLOC_HOST_PTR, sumsize, NULL,&status);
status = clSetKernelArg(kernel_imgProc, 0, sizeof(cl_mem), (void*)&rgbArray_buffer);
status = clSetKernelArg(kernel_imgProc, 3, sizeof(cl_int), &imgwidth);
status = clSetKernelArg(kernel_imgProc, 4, sizeof(cl_int), &imgheight);
status = clSetKernelArg(kernel_imgProc, 5, sizeof(cl_mem), (void*)&sumArray_buffer);
int thre_blue_host=15;
int thre_dis_host=40;
int haveStone[1]={0};
cl_mem haveStone_buffer=clCreateBuffer(context, CL_MEM_READ_WRITE| CL_MEM_ALLOC_HOST_PTR, sizeof(int), NULL,&status);
Mat Bjimg=imread("/home/jumper/OpenCL_projects/FluoreTest12Channels/blackcor_rotate.bmp",0);
//cout<<"channels:"<<Bjimg.channels()<<endl;
cl_mem Bjimg_buffer=clCreateBuffer(context,CL_MEM_READ_ONLY ,484*364*sizeof(uchar),0,&status);
status = clEnqueueWriteBuffer(queue, Bjimg_buffer, CL_FALSE, 0, 484*364* sizeof(uchar), Bjimg.data, 0, NULL, NULL);
status = clSetKernelArg(kernel_imgProc, 6, sizeof(cl_int), &thre_blue_host);
status = clSetKernelArg(kernel_imgProc, 7, sizeof(cl_mem), (void*)&Bjimg_buffer);
status = clSetKernelArg(kernel_imgProc, 8, sizeof(cl_int), &thre_dis_host);
size_t localsize[2]={256,1};
//size_t globalsize[2]={512,1024};
size_t globalsize[2]={512,1454};
for(int ii=1;ii<101;ii++)
{
status = clEnqueueWriteBuffer(queue, haveStone_buffer, CL_FALSE, 0, sizeof(int), haveStone, 0, NULL, NULL);
status = clSetKernelArg(kernel_imgProc, 9, sizeof(cl_mem), (void*)&haveStone_buffer);
sprintf(front, "/home/jumper/OpenCL_projects/FluoreTest12Channels/front/%d.bmp", ii);
Mat srcimg=imread(front);
sprintf(back, "/home/jumper/OpenCL_projects/FluoreTest12Channels/back/%d.bmp", ii);
Mat srcimg_back=imread(back);
status = clEnqueueWriteBuffer(queue, srcdata_buffer, CL_FALSE, 0, srcdatasize, srcimg.data, 0, NULL, NULL);
status = clEnqueueWriteBuffer(queue, srcdata_back_buffer, CL_FALSE, 0, srcdatasize, srcimg_back.data, 0, NULL, NULL);
status = clSetKernelArg(kernel_imgProc, 1, sizeof(cl_mem), (void*)&srcdata_buffer);
status = clSetKernelArg(kernel_imgProc, 2, sizeof(cl_mem), (void*)&srcdata_back_buffer);
status =clEnqueueNDRangeKernel(queue, kernel_imgProc, 2, NULL, globalsize, localsize,0,NULL,NULL);
if (status != CL_SUCCESS)
{
cout<<"clEnqueueNDRangeKernel() failed..."<<status<<endl;
return(EXIT_FAILURE);
}
status=clFinish(queue);
if (status != CL_SUCCESS)
{
cout<<"clFinish() failed..."<<status<<endl;
return(EXIT_FAILURE);
}
int *sumMap=NULL;
sumMap=(int*)clEnqueueMapBuffer(queue,sumArray_buffer,CL_TRUE, CL_MAP_READ, 0, sumsize, 0, NULL, NULL, &status);
clEnqueueUnmapMemObject(queue, sumArray_buffer, (void*)sumMap, 0, NULL, NULL);
int finalSum=0;
int finalSum_back=0;
int final=0;
for(int j=0;j<1454;j++)
{
finalSum+=sumMap[j];
finalSum_back+=sumMap[1454+j];
//cout<<"ID: "<<j<<"--Value: "<<sumMap[j]<<endl;
}
final=finalSum+finalSum_back;
int *haveOrNo=NULL;
haveOrNo=(int*)clEnqueueMapBuffer(queue,haveStone_buffer,CL_TRUE, CL_MAP_READ, 0, sizeof(int), 0, NULL, NULL, &status);
clEnqueueUnmapMemObject(queue, haveStone_buffer, (void*)haveOrNo, 0, NULL, NULL);
cout<<"img:"<<ii<<" sum:"<<finalSum+finalSum_back<<" haveStone:"<<haveOrNo[0]<<endl;
}
tm.stop();
cout<<"count="<<tm.getCounter()<<" ,process time="<<tm.getTimeMilli()<<" ms."<<endl;
clReleaseCommandQueue(queue);
clReleaseContext(context);
clReleaseProgram(program);
clReleaseKernel(kernel_imgProc);
clReleaseMemObject(srcdata_buffer);
clReleaseMemObject(srcdata_back_buffer);
clReleaseMemObject(rgbArray_buffer);
clReleaseMemObject(sumArray_buffer);
clReleaseMemObject(Bjimg_buffer);
clReleaseMemObject(haveStone_buffer);
delete [] rgbarray;
//free(sumMap);
return 0;
}__kernel void imgProcess(__global uchar *csvArray,__global uchar *currentImg,__global uchar *currentImg_back,int myimgcols,int myimgrows, __global int *tempSum,
int thre_blue,__global uchar *NotBJimg,int thre_dis,__global int *haveObj)
{
__local uchar mydstImg[1936*3];
__local uchar erodeImg[1936*2]; //={0}; //local variable can not be inited like this....
__local int dilateImg[1936]; //={0};
//......//此处省略了一些操作,可以不用看这里,不影响看懂下面的功能
///step5:to front image: detect the stone exist or not...
currentGroupID=get_group_id(1)*get_num_groups(0)+get_group_id(0);
for(;currentGroupID<483;currentGroupID+=get_num_groups(0)*get_num_groups(1))
{
//step1: get the B-channel image \ down sample .
for(uint i=get_local_id(0);i<363;i+=get_local_size(0))
{
mydstImg[i*4]=currentImg[i*4*myimgcols*3+currentGroupID*3*4];
mydstImg[i*4+1]=currentImg[i*4*myimgcols*3+(currentGroupID+1)*3*4];
mydstImg[i*4+2]=currentImg[(i+1)*4*myimgcols*3+currentGroupID*3*4];
mydstImg[i*4+3]=currentImg[(i+1)*4*myimgcols*3+(currentGroupID+1)*3*4];
}
barrier(CLK_LOCAL_MEM_FENCE);
//step2: threshold...
for(uint i=get_local_id(0);i<363*4;i+=get_local_size(0))
{
if(mydstImg[i]>thre_blue)
{
erodeImg[i]=255;
}
else
{
erodeImg[i]=0;
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/* //print to see clearly...
if(get_local_id(0)==0 && currentGroupID==35)
{
int colSum=0;
for(int top=0;top<363;top++)
{
colSum=erodeImg[top*4];
printf("row:%d col-threshold:%d \n",top,colSum);
}
}
barrier(CLK_LOCAL_MEM_FENCE);
*/
//step3: &(NotBJimg). problem here?!!!!!!!!
for(uint i=get_local_id(0);i<363;i+=get_local_size(0))
{
mydstImg[i*4]=((int)erodeImg[i*4]) && ((int)NotBJimg[(currentGroupID+1)*364-1-i]);
mydstImg[i*4+1]=((int)erodeImg[i*4+1]) && ((int)NotBJimg[(currentGroupID+2)*364-1-i]);
mydstImg[i*4+2]=((int)erodeImg[i*4+2]) && ((int)NotBJimg[(currentGroupID+1)*364-2-i]);
mydstImg[i*4+3]=((int)erodeImg[i*4+3]) && ((int)NotBJimg[(currentGroupID+2)*364-2-i]);
}
barrier(CLK_LOCAL_MEM_FENCE);
/*
if(get_local_id(0)==0 && currentGroupID==35)
{
int colSum=0;
for(int top=0;top<363;top++)
{
colSum=mydstImg[top*4];
printf("row:%d col-threshold:%d \n",top,colSum);
}
}
barrier(CLK_LOCAL_MEM_FENCE);
*/
//step4: 2X2 erode...
