







1、事务就是mysql里说的那个事务。
——比如我们在一组操作中故意设置个异常,导致第一个执行了第二个没执行。
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
try {
conn=DBUtil.getConnection();
ps=conn.prepareStatement("update account set money=money-100 where username='aaa'");
ps.executeUpdate();
int i=10/0;
ps=conn.prepareStatement("update account set money=money+100 where username='bbb'");
ps.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
}finally{
DBUtil.closeAll(null, ps, conn);
}
}——很显然,这是不对的。我们需要设置事务。设置方法如下:
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
try {
conn=DBUtil.getConnection();
conn.setAutoCommit(false); // 开启事务,因为默认是1个操作在1个单独的事务中提交,所以我们取消自动提交
ps=conn.prepareStatement("update account set money=money-100 where username='aaa'");
ps.executeUpdate();
int i=10/0;
ps=conn.prepareStatement("update account set money=money+100 where username='bbb'");
ps.executeUpdate();
conn.commit(); // 提交事务
} catch (Exception e) {
try {
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
} // 出现错误就回滚
e.printStackTrace();
}finally{
DBUtil.closeAll(null, ps, conn);
}
}2、事务的特征:原子性、一致性、隔离性、持久性。重点简洁隔离性。
——为什么要隔离?因为可以发生如下3种情况(都不是100%发生,但是越low的错误发生概率越大):
- 脏读。也就是我在一个事务过程中竟然读取到了另一个事务未提交的数据。
- 不可重复读。也就是说我第一次读取和第二次读取数据不同,重复读取就会发生改变,为什么会改变,是因为我在一个事务过程中竟然读取到了另一个事务通过update语句提交后的数据。
- 虚读(幻读)。和第2点雷同,但是另一个事务不是update语句提交的,而是insert语句提交的。我在一个事务中竟然读取到了它提交后的数据。
——按道理,我在一个事务中,应该是不受打扰的,虽然此时外部已经做了若干操作,但是在我目前的这个事务中应该保证我获得的数据是不变的(也就是可重复读取的),也就是说这个时候另一个事务有未提交的数据,我是读取不到的,提交的数据我也读取不到。
——对应以上3种情况,就出现了几种隔离级别。
- READ UNCOMMITTED。这种级别就是狗屎,以上3种情况一种都无法阻止。
- READ COMMITRED。这种级别专治未提交的数据,所以可以避免第1种脏读的情况,不可重复读和虚读还是无法避免。这种级别是oracle数据库默认的隔离级别。
- REPEATABLE READ。看名字就知道比上面的级别高级了一点,从名字就可以看出来,它可以避免脏读和不可重复读的问题,但是虚读还是无法避免。这种级别是mysql默认的隔离级别。
- SERIALIZABLE。这种级别最高,3种情况都可以避免。
——需要注意的是:隔离级别越高,数据越安全,但是性能越低。
——查询当前事务的隔离级别:
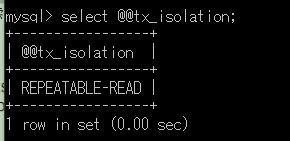
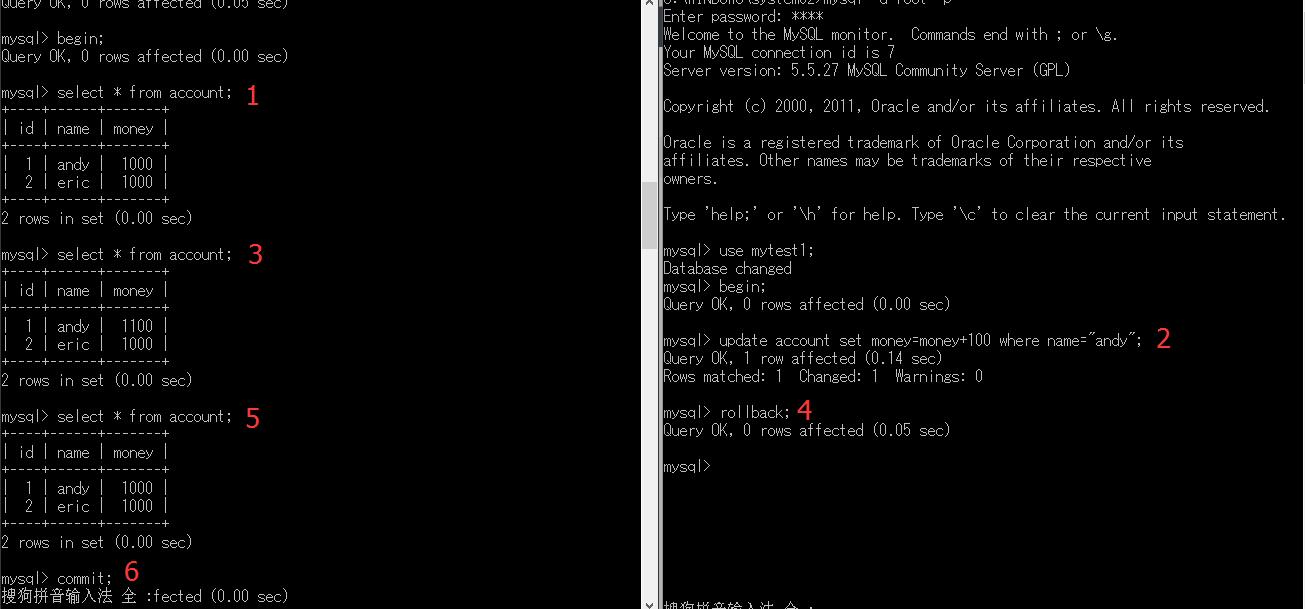
——利用设置不同隔离级别来做实验,看看不同事务之间的数据影响。经过测试,我们当我们把隔离级别设置成set transaction isolation level repeatable read的时候,尽管在另一个进程中进行了insert语句更改数据,但是在我们的当前事务中貌似没有受到影响,所以说上面说得虚读这些错误只是有可能发生,并不一定百分百每次发生。
——那我们在java代码中怎么设置隔离级别呢?一句代码即可,但要注意隔离级别的设置一定要在开启事务之前。这里面的参数是一个int类型,对应着上面4个级别的值分别是1、2、4、8,当然也可以利用下面这种方式使用常量。
