







目录
实例描述
设计思路
执行步骤
wordcount代码
总结
实例描述
计算出文件中每个单词的频数,要求输出结果按照单词的字母顺序进行排序,按照key-value格式输出结果。
比如输入文件为:
hello world
hello hadoop
hello mapreduce
输出文件为:
hadoop 1
hello 3
mapreduce 1
world 1
设计思路
就是将文件内容切分成单词,然后将所有相同的单词聚集在一起,最后计算单词出现次数并输出。
根据MapReduce并行编程原则可知,内容切分步骤和数据不相关,可以并行化处理,每个获得原始
数据的机器只要将数据切分成单词就行。所以可以在Map阶段完成单词切分任务。另外,相同的单词
频数计算也可以进行并行处理。实例来看,不同单词之间的频数不相关。所以可以将相同的单词交给
同一台机器进行处理,然后输出结果。这个过程可以在Reduce过程完成。将中间结果在根据不同的
单词分组分发给不同的机器。
- Map阶段:完成由输入数据到单词切分工作
- shuffle阶段:完成相同单词的聚集和分发工作
- Reduce阶段:负责接收所有单词,并计数
MapReduce中数据传递都是key-value形式。shuffle排序聚集分发是按照key进行排序的
执行步骤
使用eclipse作为编译工具的:
1,新建MapReduce项目
2,检查MapReduce jar包集全不
3,写代码
4,配置运行参数
选择run Configurations
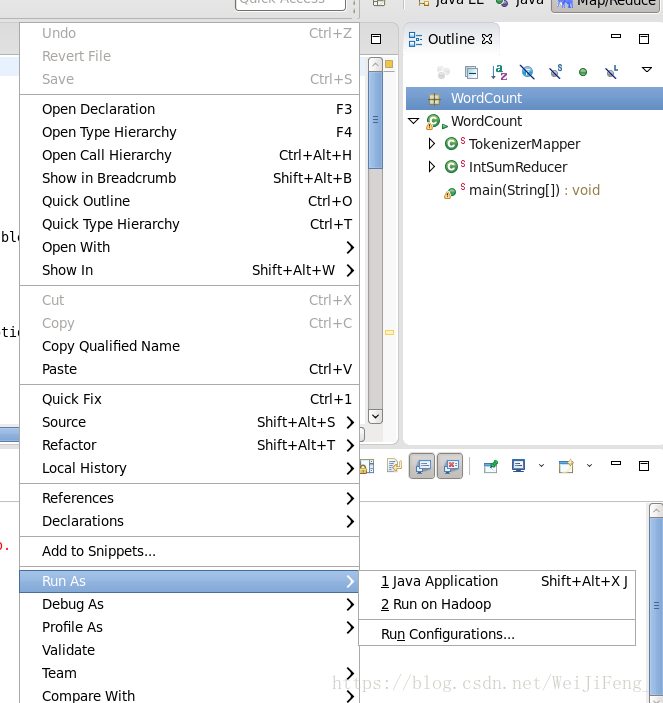
检查Mian方法路径
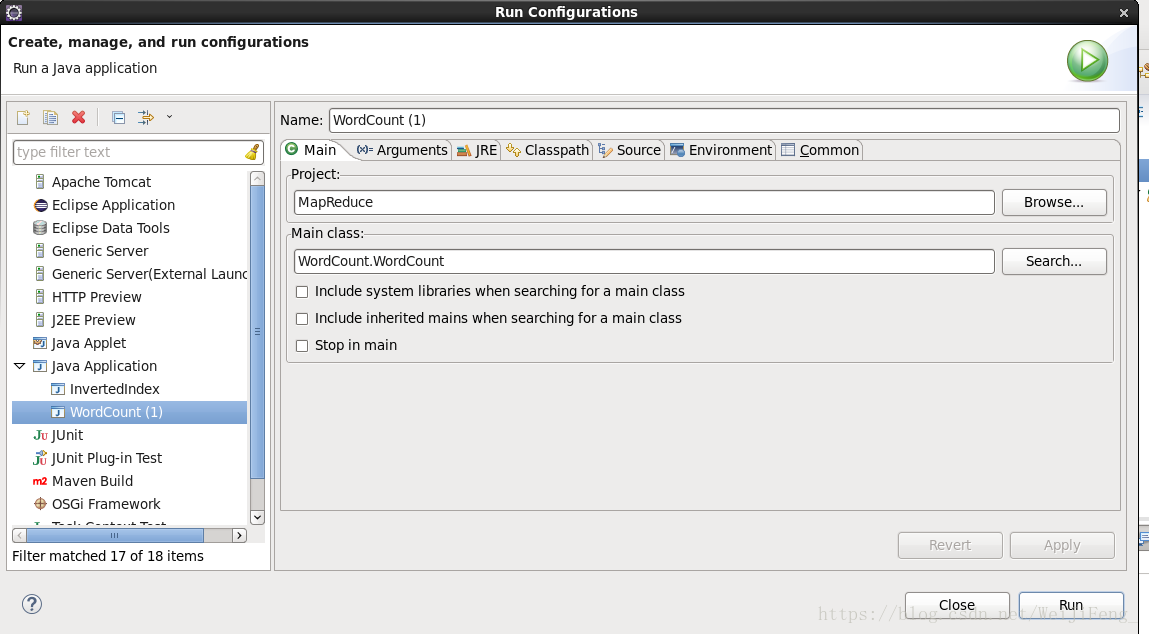
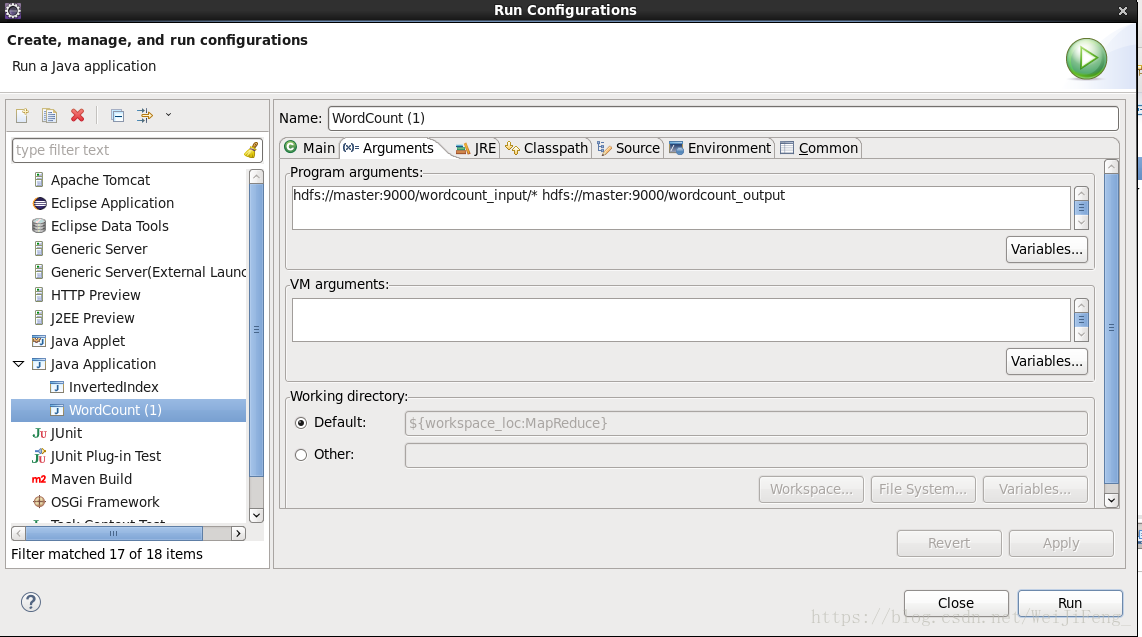
选择参数栏,第一个为输入文件的位置(Liunx上运行支持通配符匹配路径),第二个为输出文件位置,在run就能执行了,执行完毕,结果在对应的输出参数路径。
使用命令行执行的
1.先新建一个java文件
2.写好程序
3.编译程序
对于hadoop-1.x的编译指令为(仅为样例,版本不同,要改版本号)
javac -classpath hadoop-1.0.1-core.jar:lib/commons-cli-1.2.jar -d WordCount WordCount.java对于hadoop-2.x的编译指令为(仅为样例,版本不同,要改版本号)
javac -classpath $HADOOP_HOME/share/hadoop/common/hadoop-common-2.6.0.jar:$
HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar
-d /opt/hadoop-2.6.0-cdh5.6.0/MapReduceClass WordCount.java
这是因为hadoop-2.x版本没有core jar了,被拆分成多个jar了
打包成jar
jar -cvf wordcount.jar -C WordCount集群上运行程序
bin/hadoop jar wordcount.jar WordCount wordcount_input wordcount_output查看结果
bin/hadoop fs -cat wordcount_output/part-r-00000WordCount代码