//2X2 erode according to every col direction...
for(uint j=get_local_id(0);j<364;j+=get_local_size(0))
{
if(j==363)
{
erodeImg[j]=0;
break;
}
__private int erodetempValues[4]={0}; //private array can be inited like this??
for(int t=0;t<4;t++)
{
erodetempValues[t]=(int)mydstImg[j*4+t];
}
if(erodetempValues[0]==1 && erodetempValues[1]==1 && erodetempValues[2]==1 && erodetempValues[3]==1)
{
erodeImg[j]=1;
}
else
{
erodeImg[j]=0;
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/*
if(get_local_id(0)==0 && currentGroupID==35)
{
int colSum=0;
for(int top=0;top<363;top++)
{
colSum=erodeImg[top];
printf("row:%d col-threshold:%d \n",top,colSum);
}
}
barrier(CLK_LOCAL_MEM_FENCE);
*/
//step5: count top-white point and bottom-white point distance every line...
//__local int tempTopFlag=0,tempBottomFlag=0; //local variable can not init!!!!!!!!!!!!!!!!!!!!!!!!!!!1
if(get_local_id(0)==0)
{
for(int top=0;top<364;top++)
{
if((int)erodeImg[top]>0)
{
mydstImg[0]=top;
//printf("col:%d top:%d \n",(int)currentGroupID,top);
//tempTopFlag=1;
mydstImg[3]=1;
break;
}
mydstImg[3]=0;
}
}
if(get_local_id(0)==1)
{
for(int bottom=363;bottom>=0;bottom--)
{
if((int)erodeImg[bottom]>0)
{
mydstImg[1]=bottom;
//printf("col:%d bottom:%d \n",(int)currentGroupID,bottom);
//tempBottomFlag=1;
mydstImg[4]=1;
break;
}
mydstImg[4]=0;
}
}
barrier(CLK_LOCAL_MEM_FENCE);
if(mydstImg[3]==1 && mydstImg[4]==1 && get_local_id(0)==0)
{
dilateImg[0]=mydstImg[1]-mydstImg[0];
//printf("col:%d width:%d...\n",(int)currentGroupID,(int)dilateImg[0]);
if(dilateImg[0]>thre_dis)
{
haveObj[0]=1;
//printf("col:%d width:%d...\n",(int)currentGroupID,(int)dilateImg[0]);
return;
}
}
barrier(CLK_LOCAL_MEM_FENCE);
}
//above all is detect stone...
} 注意:
看我main函数中for下面的那两句,
status = clEnqueueWriteBuffer(queue, haveStone_buffer, CL_FALSE, 0, sizeof(int), haveStone, 0, NULL, NULL);
status = clSetKernelArg(kernel_imgProc, 9, sizeof(cl_mem), (void*)&haveStone_buffer);我记得以前N卡是可以放在外面的!!!但是A卡竟然不可以,否则结果就是错的!!!!!!!仔细想想?!!!!
今天用来测试很多图片,竟然发现有1张图片的第67列结果很奇怪,我打印出来:
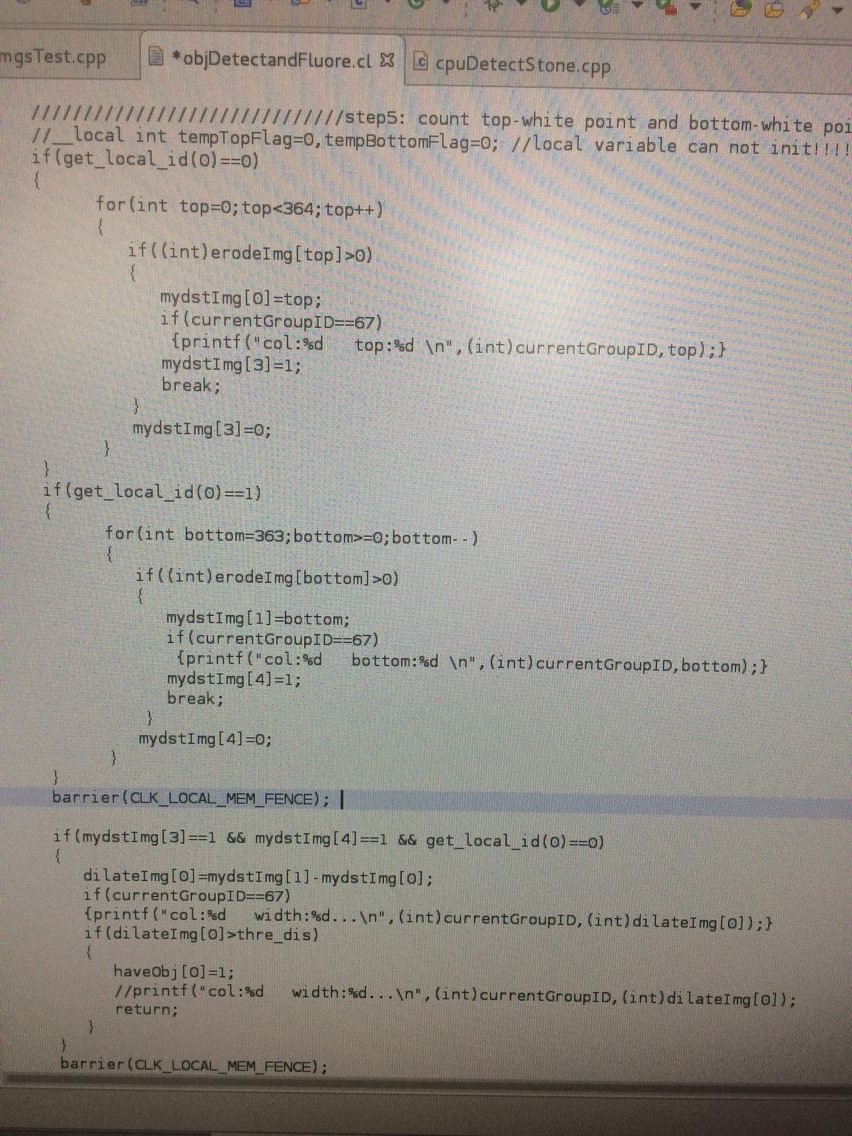
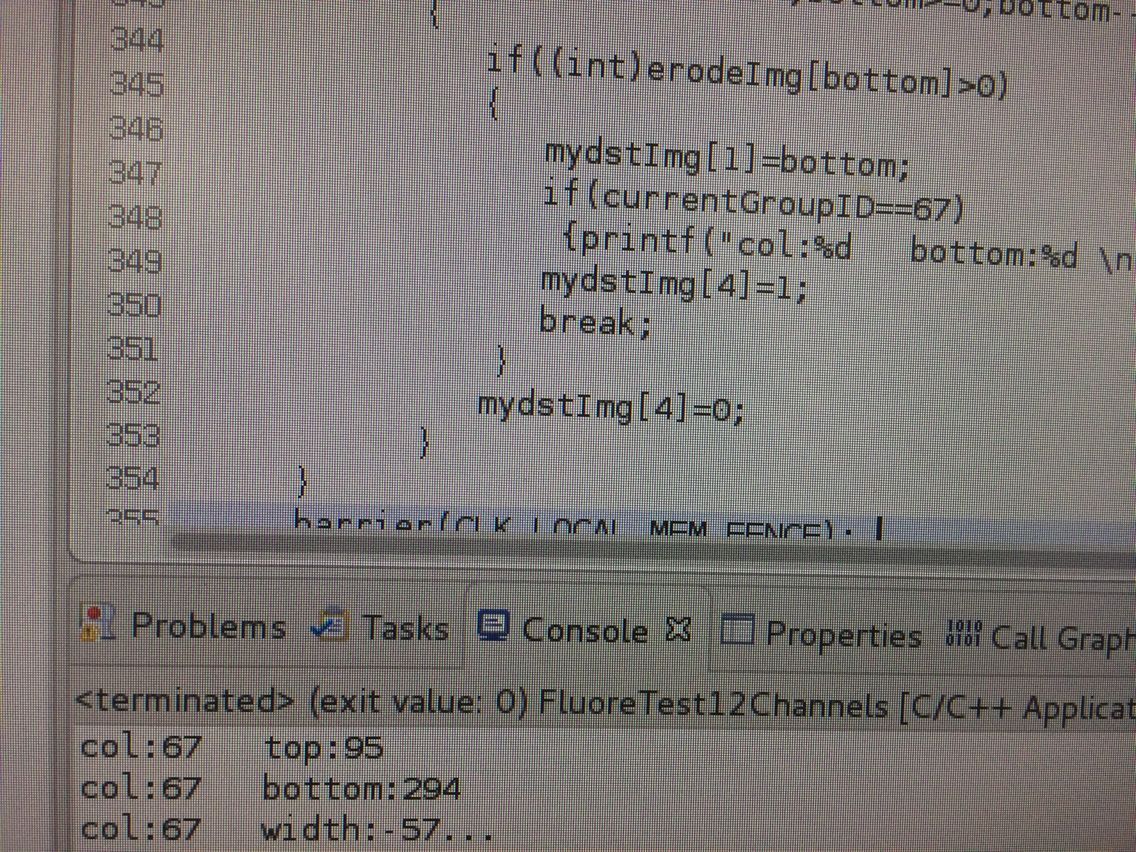
明明294-95不等于-57!!!!!!!!竟然这里面算出来是-57?!!!!!!!!!
