






0 前提
1 序言
序列模式(sequential pattern)挖掘最早由Agrawal等人提出,针对带有交易时间属性的交易数据库,获取频繁项目序列以发现某段时间内客户的购买活动规律。每一次交易包含customer-id,transaction-time和items(购置的商品内容)。
定义1 一个序列(sequence)是项集的有序表,序列s记为 ,其中每个
是一个项集(itemset),表示多次交易的组合
。项集 i (itemset)记为
,其中
代表一个项(item),表示一次交易
。一个序列的长度(Length)是它所包含的项集个数,若具有长度k,则记为K-序列。
定义2 序列 包含在(is contained in)序列
中,即存在
使
。例如,<(3) (4, 5) (8)>包含在<(7) (3, 8) (9) (4, 5, 6) (8)>中,因为
。注意:<(3) (5)>不包含于<(3, 5)>,因为前者表示两次交易分别是(3)和(5),后者表示一次交易有(3, 5)。
定义3 最大序列(Maximal Sequence)表示不包含在任何其他序列中。
定义4 序列s的支持度(support)是指所有序列中包含序列s的个数(百分比)。满足最小支持度(minimum support)的序列称为大序列(large sequence)。大序列中的所有最长序列就称为序列模式(sequential pattern)。
定义5 项集i的支持度是指所有序列中包含项集i的个数。因此项集i和1-序列<i>的支持度相同。满足最小支持度的项集称为大项集(large itemset)或者litemset。注意:大序列中的所有项集必须是大项集。因此,大序列就是litemset的列表。
2 算法
2.1 排序阶段(Sort)
对数据库进行排序整理,将原始数据库转换成序列数据库。例如交易数据库就以客户号(Cust_id)和交易时间(Tran_time)来排序。例如table1到table2 。
| 客户号(Cust_id) | 交易时间 (Tran_time) | 物品 (Item) |
| 1 1 | June 25’99 June 30’99 | 30 90 |
| 2 2 2 | June 10’99 June 15’99 June 20’99 | 10,20 30 40,60,70 |
| 3 | June 25’99 | 30,50,70 |
| 4 4 4 | June 25’99 June 30’99 July 25’99 | 30 40,70 90 |
| 5 | June 12’99 | 90 |
Table 1 带交易时间的交易数据源实例
| 客户号(Cust_id) | 顾客序列(Customer Sequence) |
| 1 | <(30)(90)> |
| 2 | <(10,20)(30)(40,60,70)> |
| 3 | <(30,50,70)> |
| 4 | <(30)(40,70)((90) > |
| 5 | <(90)> |
Table 2 客户序列表实例
2.2 大项集阶段(Litemset)
找出所有的频繁的项集(Litemset)。同时得到large 1-sequence的组合。在上面Table2给出的顾客序列数据库中,假设支持数为2,则大项集分别是(30),(40),(70),(40,70)和(90)。实际操作中,经常将大项集被映射成连续的整数。例如,上面得到的大项集映射成Table3对应的整数。当然,这样的映射纯粹是为了处理的方便和高效。
| Large Itemsets | Mapped To |
