









相关文章:
- 李航《统计学习方法》第二章——用Python实现感知器模型(MNIST数据集)
- 李航《统计学习方法》第三章——用Python实现KNN算法(MNIST数据集)
- 李航《统计学习方法》第四章——用Python实现朴素贝叶斯分类器(MNIST数据集)
- 李航《统计学习方法》第五章——用Python实现决策树(MNIST数据集)
- 李航《统计学习方法》第六章——用Python实现逻辑斯谛回归(MNIST数据集)
- 李航《统计学习方法》第七章——用Python实现支持向量机模型(伪造数据集)
- 李航《统计学习方法》第八章——用Python+Cpp实现AdaBoost算法(MNIST数据集)
- 李航《统计学习方法》第十章——用Python实现隐马尔科夫模型
最大熵模型的数学推理看起来好舒服啊,但第一次看的时候感觉都看懂了,却不知道代码改怎么写。
第二遍顺着书中的思路自己推了一遍,感觉又是似懂非懂,尝试写代码,用编的数据进行测试发现正确率还比不上掷骰子。
参考了其他人的代码后发现我对于 f(x,y) 的理解有误,我之前认为每个(x,y)对都有一个对应的 f(x,y) 。
但其实 f(x,y) 是一个按需添加的参数,比如对于MNIST数据集,我们可以认为只要出现在训练集中的 (x,y) 其 f(x,y)=1
照我的理解 f(x,y) 是一个人为给的先验知识,比如说一个二分类问题,y={0,1} , x是个三维向量,训练集中所有 x3 都为0,但我们知道当 x3=1 时,y必然等于1,那么我们就可以加一个先验的f(x,y)
f(x,y)={10x=1,y=1else
知乎上有一个问题是问朴素贝叶斯是不是知识完备的最大熵模型,我是认同的。
最大熵模型
这里先贴上书上的算法
算法


