







Hadoop的HDFS和MapReduce子框架主要是针对大数据文件来设计的,在小文件的处理上不但效率低下,而且十分消耗内存资源(每一个小文件占用一个Block,每一个block的元数据都存储在namenode的内存里)。解决办法通常是选择一个容器,将这些小文件组织起来统一存储。HDFS提供了两种类型的容器,分别是SequenceFile和MapFile。
一、SequenceFile
SequenceFile的存储类似于Log文件,所不同的是Log File的每条记录的是纯文本数据,而SequenceFile的每条记录是可序列化的字符数组。
SequenceFile可通过如下API来完成新记录的添加操作:
fileWriter.append(key,value)
可以看到,每条记录以键值对的方式进行组织,但前提是Key和Value需具备序列化和反序列化的功能
Hadoop预定义了一些Key Class和Value Class,他们直接或间接实现了Writable接口,满足了该功能,包括:
Text 等同于Java中的StringIntWritable 等同于Java中的IntBooleanWritable 等同于Java中的Boolean . .
在存储结构上,SequenceFile主要由一个Header后跟多条Record组成,如图所示:
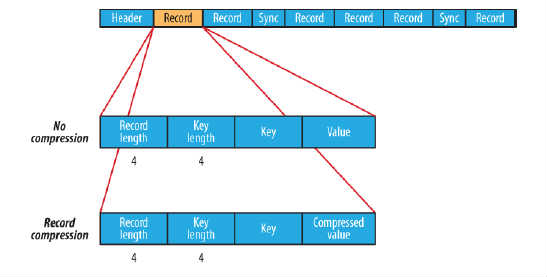
Header主要包含了Key classname,Value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。
每条Record以键值对的方式进行存储,用来表示它的字符数组可依次解析成:记录的长度、Key的长度、Key值和Value值,并且Value值的结构取决于该记录是否被压缩。
数据压缩有利于节省磁盘空间和加快网络传输,SeqeunceFile支持两种格式的数据压缩,分别是:record compression和block compression。
record compression如上图所示,是对每条记录的value进行压缩
sync:同步点。同步点是指当数据读取的实例出错后能够再一次与记录边界同步的数据流中的一个位置。同步点是由SequenceFile.Writer记录的,后者在顺序文件写入过程中插入一个特殊项以便几个记录便有一个同步标识(默认情况下,两个同步点之间的距离大于或者等于100*SYNC_SIZE,即2000字节),同步点只能位于一条Record的前面。
block compression是将一连串的record组织到一起,统一压缩成一个block,如图所示:
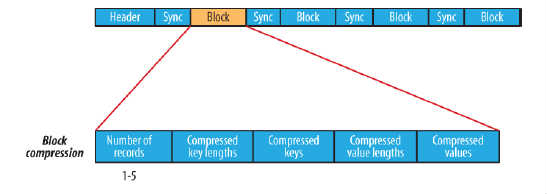
block信息主要存储了:块所包含的记录数、每条记录Key长度的集合、每条记录Key值的集合、每条记录Value长度的集合和每条记录Value值的集合
注:每个block的大小是可通过io.seqfile.compress.blocksize属性来指定的
在块压缩的SequenceFile中,每一个Block之前都有一个同步点。
读取SequenceFile:
如果使用的是Writable类型,那么通过键和值作为参数的next()方法可以将数据流中的下一条键值对读入变量中:
public synchronized boolean next(Writable key, Writable val)
对于其他的,非Writable类型的序列化框架(比如 Apache Thrift),则需要使用下述方法:
public Object next(Object key) throws EOExcetion
public Object getCurrentValue(Object val) throws Exception。
在上述情况下,需要确保在 io.servializations属性中已经设置了你想使用的序列化框架。
在顺序文件中搜索给定位置有两种方法,
第一种是调用 seek方法,由此可以读取文件中的给定位置 :
reader.seek(position)
但是如果给定的位置不是记录的边界,则在调用next()方法时发生错误,IOExcetion。
第二种是通过同步点找到记录边界。SequenceFile.Reader 对象的sync(long position)方法可以将读取位置定位到position之后的下一个同步点。
reader.sync(position)
示例:SequenceFile读/写 操作
- Configuration conf=new Configuration();
- FileSystem fs=FileSystem.get(conf);
- Path seqFile=new Path("seqFile.seq");
- //Reader内部类用于文件的读取操作
- SequenceFile.Reader reader=new SequenceFile.Reader(fs,seqFile,conf);
- //Writer内部类用于文件的写操作,假设Key和Value都为Text类型
- SequenceFile.Writer writer=new SequenceFile.Writer(fs,conf,seqFile,Text.class,Text.class);
- //通过writer向文档中写入记录
- writer.append(new Text("key"),new Text("value"));
- IOUtils.closeStream(writer);//关闭write流
- //通过reader从文档中读取记录
- Text key=new Text();
- Text value=new Text();
- while(reader.next(key,value)){
- System.out.println(key);
- System.out.println(value);
- }
- IOUtils.closeStream(reader);//关闭read流
二、MapFile
MapFile是排序后的SequenceFile,通过观察其目录结构可以看到MapFile由两部分组成,分别是data和index。
index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。
需注意的是,MapFile并不会把所有Record都记录到index中去,默认情况下每隔128条记录存储一个索引映射。当然,记录间隔可人为修改,通过MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval属性;
另外,与SequenceFile不同的是,MapFile的KeyClass一定要实现WritableComparable接口,即Key值是可比较的。
读取MapFile:
在MapFile依次遍历文件中所有条目的过程类似于SequenceFile中的过程:首先新建 MapFile.Reader实例,然后调用 next()方法,直到返回值为false,表示已经没有条目返回。其实底层调用的是SequenceFile.Reader中的方法。
public synchronized Writable get(WritableComparable key, Writable val)
根据key值查找,如果找到相应的key,则返回value;否则返回null值。