conn.setAutoCommit(false);
……
conn.commit();3、连接池负责分配、管理、释放数据库连接。以前我们是一个连接是先创建、然后使用。最后释放被回收,有了连接池之后,我们创建了一个连接、然后使用、使用完不释放而是放回到连接池中供下一个用户使用,提高了性能。另一个提高性能的地方在于,连接池会查找那些空闲时间超过设置值的连接以防数据库连接遗漏。
4、连接池的使用。当然可以手动写一个,但是我们有很多现成的框架可以用。比如我们说的第一个DBCP。
——添加jar包。当然如果我们用的mysql数据库,别忘了mysql连接的那个jar包。
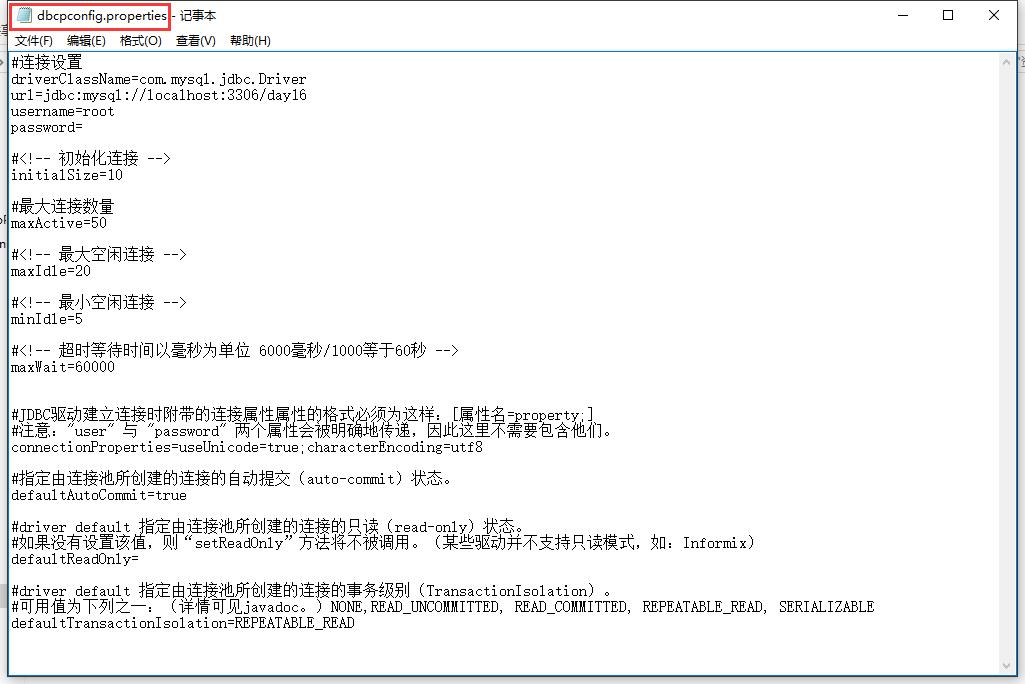
——添加属性资源文件,有现成的,修改完里面的值之后直接使用即可。
——编写工具类DBCPUtil,写getConnection和realease方法。这里面比较陌生的就是加载这个properties文件并且转化成inputStream的知识点。我们先获取到当前类>当前类的class文件>new一个实例>调用getResourceAsStream方法,这就是那句加载里面语句的每个部分的作用。
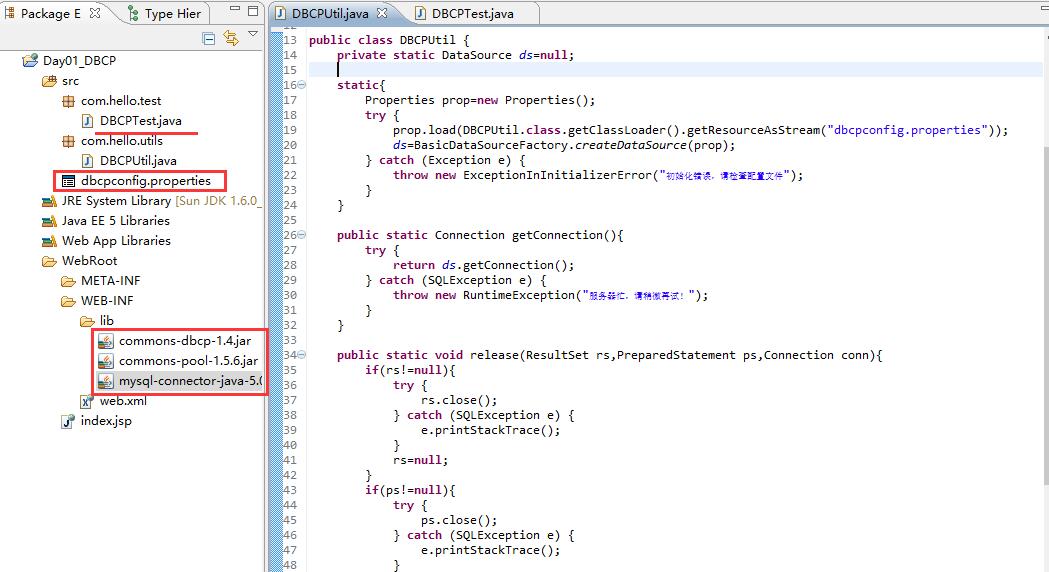
——使用的时候。
public static void main(String[] args) {
Connection conn=null;
PreparedStatement ps=null;
try {
conn=DBCPUtil.getConnection();
ps=conn.prepareStatement("insert into fuser(username,pwd,email) values(?,?,?)");
ps.setString(1, "tom");
ps.setString(2, "123");
ps.setString(3, "tom@163.com");
ps.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
}finally{
DBCPUtil.release(null, ps, conn);
}
}DBCP源代码:JavaEE DBCP简单案例
5、C3P0。和上面的差不多的步骤。(WebProject不需要对jar包进行buildPath,JavaProject需要)