我们的
f(x,y)
如下所示,根据其定义可知
f#(x,y)
必然为常数,因此采用公式6.34更新迭代即可
f(x,y)={10(x,y)∈ train setelse
还要注意一下,公式6.34中的M值可以理解成学习速率,最好直接设置成一个比较小的值,防止指数爆炸。
数据集
数据集和朴素贝叶斯那个博文用的是同样的数据集。
数据地址:https://github.com/WenDesi/lihang_book_algorithm/blob/master/data/train.csv
特征
将这个图作为特征,但需要先经过二值化处理
还有一点,与其他分类器不同的是,最大熵模型中的
f(x,y)
中的x是单独的一个特征,不是一个n维特征向量,而经过二值化处理过的特征都是0与1,因此我们需要对每个维度特征加一个区分标签
如
X=(x0,x1,x2,...)
变为
X=(0_x0,1_x1,2_x2,...)
代码
代码已放到Github上,这边也贴出来
# encoding=utf-8
# @Author: WenDesi
# @Date: 05-11-16
# @Email: wendesi@foxmail.com
# @Last modified by: WenDesi
# @Last modified time: 09-11-16
import pandas as pd
import numpy as np
import time
import math
import random
from collections import defaultdict
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
class MaxEnt(object):
def init_params(self, X, Y):
self.X_ = X
self.Y_ = set()
self.cal_Pxy_Px(X, Y)
self.N = len(X) # 训练集大小
self.n = len(self.Pxy) # 书中(x,y)对数
self.M = 10000.0 # 书91页那个M,但实际操作中并没有用那个值
# 可认为是学习速率
self.build_dict()
self.cal_EPxy()
def build_dict(self):
self.id2xy = {}
self.xy2id = {}
for i, (x, y) in enumerate(self.Pxy):
self.id2xy[i] = (x, y)
self.xy2id[(x, y)] = i
def cal_Pxy_Px(self, X, Y):
self.Pxy = defaultdict(int)
self.Px = defaultdict(int)
for i in xrange(len(X)):
x_, y = X[i], Y[i]
self.Y_.add(y)
for x in x_:
self.Pxy[(x, y)] += 1
self.Px[x] += 1
def cal_EPxy(self):
'''
计算书中82页最下面那个期望
'''
self.EPxy = defaultdict(float)
for id in xrange(self.n):
(x, y) = self.id2xy[id]
self.EPxy[id] = float(self.Pxy[(x, y)]) / float(self.N)
def cal_pyx(self, X, y):
result = 0.0
for x in X:
if self.fxy(x, y):
id = self.xy2id[(x, y)]
result += self.w[id]
return (math.exp(result), y)
def cal_probality(self, X):
'''
计算书85页公式6.22
'''
Pyxs = [(self.cal_pyx(X, y)) for y in self.Y_]
Z = sum([prob for prob, y in Pyxs])
return [(prob / Z, y) for prob, y in Pyxs]
def cal_EPx(self):
'''
计算书83页最上面那个期望
'''
self.EPx = [0.0 for i in xrange(self.n)]
for i, X in enumerate(self.X_):
Pyxs = self.cal_probality(X)
for x in X:
for Pyx, y in Pyxs:
if self.fxy(x, y):
id = self.xy2id[(x, y)]
self.EPx[id] += Pyx * (1.0 / self.N)
def fxy(self, x, y):
return (x, y) in self.xy2id
def train(self, X, Y):
self.init_params(X, Y)
self.w = [0.0 for i in range(self.n)]
max_iteration = 1000
for times in xrange(max_iteration):
print 'iterater times %d' % times
sigmas = []
self.cal_EPx()
for i in xrange(self.n):
sigma = 1 / self.M * math.log(self.EPxy[i] / self.EPx[i])
sigmas.append(sigma)
# if len(filter(lambda x: abs(x) >= 0.01, sigmas)) == 0:
# break
self.w = [self.w[i] + sigmas[i] for i in xrange(self.n)]
def predict(self, testset):
results = []
for test in testset:
result = self.cal_probality(test)
results.append(max(result, key=lambda x: x[0])[1])
return results
def rebuild_features(features):
'''
将原feature的(a0,a1,a2,a3,a4,...)
变成 (0_a0,1_a1,2_a2,3_a3,4_a4,...)形式
'''
new_features = []
for feature in features:
new_feature = []
for i, f in enumerate(feature):
new_feature.append(str(i) + '_' + str(f))
new_features.append(new_feature)
return new_features
if __name__ == "__main__":
print 'Start read data'
time_1 = time.time()
raw_data = pd.read_csv('../data/train_binary.csv', header=0)
data = raw_data.values
imgs = data[0::, 1::]
labels = data[::, 0]
# 选取 2/3 数据作为训练集, 1/3 数据作为测试集
train_features, test_features, train_labels, test_labels = train_test_split(
imgs, labels, test_size=0.33, random_state=23323)
train_features = rebuild_features(train_features)
test_features = rebuild_features(test_features)
time_2 = time.time()
print 'read data cost ', time_2 - time_1, ' second', '\n'
print 'Start training'
met = MaxEnt()
met.train(train_features, train_labels)
time_3 = time.time()
print 'training cost ', time_3 - time_2, ' second', '\n'
print 'Start predicting'
test_predict = met.predict(test_features)
time_4 = time.time()
print 'predicting cost ', time_4 - time_3, ' second', '\n'
score = accuracy_score(test_labels, test_predict)
print "The accruacy socre is ", score运行结果
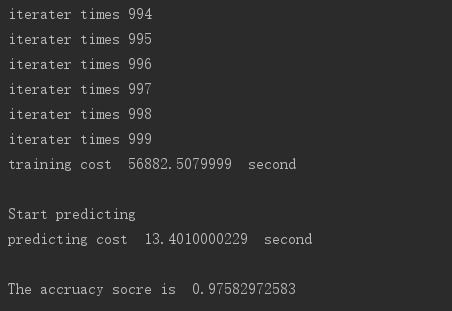
设置迭代1000次,正确率不错,是目前章节中排名第二的算法
但竟然运行了15个小时,看来最大熵模型更适合小数据














 1051
1051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









