







堆排序的时间复杂度是O(nlgN),与快速排序达到相同的时间复杂度。但是在实际应用中,我们往往采用快速排序而不是堆排序。这是因为快速排序的一个好的实现,往往比堆排序具有更好的表现。堆排序的主要用途,是在形成和处理优先级队列方面。另外,如果计算要求是类优先级队列(比如,只要返回最大或者最小元素,只有有限的插入要求等),堆同样是很适合的数据结构。
1、堆排序定义
二叉堆的定义:二叉堆是完全二叉树或者是近似完全二叉树。
二叉堆满足二个特性:
1.父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2.每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
当父结点的键值总是大于或等于任何一个子节点的键值时为最大堆。当父结点的键值总是小于或等于任何一个子节点的键值时为最小堆。
一般将二叉堆就简称为堆!!
堆的存储:一般都用数组来表示堆,i结点的父结点下标就为(i – 1)/ 2。它的左右子结点下标分别为2 * i + 1和2 * i + 2。如第0个结点左右子结点下标分别为1和2。
2、建堆
我们可以自底向上地来将一个数组A[n]变成一个最大堆(最小堆);
用大根堆排序的基本思想:
1、先将初始文件A[0..n-1]建成一个大根堆,此堆为初始的无序区
2、再将关键字最大的记录A[0](即堆顶)和无序区的最后一个记录R[n-1]交换,由此得到新的无序区A[0..n-2]和有序区R[n-1],且满足A[0..n-2].keys≤A[n-1].key
由于交换后新的根A[0]可能违反堆性质,故应将当前无序区A[0..n-2]调整为堆。
3、然后再次将A[0..n-2]中关键字最大的记录A[0]和该区间的最后一个记录R[n-3]交换,由此得到新的无序区A[0..n-3]和有序区A[n-2..n-1],且仍满足关系A[0..n-3].keys≤A[n-2..n-1].keys,同样要将A[1..n-2]调整为堆。
直到无序区只有一个元素为止。
用小根堆排序与利用大根堆类似,只不过其排序结果是递减有序的。
如图:
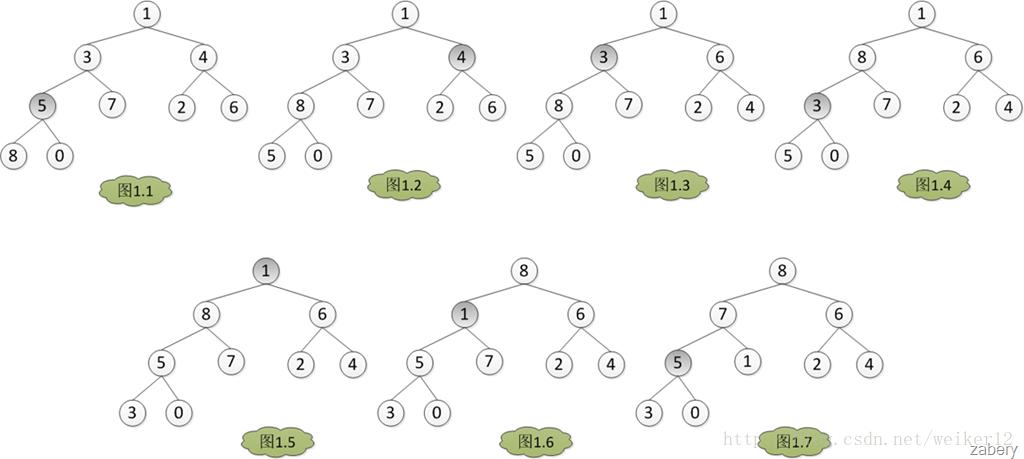
代码如下:
#include <iostream>
using namespace std;
int left(const int x) { return (2*x+1); }
int right(const int x) { return (2*x+2); }
// 调整以i为根的子树,使之成为最大堆,size为堆的大小
void maxHeapify(int a[], int size, int i)
{
int l = left(i);
int r = right(i);
int largest = i; // 最大堆的根
if( (l < size) && (a[l] > a[i]) ) largest = l;
if( (r < size) && (a[r] > a[largest]) ) largest = r;
if( largest != i )
{
swap(a[i], a[largest]); // 三个节点中较大者成为根
maxHeapify(a, size, largest); // 可能破坏了堆性质,重新调整
}
}
void buildMaxHeap(int a[], int size) // 建堆
{
for(int i = (size/2)-1; i>=0; i--)
{
maxHeapify(a, size, i);
}
}
void heapSort(int a[], int size) // 堆排序,(n-1)*O(lgn) = O(nlgn)
{
buildMaxHeap(a, size);
for(int i=size-1; i>0; i--) // 重复n-1次
{
swap(a[0], a[i]);
size--;
maxHeapify(a, size, 0); // 每次调整,花费为O(lgn)
}
}
int main()
{
int a[] = {1, 3, 4, 5, 7, 2, 6, 8, 0};
//a的首地址,a数组大小传过去。
cout << "堆排序前:";
for(int i = 0;i <= 8; i++)
cout << a[i] << " ";
heapSort(a, sizeof(a)/sizeof(a[0]));
cout << endl << "堆排序后:";
for(int i=0; i<sizeof(a)/sizeof(a[0]); i++)
{
cout << a[i] << " ";
}
cout << endl;
getchar();
getchar();
return 0;
}
3、算法分析
堆排序的时间,主要由建立初始堆和反复重建堆这两部分的时间开销构成
堆排序的最坏时间复杂度为O(nlgn)。堆排序的平均性能较接近于最坏性能。
由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。
它是不稳定的排序方法。
堆排序的优点在于建堆很快,只需要O(n)的时间,而且只需要一次建堆就可以反复利用,因此n越大效率就越高。















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