| (30) (40) (70) (40,70) (90) | 1 2 3 4 5 |
Table 3 Litemset的映射表
2.3 转换阶段(Transformation)
在4阶段中寻找序列模式时,我们需要检查给定的大序列(由litemsets组成的large sequence)是否包含在客户序列中,为了加速这一过程,就需要对复杂客户数据进行转化。即,将Table2 数据表使用Table3映射表进行转化,结果如Table4所示。
使用“大项集”阶段得到Litemsets(Table3)来替换交易数据中的每一件事务。规则1:如果该事务中不包含任何litemsets,则删除事务;原则2:如果一个顾客序列中不包含任何litemsets,则删除序列。例如ID-2中的事务(10 20)不包含任何litemsets,所以删除;而(40 60 70)被litemsets中的{(40) (70) (40 70)}替换。
| Cust_id | Customer Sequence | Transformed Customer Sequence | After mapping |
| 1 | <(30) (90)> | < {(30)} {(90)}> | <{1} {5}> |
| 2 | <(10 20) (30) (40 60 70)> | <{(30)} {(40), (70),(40 70)}> | <{1} {2 3 4}> |
| 3 | <(30 50 70)> | <{(30), (70)}> | <{1 3}> |
| 4 | <(30) (40 70) (90) > | <{(30)} {(40), (70), (40 70)} {(90)} > | <{1} {2 3 4} {5}> |
| 5 | <(90)> | <{(90)}> | <{5}> |
Table 4 转化和映射后的数据表
2.4 序列阶段(Sequence)
发现large sequence,设计算法AprioriAll和AprioriSome,在下一章讲解。
2.5 最大序列阶段(Maximal)
在large sequences中发现maximal sequences(序列模式),此步骤可能包含在上步骤的算法中。
3 序列阶段(Sequence Phase)
一般的寻找序列算法中,都需要多次扫描数据库。每次扫描时,使用种子集(seed set)来生产候选序列(candidate sequence),同时计算每个序列的支持度,以此判断哪些candidate sequences是large sequences。这些large sequences作为下次扫描的seed set。有两类相似算法来支持上述行为:count-all和count-some。
Count-all算法遍历所有的largesequences,包括非最大序列(non-maximal sequences)。AprioriAll算计是基于Apriori算法查找大项集,扩展到序列挖掘。
- 在每一遍扫描中都利用前一遍的大序列来产生候选序列,然后在完成遍历整个数据库后测试它们的支持度。
- 在第一遍扫描中,利用大项目集阶段的输出来初始化大1-序列的集合。
- 在每次遍历中,从一个由大序列组成的种子集开始,利用这个种子集,可以产生新的潜在的大序列。
- 在第一次遍历前,所有在大项集阶段得到的大1-序列组成了种子集。
Count-Some算法包括AprioriSome和DynamicSome。算法思想:因为我们只对maximalsequences感兴趣,如果我们先遍历longer sequences,则可以避免longer sequences的包含序列。Longer sequences是没经过支持度检查的候选集序列。