package WordCount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
//继承Mapper接口,设置Mapper输入类型为 Object , Text>
//输出类型为<Text,IntWritable>
public static class TokenizerMapper extends Mapper<Object,Text,Text,IntWritable>{
//one 表示单词出现一次
private final static IntWritable one = new IntWritable(1);
//word用于储存切下的单词
private Text word = new Text();
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
word.set(itr.nextToken()); //切下的单词存入word
context.write(word,one);
}
}
}
//继承Reducer接口,设置Reduce的输入类型为<Text,IntWritable>
//输出类型为<Text,IntWritable>
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
//result记录单词的频数
private IntWritable result = new IntWritable();
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{
int sum = 0;
//对获取的<key,value-list>计算value的和
for(IntWritable val : values)
{
sum+=val.get();
}
//将频数设置到result
result.set(sum);
//收集结果
context.write(key,result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// conf.set("fs.hdfs.impl",org.apache.hadoop.hdfs.DistributedFileSystem.class.getName());
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length != 2){
System.err.println("Usage:wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf,"word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}总结
对于wordcount这个程序,开启了我MapReduce编程的第一步吧,最开始,看的书是1.0.1版本的
但是自己的环境是2.6.5版本的,在指令上,一直运行问题。后面查了查知道,hadoop-2.x,已经
没有core jar了。命令行运行一直失败。后来在进行改进,所以这个问题是很必要注意的














 2985
2985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