MapFile.Reader首先将Index文件读入内存(由于索引是缓存的,所以后续的随机访问将使用内存中的同一索引)。接着对内存中的索引进行二分查找,最后找到小于或等于搜索索引的键。至此,才找到键所对应的值,最后从data文件中读取相应的值。整体而言,一次查找需要一次磁盘寻址和一次最多有128个条目的扫描。index文件里面的key为Text类型,即文件名,value为LongWritable类型,即data文件中所对应的key,value的偏移量。
getClost方法:
public synchronized WritableComparable getClosest(WritableComparable key, Writable val, final boolean before)
getClost方法和get方法相似,不同的是前者返回与指定键匹配的最近的值,并不是在不匹配时返回null。更准确地说,如果 MapFile包含指定的键,则返回对应的条目;否则,返回 MapFile中在key之前或者之后的第一个键所对应的值(由before参数决定)。
大型MapFile的索引会占据大量内存。可以不选择在修改索引间隔之后重建索引,而是在读取索引时设置io.mao.index.skip属性来加载一部分索引键。该属性默认为0,表示不路过索引键;如果设置为1,则表示每次跳过索引键中的一个,也就是每隔一个索引读取一次,即只读取索引的二分之一。设置大的跳跃值可以节省大量的内存,但是会增加搜索时间。
示例:MapFile读写操作
- Configuration conf=new Configuration();
- FileSystem fs=FileSystem.get(conf);
- Path mapFile=new Path("mapFile.map");
- //Reader内部类用于文件的读取操作
- MapFile.Reader reader=new MapFile.Reader(fs,mapFile.toString(),conf);
- //Writer内部类用于文件的写操作,假设Key和Value都为Text类型
- MapFile.Writer writer=new MapFile.Writer(conf,fs,mapFile.toString(),Text.class,Text.class);
- //通过writer向文档中写入记录
- writer.append(new Text("key"),new Text("value"));
- IOUtils.closeStream(writer);//关闭write流
- //通过reader从文档中读取记录
- Text key=new Text();
- Text value=new Text();
- while(reader.next(key,value)){
- System.out.println(key);
- System.out.println(key);
- }
- IOUtils.closeStream(reader);//关闭read流
注意:使用MapFile或SequenceFile虽然可以解决HDFS中小文件的存储问题,但也有一定局限性,如:1.文件不支持复写操作,不能向已存在的SequenceFile(MapFile)追加存储记录
2.当write流不关闭的时候,没有办法构造read流。也就是在执行文件写操作的时候,该文件是不可读取的
三、SequenceFile转换成MapFile
public class MapFileFixer {
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
String mapUri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI(mapUri), conf);
Path map = new Path(mapUri);
Path mapData = new Path(mapUri,MapFile.DATA_FILE_NAME);
//从data sequenceFile中读取key,value的类型
SequenceFile.Reader in = new SequenceFile.Reader(fs, mapData, conf);
Class keyClass = in.getKeyClass();
Class valueClass = in.getValueClass();
in.close();
long entries = MapFile.fix(fs, map, keyClass, valueClass, false, conf);
System.out.println("created MapFile " + map + " with entries "+entries);
}
}mapUri为MapFile文件的输出目录,转换完成后mapUri目录下应该有data和index两个文件。
观察MapFile.fix的源码可以发现,里面的indexInterval值为固定的128,即通过fix()方法生成的索引是data文件中每隔128条纪录生成一条索引。
@@补充:好用的SequenceFile转换为MapFile的代码:
// 6、SequenceFile转为MapFile
public static void doTransfer() throws Exception {
// 从SequenceFile中读取key、value写入到MapFile
Configuration conf = new Configuration();
// FileSystem fs = FileSystem.get(URI.create("hdfs://master:9000"), conf); //注意:使用这种方式时,后面的fix方法老提示“File /input/hello3/data does not exist”
conf.set("fs.defaultFS", "hdfs://master:9000");
FileSystem fs = FileSystem.get(conf);
//事先创建/input/hello3文件夹,并且把SequenceFile文件拷贝进来,
//并且重命名为data: hdfs dfs -mv /input/hello3/hello.txt /input/hello3/data
Path map = new Path("/input/hello3");
// MapFile.DATA_FILE_NAME 为seq文件移动到tmp1.map文件夹下面的文件名称
Path mapData = new Path(map,MapFile.DATA_FILE_NAME); //文件名必须是data
// 从data sequenceFile中读取key,value的类型
SequenceFile.Reader in = new SequenceFile.Reader(fs, mapData, conf);
Class keyClass = in.getKeyClass();
Class valueClass = in.getValueClass();
in.close();
long entries = MapFile.fix(fs, map, keyClass, valueClass, false, conf);
// System.out.println("created MapFile " + map + " with entries "+ entries);
System.out.printf("Created MapFile %s with %d entries\n",map,entries);
}















 133
133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