3.1 AprioriAll算法
输入:大项集阶段转换后的序列数据库DT
输出:所有最长序列
(1)L1={large 1-sequences};// 大项集阶段得到的结果
(2)FOR(k=2;Lk-1 ¹ Æ;k++)DO
(3) C k = aprioriALL_generate ( L k-1 ); // C k 是从 L k-1 中产生的新的候选者BEGIN
(4) FOR eachcustomer-sequencec in DTDO //对于在数据库中的每一个顾客序列c
(5) Sum the count of allcandidates inCk that are contained inc;
//被包含于c中Ck内的所有候选者计数(4、5的意思是扫描数据库,得出每个Ck的支持度计数)
(6) Lk= Candidates inCk with minimum support //Lk=Ck中满足最小支持度的候选者
(7)END;
(8)Answer = Maximal Sequences in ∪kLk;
aprioriALL_generate(Lk-1)算法 :得到Ck ,此处不进行检查支持度。 如Table 5所示。
1. 链接Lk-1 和Lk-1
insert into Ck
select p.litemset(1),…, p.litemset(k-1), q.litemset(k-1)
from Lk-1 p,Lk-1q
where p.litemset(1) = q.litemset(1),…,
p.litemset(k-2) = q.litemset(k-2);
2. 剪枝
删除子序列不是Lk-1 的序列。
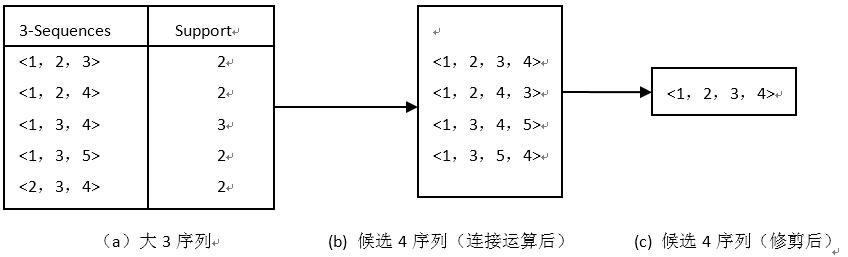
Table 5 AprioAll_Generate算法表
3.2 AprioriSome算法
3.2.1 算法讲解
AprioriSome分成两步:
1. 前推阶段(Forward Phase):寻找指定长度的大序列
2. 回溯阶段(Backward Phase):寻找剩余长度的大序列
伪代码如下:
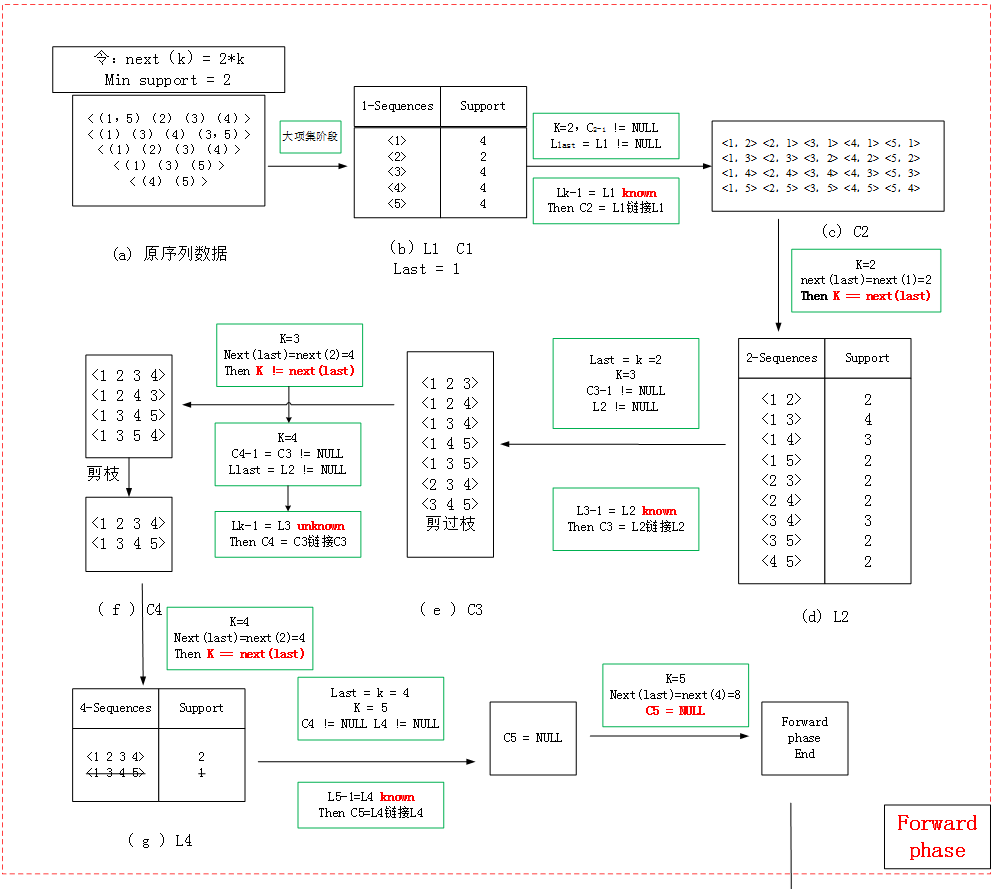
// Forward Phase
L1 = {large1-sequencesg}; //大项集阶段的结果
C1 = L1; // sothat we have a nice loop condition
last = 1; // we last counted Clast
for ( k = 2; Ck-1 !=NULL ; and Llast !=NULL; k ++ ) do
begin
if (Lk-1 known) then
Ck = New candidates generated from Lk-1; //由Lk-1链接得到Ck
else
Ck = New candidates generated from Ck-1;//由Ck-1链接得到Ck
if ( k == next(last) )then begin
for each customer-sequencec in the databasedo
Increment the count of all candidates in Ck that are contained in c. //计算支持度计数
Lk =Candidates in Ck with minimum support.