知道原因了,因为294>255 都是uchar,所以数据溢出了,这里修改一下就好了。单线程下多次测试正确!!!
二、多线程下正确版本:
将单线程下正确版本改成多线程下,http://download.csdn.net/download/wd1603926823/9980202 ,(因为图片大就只拷贝了1张图)竟然在初始化几个线程那里就退出了!显示段错误!!!!!我知道原因了,因为单例里,那个公告资源BJimg_buffer里传的是一个局部变量Bjimg的data的地址,当后面各个线程要用时,这个局部变量其实已经释放了,所以用不到,所以段错误!将那个Bjimg也改成单例的私有变量就跑通了!
ps:其实我在写按1/4下采样时没有访存合并,而且线程是跳着访问的,这与OpenCL建议的编程方式违背了,降低了性能。我想想怎么改进,最好不违背。
天气又热起来了 郁闷
好开心 ,群里送我这本书:

三、Linux下使用CodeXL
这方面资料好少,都是给出的在VS下使用的教程。我直接安装CodeXL时那个茶壶例子已经成功了。也看了Codexl的那个pdf文档,今天自己瞎搞在Profiler那里选择GPU:Performance Counters:
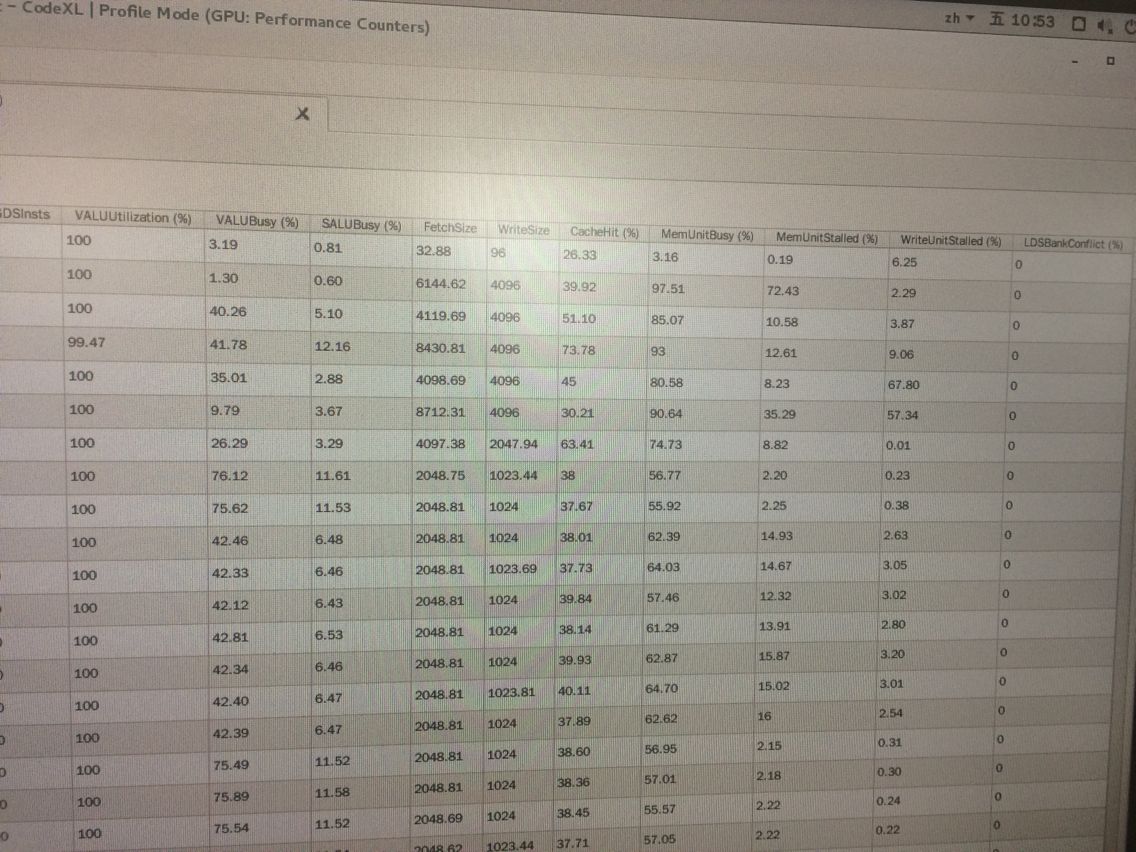
GPU就是这些指标?太多了 有的意思还不怎么明白。