——先加载jar包。jar包一定要放在/lib/下面,如果是Java Project需要自己手动建一个lib目录。
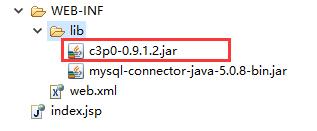
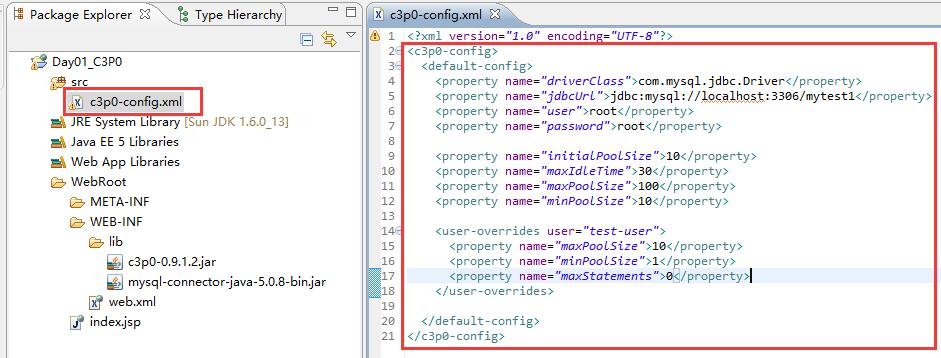
——加载配置文件。这个配置文件是直接写在xml的。而且这个xml有严格的要求,比如一定要在src下面,因为它要求是在classes目录里,比如名字只能是c3p0-config.xml。
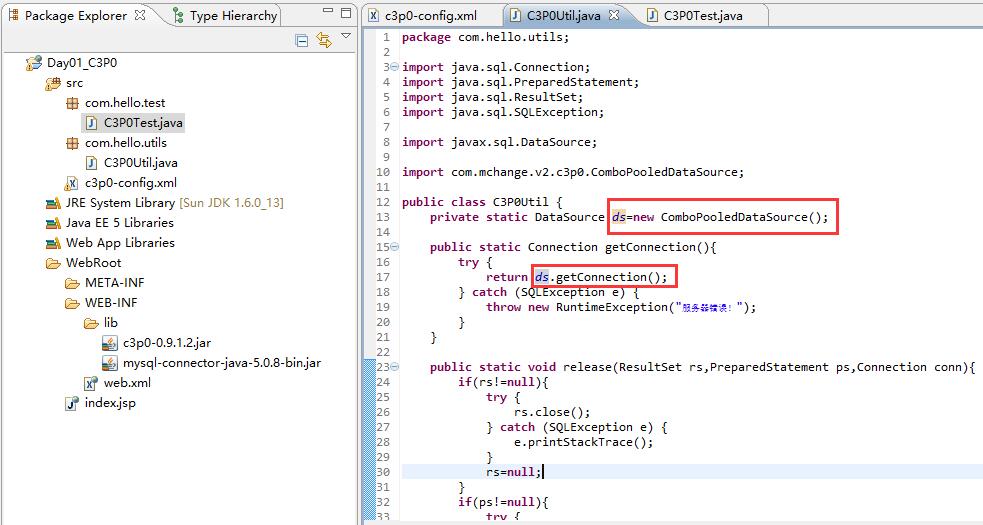
——写C3P0Util工具类。我们看到,这比DBCP好的地方就在于,我们不用手动加载properties文件,我们把xml文件放置在正确的位置,然后配置正确的信息后,它貌似可以自动获取到。所以我们在工具类里面根据没有看到任何关于c3p0-config.xml的代码。只需要private static DataSource ds=new ComboPooledDataSource();,把数据源实例化出来,就可以直接调用getConnection()。
——最后一步,就是使用。使用方法,和DBCP一样样的。
public static void main(String[] args) {
Connection conn=null;
PreparedStatement ps=null;
try {
conn=C3P0Util.getConnection();
ps=conn.prepareStatement("insert into fuser(username,pwd,email) values(?,?,?)");
ps.setString(1, "jerry");
ps.setString(2, "123");
ps.setString(3, "jerry@163.com");
ps.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
}finally{
C3P0Util.release(null, ps, conn);
}
}C3P0源代码:JavaEE C3P0简单案例
6、利用JavaWeb服务器管理数据源,也就是用我们的Tomcat。为什么呢?因为我们打开我们的服务器,里面的lib下发现有一个tomcat-dbcp.jarjar包。相当于内置了jar了。
——没有多余的jar包需要导入,只要把数据库连接的jar包拿进来就行。