last = k;
end
end
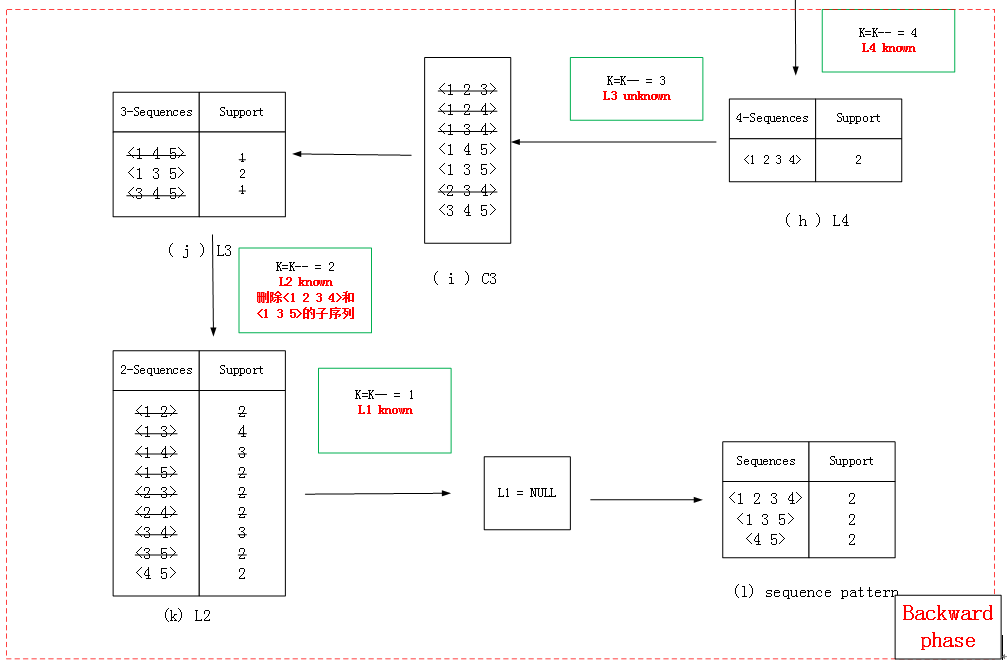
//Backward Phase
for( k--; k >= 1; k-- ) do
if (Lk not found in forward phase) then begin
Delete all sequences in Ck contained in some Li, i > k;
Foreach customer-sequence c in DT do
Increment the count of all candidates in Ck that are contained in c.
Lk = Candidates in Ck with minimumsupport.
else // Lk already known
Delete all sequences in Lk contained in some Li, i > k.
end
end
公式:next(k: integer):代表跳跃距离,指定长度的序列,可以是其他函数形式,例如next(k)= 2*k;下列公式是经验所得:
IF (hitk < 0.666)THEN return k + 1;
ELSE IF (hit k < 0.75)THEN return k + 2;
ELSE IF (hit k < 0.80)THEN return k + 3;
ELSE IF (hit k < 0.85)THEN return k + 4;
ELSE THEN return k+ 5;
hitk被定义为大k-序列(large k-sequence)和候选k-序列(candidate k-sequence)的比率,即|Lk|/|Ck|。这个函数的功能是确定对哪些序列进行计数,在对非最大序列计数时间的浪费和计算扩展小候选序列之间作出权衡。
3.2.2 算例
3.3 比较
AprioriAll用Lk-1计算出候选项Ck,而AprioriSome使用Ck-1计算出候选Ck,因为Ck-1包含Lk-1,所以AprioriSome会产生较多的候选项。由于AprioriSome属于跳跃式计算,会在某种程度上减少遍历数据库次数,如4.2.2部分的(j)L3由(i)C3较直接使用(e)C3遍历次数少,但是因为产生候选项比较多,可能在回溯阶段前就占满内存。
因此,对于较低的支持度,有较长的大序列,因此会有较多的non-max sequences,所以采用AprioriSome比较好。
4 参考文献
下载地址:链接:http://pan.baidu.com/s/1skICcY5密码:uygi















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