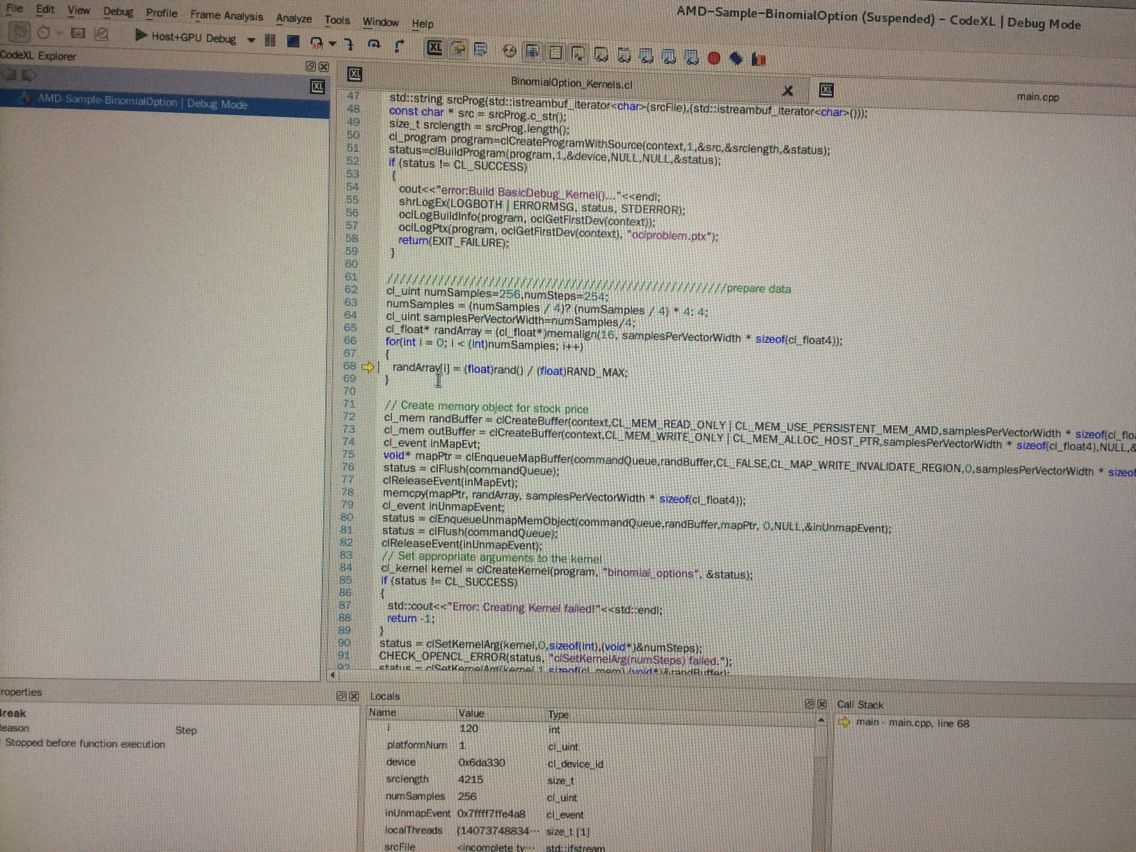
在linux下怎么使用CodeXL调试自己写的OpenCL工程?茶壶例子已经测试过,也看了CodeXL-Quick-Start-Guide.pdf,但我看了茶壶例子以及矩阵相乘的例子都是.cxl文件,所以能直接被load。 那么如果将我们写的工程(tar.gz 【cpp和cl文件】) 转成.cxl文件 在CodeXL里load下来调试呢 ?真是苦恼。竟然还没看到有谁在linux下使用CodeXL调试自己的工程的,难道都是在VS下,我就不信邪了。
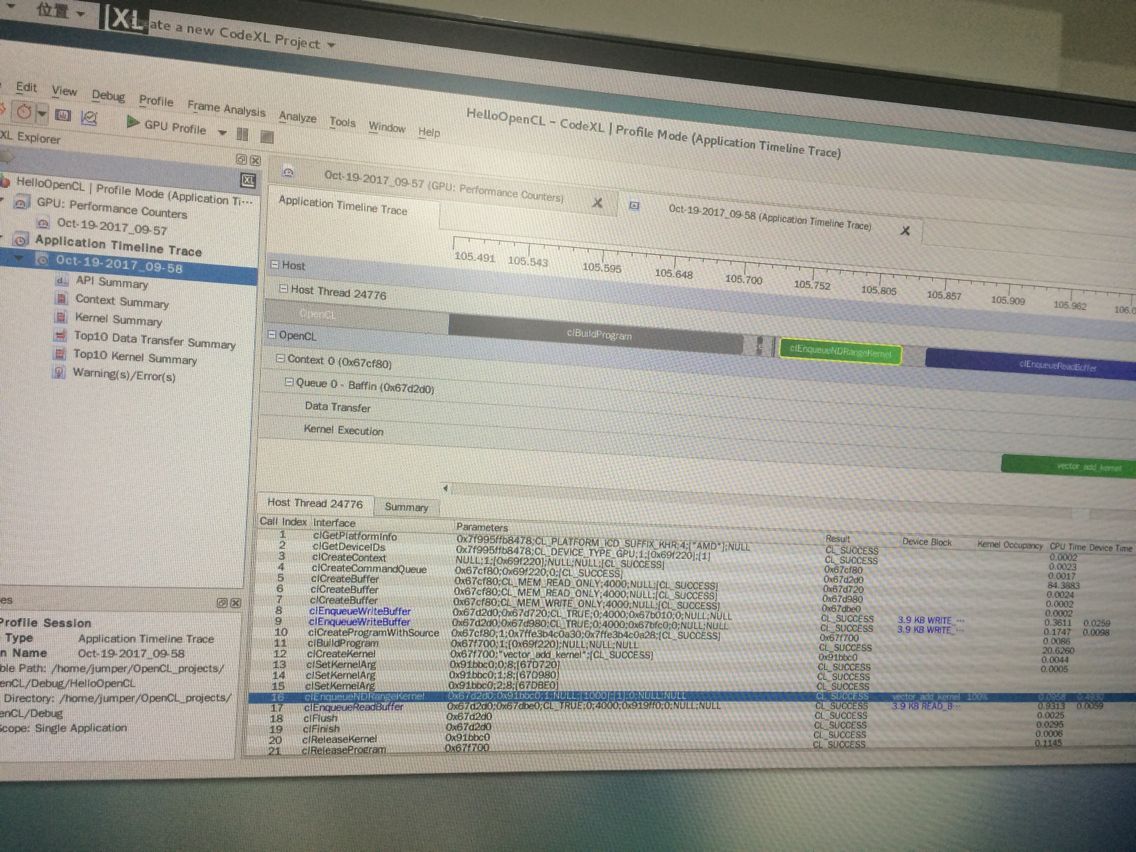
刚刚在CodeXL下发现:
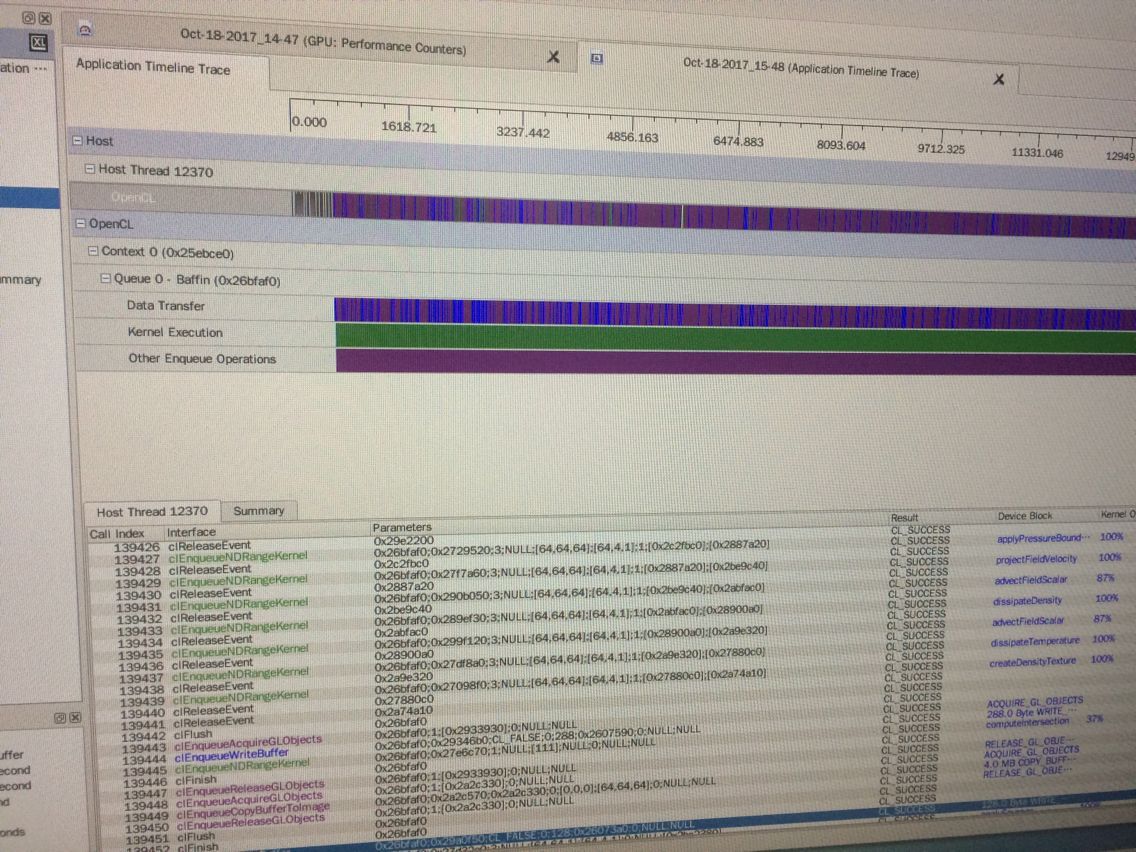
还有这种曲线图也搞出来了哈哈 无意中会的:
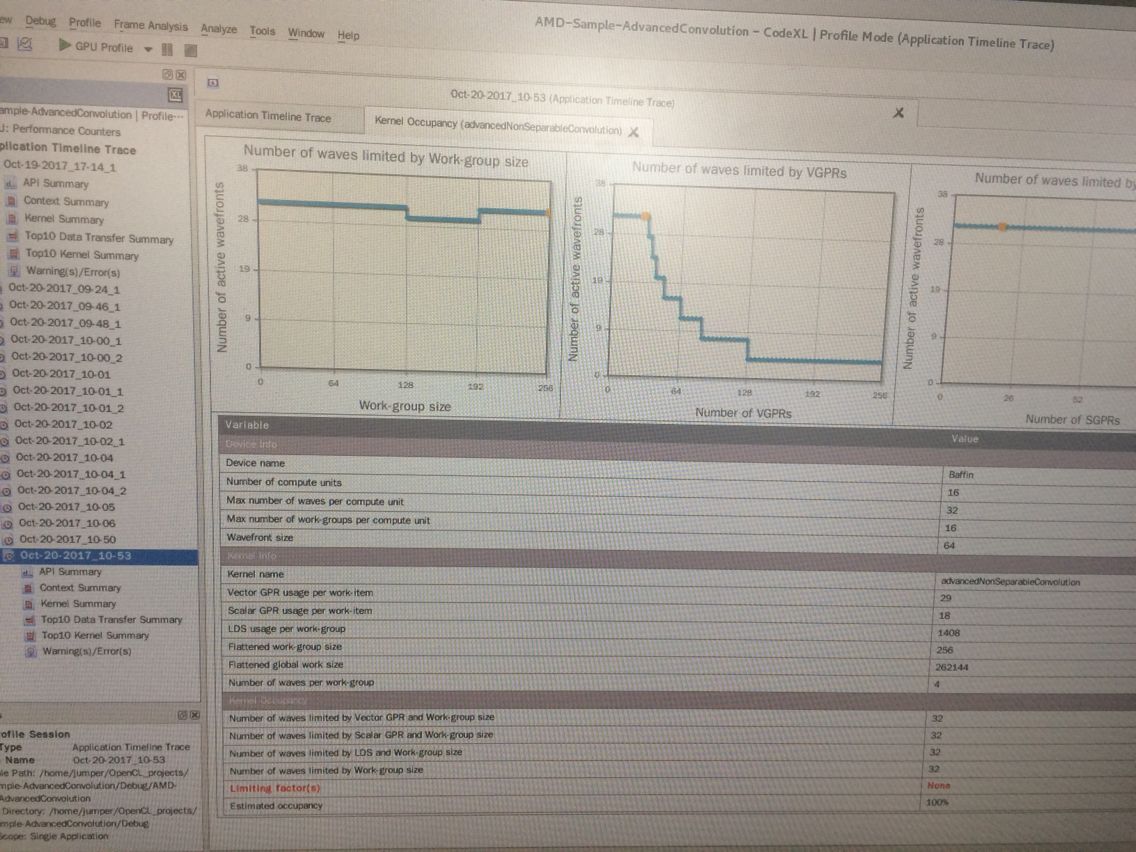
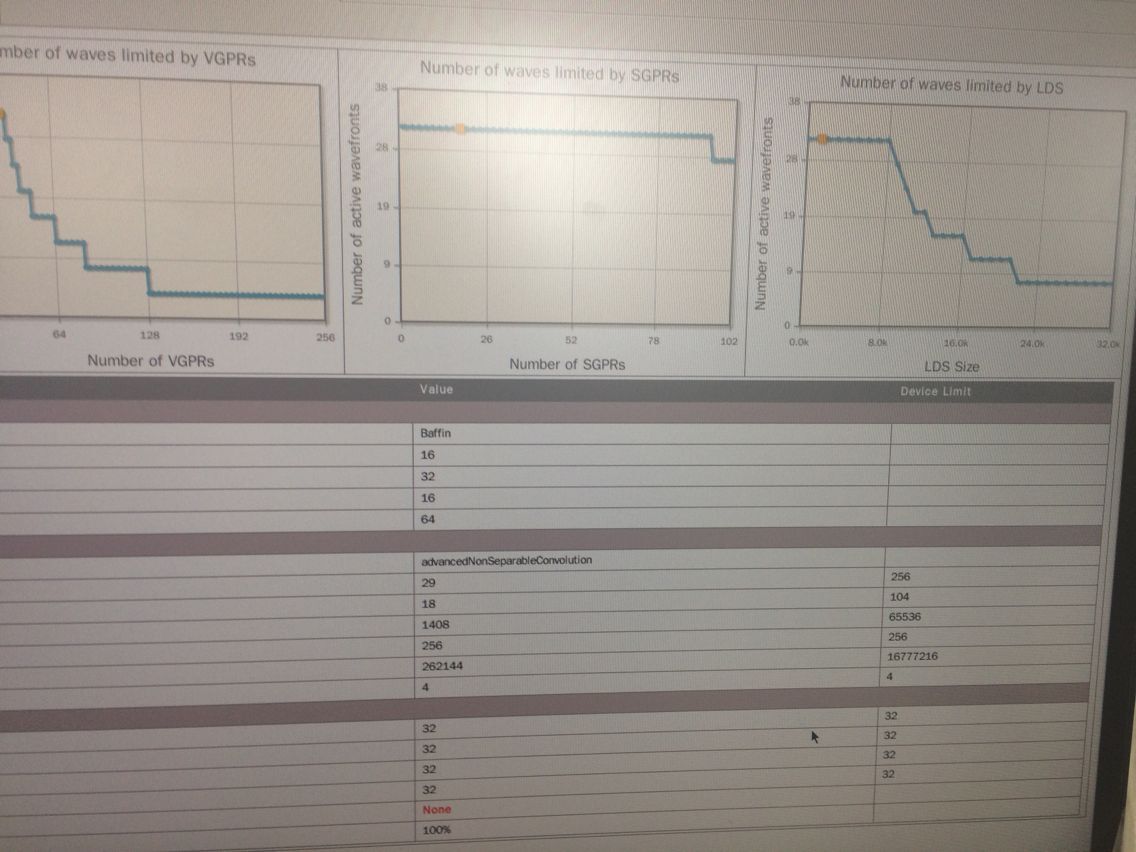
这个是点击kernel的这个地方变成一个手掌形状就会出现上面的图:
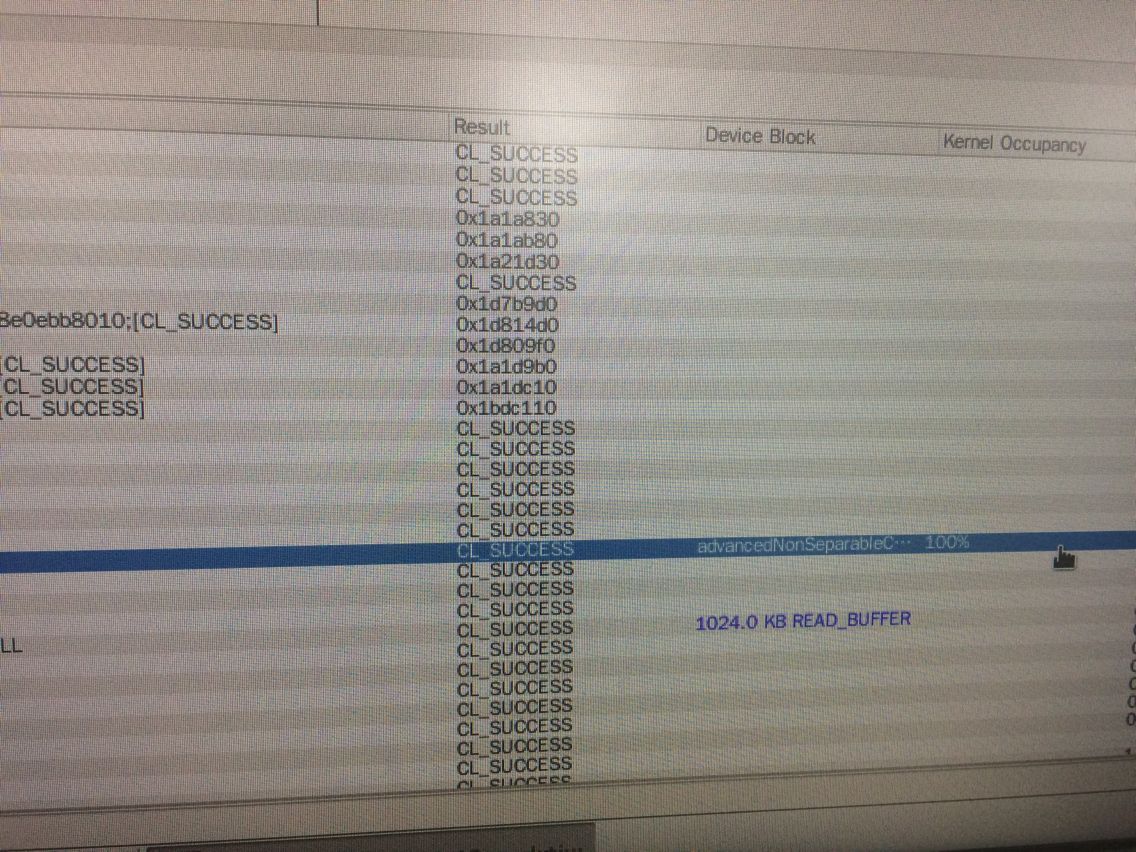