——配置数据源的xml文件。1)服务器的conf目录下面有一个context.xml文件,如果我们在这里配置的话那么服务器上所有的应用都能使用这个数据源;2)还有一种做法是在META-INF目录下创建一个context.xml,这样的话这个配置数据源只能当前应用可用。可以去tomcat的dbcp配置文档中找示例。
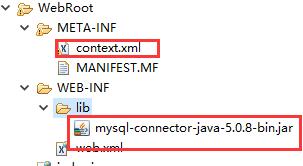
<?xml version="1.0" encoding="UTF-8"?>
<Context>
<Resource name="jdbc/TomcatDBCP" auth="Container" type="javax.sql.DataSource" maxActive="100" maxIdle="30" maxWait="10000" username="root" password="root" driverClassName="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/mytest1"/>
</Context>——写个工具类TomcatDBCPUtil。
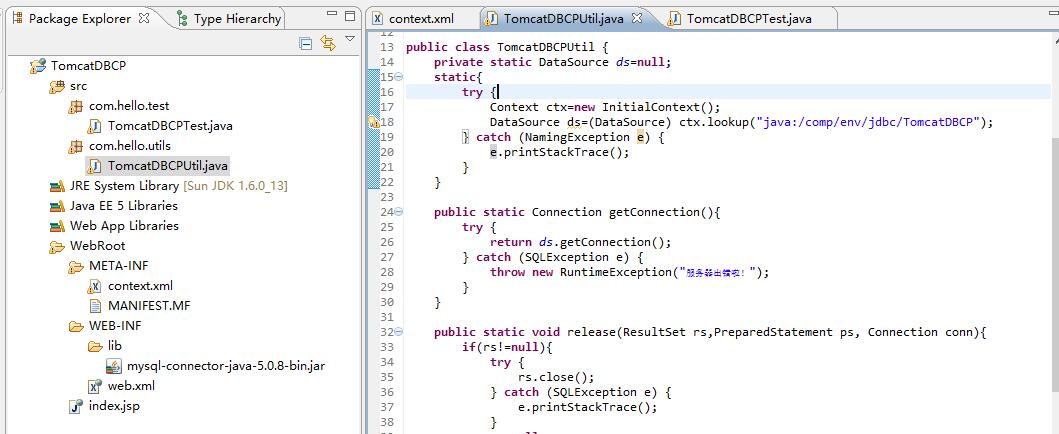
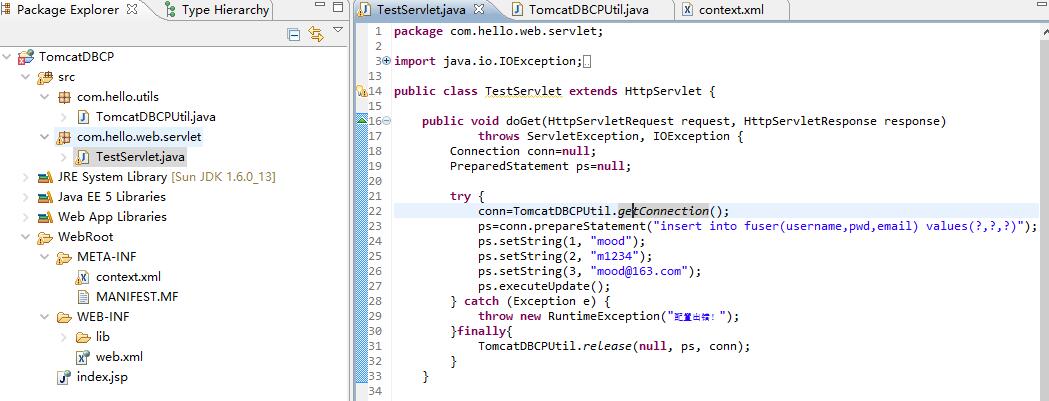
——写个使用类,在main函数中使用,出错,原因是在不能普通类的main函数中用,需要在tomcat环境下使用也就是jsp或者servlet中:
javax.naming.NoInitialContextException: Need to specify class name in environment or system property, or as an applet parameter, or in an application resource file: java.naming.factory.initial——我们新建一个servlet来测试代码,成功!
——当然。我们上面说,可以在tomcat服务器的conf/context.xml中配置数据源的信息,理所当然的,强大的地方在于,我们可以在这个context.xml里面配置多个数据源,然后我们使用的时候根据name来选择对应的数据源。name在哪里选择的呢?在如下代码中。其中java:/comp/env/jdbc/TomcatDBCP是两部分组成的,前面path是java:/comp/env,后面就是name的值jdbc/TomcatDBCP。其实下面的代码是两部合并成一步了。
Context ctx=new InitialContext();
ds=(DataSource)ctx.lookup("java:/comp/env/jdbc/TomcatDBCP");官方代码中,是分成2步,这样就能体现出path和name的作用了。
Context initContext=new InitialContext();
Context envContext=(Context)initContext.lookup("java:/comp/env");
DataSource ds=(DataSource)envContext.lookup("jdbc/TomcatDBCP");使用Tomcat管理数据源的源代码:JavaEE 使用Tomcat的自带DBCP管理数据源案例
7、数据源操作数据库的主要步骤是:
——如果有需要导入jar包的就导入jar包,只有tomcat有自带的dbcp。当然不管哪一种方式,如果使用mysql的话需要导入mysql的连接jar包。
——然后,配置文件。这里面比如使用外部DBCP时用的是一个properties文件,使用C3P0时用的是规定好的c3p0-config.xml文件,使用tomcat自带的dbcp时用的是在tomcat服务区的conf/context.xml或者在META-INF里创建个context.xml文件,总之不管哪一种方式,你总得配置一些信息,比如数据库、用户名、密码、连接池的最大连接数、空闲等待时间等信息。
——然后,就是写工具类,自己命名。工具类主要提供两个方法,一个是getConnection,一个是release方法。当然,在这个工具类里面,我们使用的是我们jar包里提供的数据源方法来获取connection的,所以我们第一步是在static静态块里面获取DataSource(不同的方法获取方式不同,有的是加载配置文件,有的根本不需要显式加载文件,只要new一个类就行等等)。
——最后,就是使用了。需要注意的是tomcat自带的dbcp写好工具类后,是不能在java类的main方法中使用的,需要在tomcat环境下使用,也就是jsp或者servlet中使用。















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