另外我去github下最近的有关CodeXL的话题下 都去问了:But I have a question these days : the Teapot sample is provided by CodeXL not myself (It exists in CodeXL as a 'CodeXL Teapot.cxl' file ,so we can load it directly in CodeXL. ) , how can i use CodeXL to test the performance of my own OpenCL projects (.cpp file and .cl file) written in the eclipse ( no .cxl file )? The file 'CodeXL_Quick_Start_Guide.pdf' does not describe any about this. Any help will be much appriciate !
有个人说:最新的 CodeXL可以用rcprof 进行命令行的调试:
Anyway, @chesik-amd suggested to use command-line profiling:
但我的上面那个问题还是还没解决。。。Are you able to run the command line profiler on the server? In recent CodeXL versions, the command line profiler executable is named "rcprof".
To collect an application trace, use "rcprof --apitrace AppToProfile".
To collect performance counters, use "rcprof --perfcounter AppToProfile"
今天终于有外国友人回复我了,:
Please check out the Project Settings documentation within the CodeXL User Guide (Using CodeXL -> General GUI Controls -> Project Settings). You can open the CodeXL User Guide within the CodeXL tool by pressing F1.
Basically, you need to create a CodeXL project and set it up to point to your application executable binary.
哈哈然后那个help下的网站我打不开就没打开,我试着set it up to point to your application executable binary. 然后就成功了哈哈哈!果然高手还是在外国!在国内的各个平台下都没有人讲过如何在Linux下debug自己写的OpenCL工程!
下面讲解详细步骤:
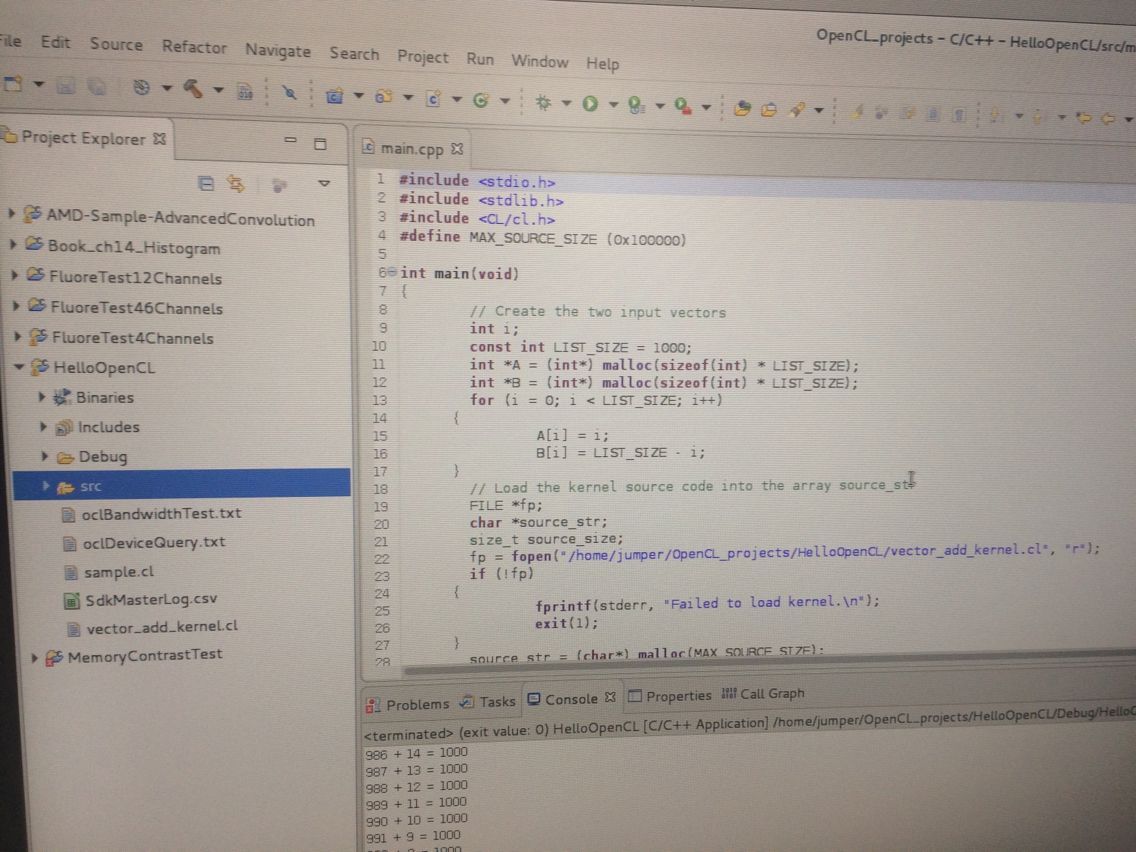
1、看看我在eclipse下写好的OpenCL工程:HelloOpenCL
2、打开CodeXL
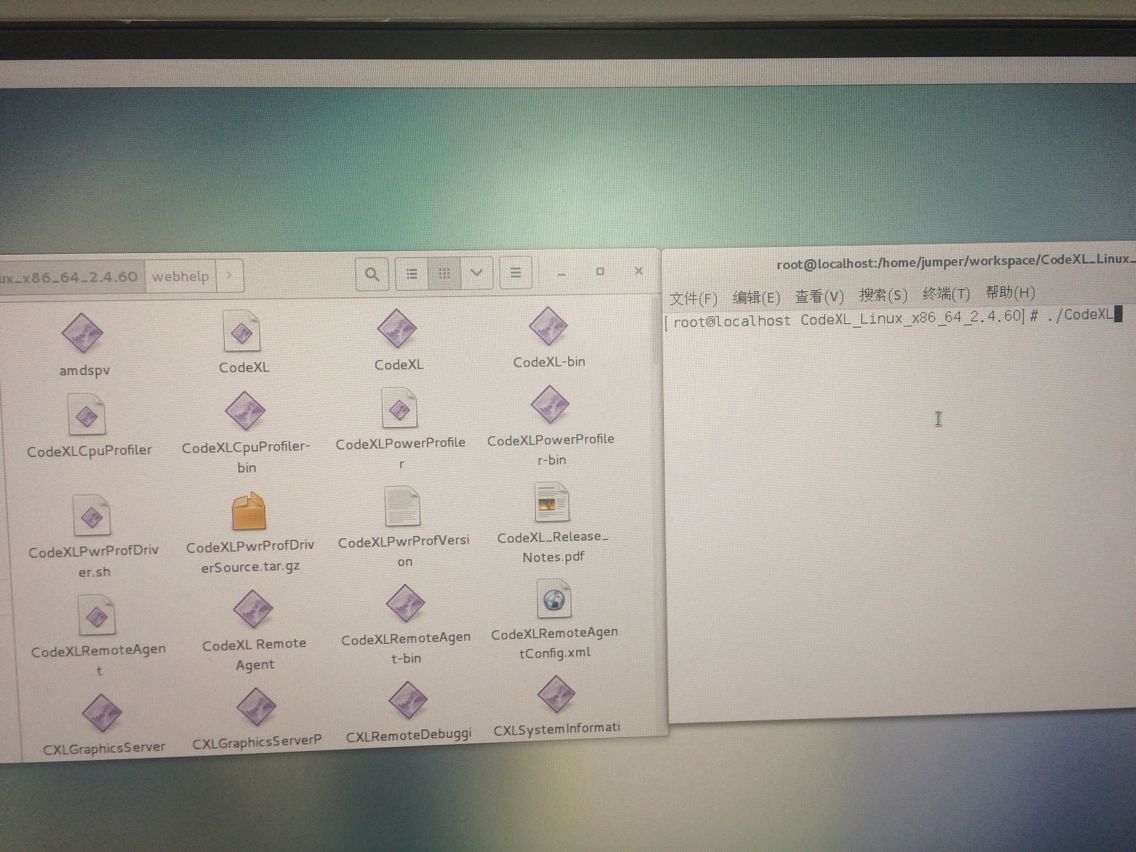
3、在CodeXL下 点击'File'--'Project Settings'---'Executable Path的那个文件夹图标'---'进入我刚刚自己写的工程的目录下打开编译好的工程'
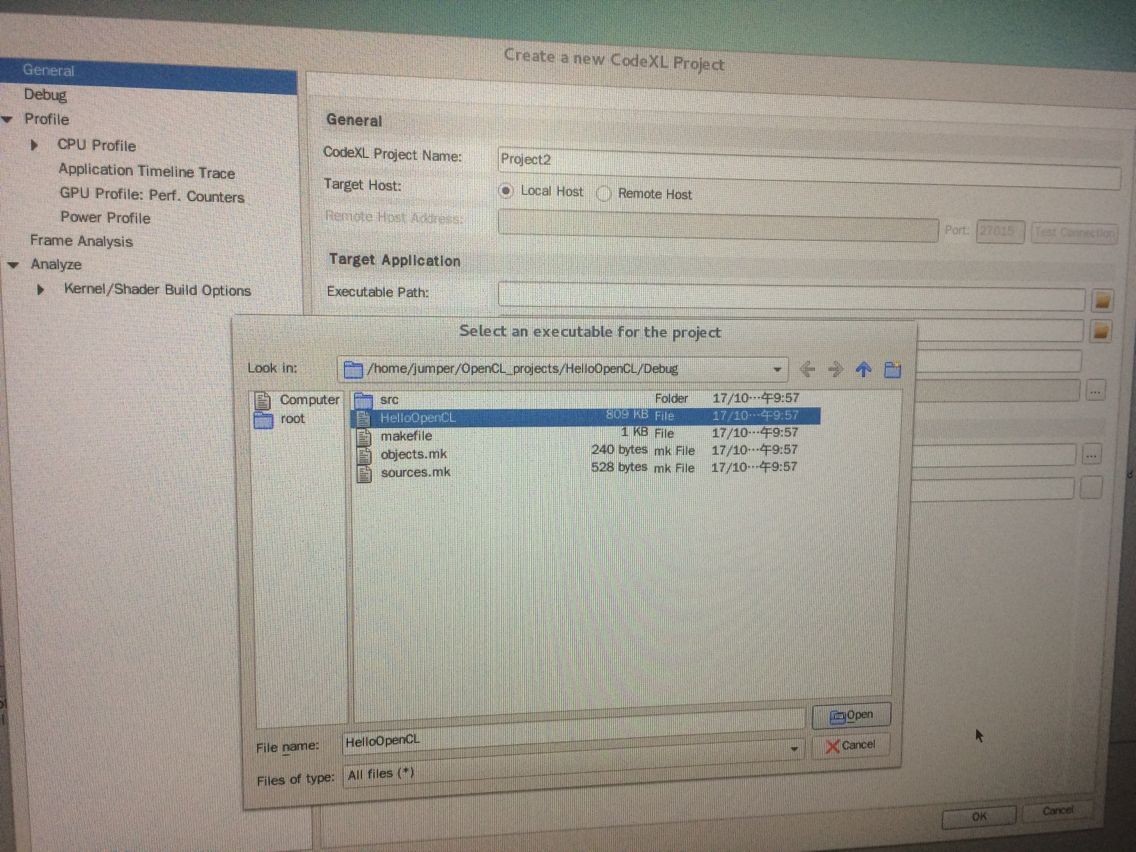
4、可以看到现在load进的工程还是“Not running”状态,选择Profile自己想要的模式然后点击绿色三角图标即可让其开始debug等:
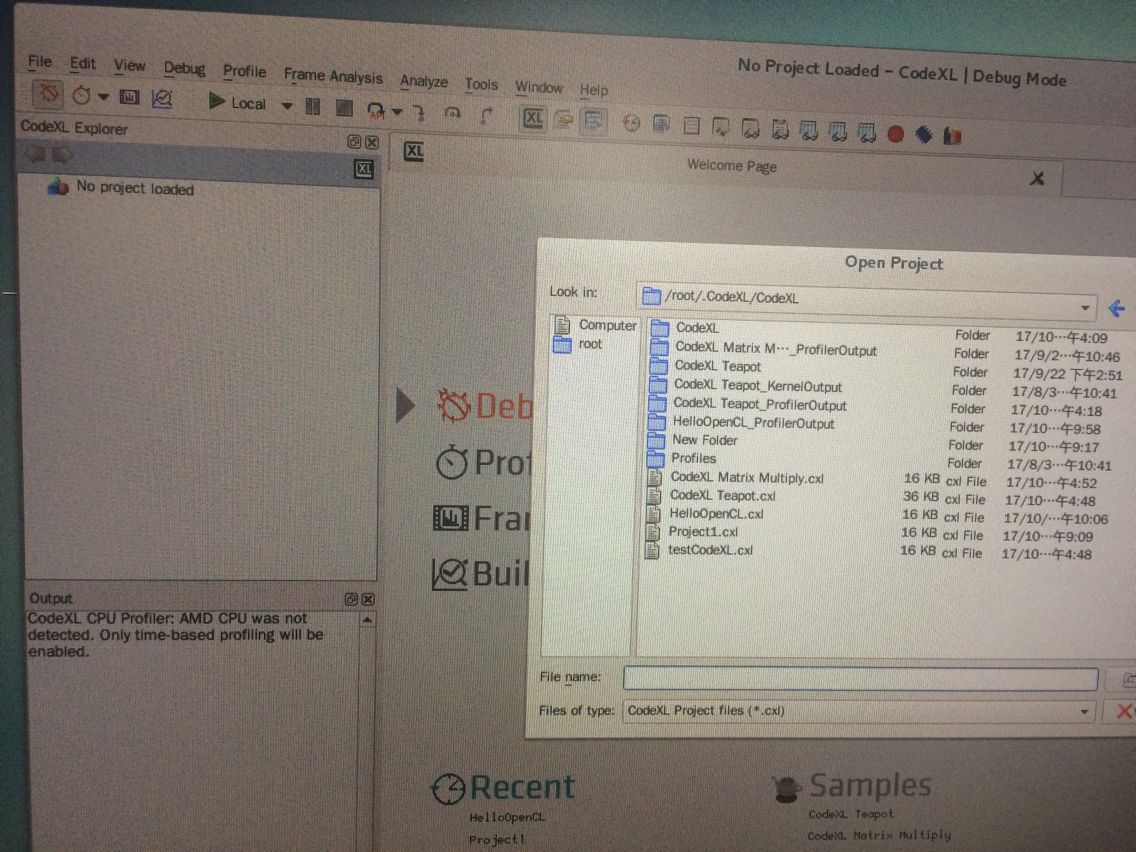
这样就完成了在Linux下将自己写的别的IDE下的工程load进CodeXL!!!!!!!!!!
5、只有被load进CodeXL的工程,下一次开启CodeXL时就不必这样了,而是直接Open Project即可找到HelloOpenCL.cxl 即当第一次load成功后,在CodeXL中已经转化成了.cxl文件,直接Open即可,不必再setting!
完成!!!!!!!!!!!!!!!!!!!!
可以看看 https://www.dcl.hpi.uni-potsdam.de/teaching/profSem/codexl.pdf 这个文档 很不错!
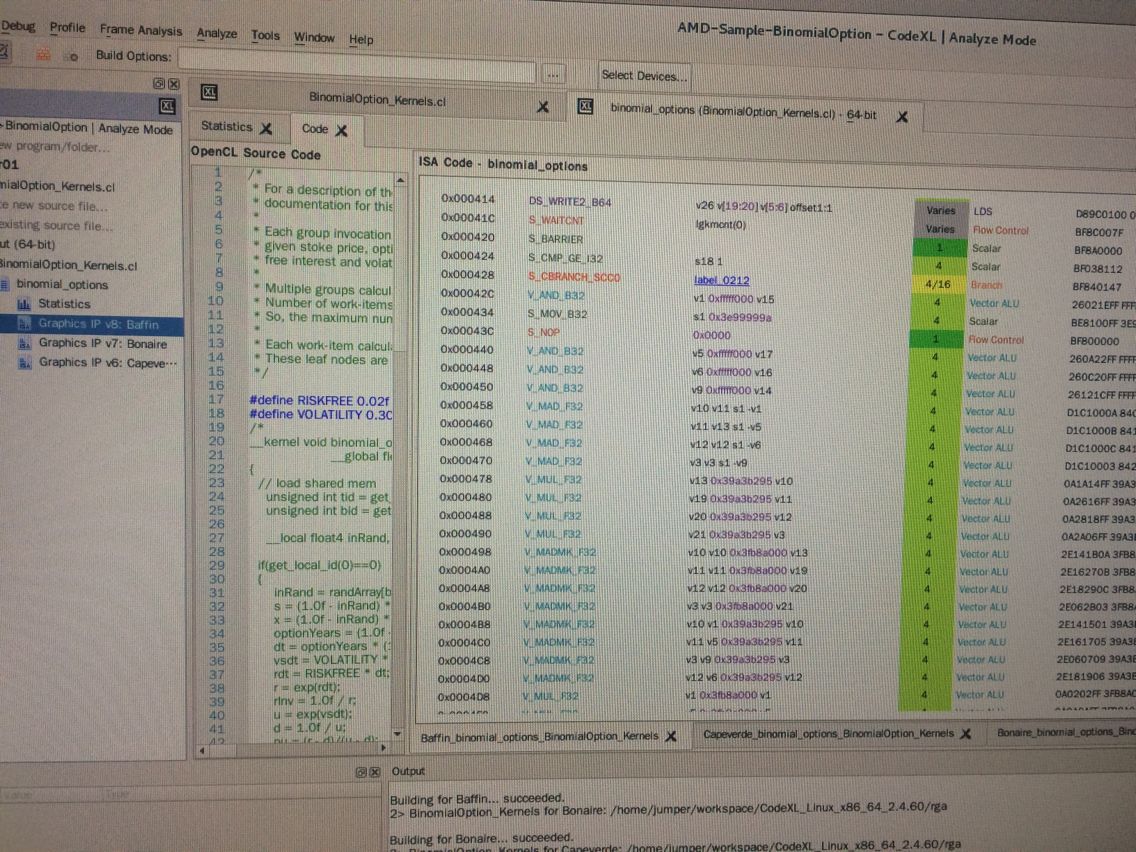
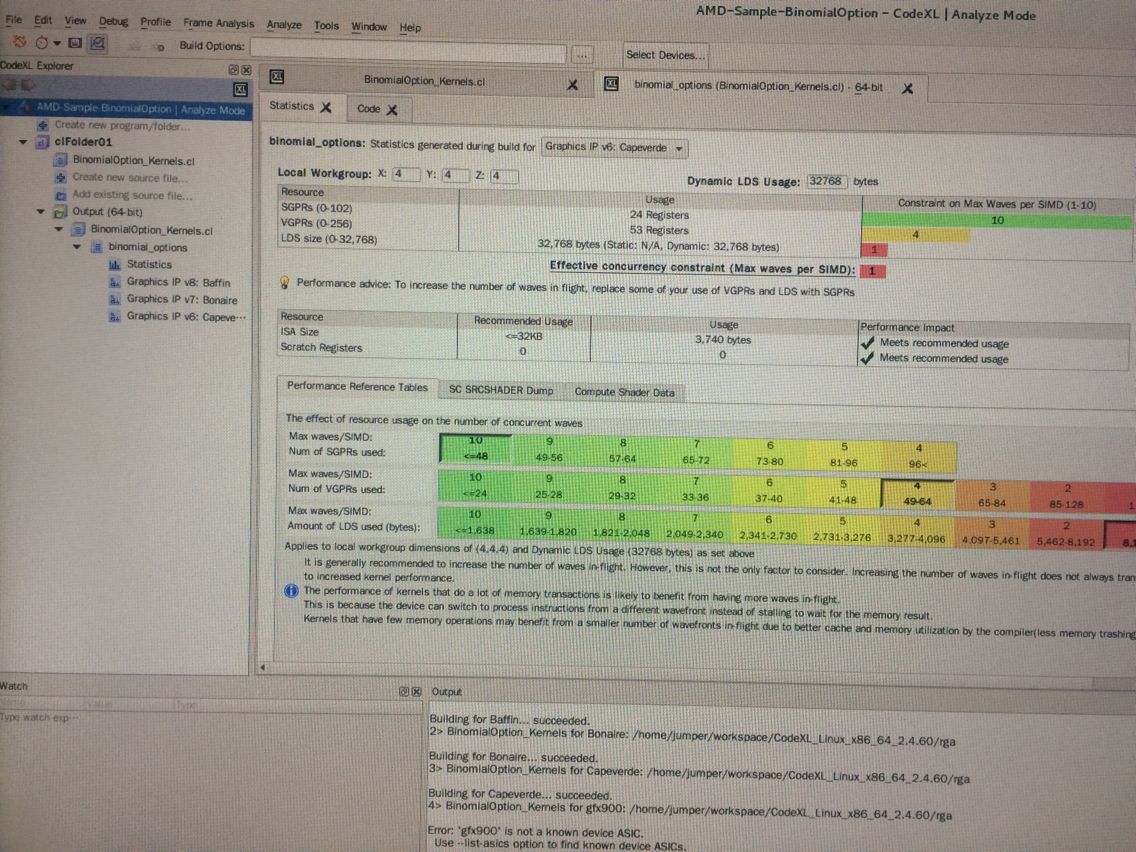
这里还给出了advice。。。
https://www.slideshare.net/DevCentralAMD/pt4053-uri-shomroni
 开心!
开心!















 2865
2865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











