







JAVA基础系列规划:
- JAVA基础(1)——基本概念
- JAVA基础(2)——数据类型
- JAVA基础(3)——容器(1)——常用容器分类
- JAVA基础(4)——容器(2)——普通容器
- JAVA基础(5)——并发(1)——总体认识
- JAVA基础(6)——并发(2)——原子
- JAVA基础(7)——并发(3)——锁机制
- JAVA基础(8)——并发(4)——线程池
- JAVA基础(9)——容器(3)——并发容器
- JAVA基础(10)——IO、NIO
- JAVA基础(11)——泛型
- JAVA基础(12)——反射
- JAVA基础(13)——序列化
- JAVA基础(14)——网络编程
- 1. 基本类型
- 2. 引用类型
- 数组
- 字符串
- 容器
- 过时的容器
- 常用非并发容器
- 并发容器
- 【1】CopyOnWriteArrayList
- 【2】ArrayBlockingQueue
- 【3】LinkedBlockingQueue
- 【4】DelayQueue
- 【5】SynchronousQueue
- 【6】PriorityBlockingQueue
- 【7】ConcurrentLinkedDeque
- 【8】LinkedBlockingDeque
- 【9】ConcurrentLinkedQueue
- 【10】LinkedTransferQueue
- 【11】CopyOnWriteArraySet
- 【12】ConcurrentSkipListSet
- 【13】ConcurrentHashMap
- 【14】ConcurrentSkipListMap
JVM将数据类型可以分为两类:
- 基本类型。变量保存原始值,即遍历代表的值就是数值本身;
- 引用类型。变量保存引用值。“引用值”代表了某个对象的引用,而不是对象本身,对象本身存放在这个引用值所表示的地址的位置。
1. 基本类型
基本类型包括:byte, short, int, long, char, float, double, Boolean。
具体字面意思参考Oracle文档
基本类型之间的转换
将一种类型的值赋给另一种类型是很常见的。在Java中,boolean类型与所有其他7种类型都不能进行转换,这一点很明确。对于其他7中数值类型,它们之间都可以进行转换,但是可能会存在精度损失或者其他一些变化。转换分为自动转换和强制转换。对于自动转换(隐式),无需任何操作,而强制类型转换需要显式转换,即使用转换操作符(type)。首先将7种类型按下面顺序排列一下:
byte <(short=char)< int < long < float < double
如果从小转换到大,可以自动完成,而从大到小,必须强制转换。short和char两种相同类型也必须强制转换。
2. 引用类型
引用类型包括:类类型,接口类型,数组和null。
- 类类型。类类型变量不同于基本类型变量存储值的方式。不管是基本变量还是类类型变量,都实现为一个内存位置。但是,由于基本变量所需的内存数量是相同的,所以系统可以给它设置一个固定的空间保持命名对象的变量。类类型变量则不同,由于它的长度不确定,从而使得系统难以给其分配一个固定的空间来保存命名对象的变量。因此,对于类类型变量,它存储的是对象的内存地址,而不是对象本身。
- 接口类型。
- 数组。数组是一种高效的存储和随机访问对象引用序列的方式,使用数组可以快速的访问数组中的元素。但是当创建一个数组对象(注意和对象数组的区别)后,数组的大小也就固定了,当数组空间不足的时候就再创建一个新的数组,把旧的数组中所有的引用复制到新的数组中。
- null。null是一种特殊的type,但是你不能声明一个变量为null类型,null type的唯一取值就是null。null可以负值给任意的引用类型或者转化成任意的引用类型。在实践中,一般把null当做字面值(literal),这个字面值可是是任意的引用类型。
计算机只有2种方法来表达数据元素之间的逻辑关系,一种是顺序存储结构,借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系;另一种是链式存储结构,借助元素存储地址的指针来表示数据元素之间的逻辑关系。
数据结构是相互之间存在一种或多种特定关系的数据元素的集合。根据数据元素之间关系的不同特性,一般有4类基本逻辑结构:线性结构、树形结构、集合、图状结构或网状结构,当然这些基础结构还可以衍生出很多其他逻辑结构。
数组
所有的高级程序语言会用一维数组类型来描述顺序存储结构,Java也不例外:
int[] x = {1, 2};
int[] x = new int[2];
一维数组使用一组地址连续的存储单元依次存储线性表的数据元素。数组是一种高效的存储和随机访问对象引用序列的方式,使用数组可以快速的访问数组中的元素。但是当创建一个数组对象(注意和对象数组的区别)后,数组的大小也就固定了,必须事先对数组容量进行估计,容量小了不够用,容量大了可能会浪费空间。当然,数组扩容也可以实现当数组空间不足的时候就再创建一个新的数组,把旧的数组中所有的引用复制到新的数组中。扩容的速度常常和数据量相关,数据量小的时候,数组扩容速度快,数据量大的时候,数组拷贝需要占用大量内存和其他资源,增加系统负载,速度更慢。
在操作数组时需要进行边界检查,如果越界就会得到一个RuntimeException异常。一般情况下,考虑到效率与类型检查,应该尽可能考虑使用数组。如果要解决一般化的问题,数组可能会受到一些限制,这时可以使用Java提供的容器类。
在java.util.Arrays类中,有许多static静态方法,主要实现数组的排序、复制等功能。通常我们会使用Arrays.asList来生成一个List,这个List是Arrays里面的静态类Arrays.ArrayList,Arrays.ArrayList和ArrayList的最大区别在于Arrays.ArrayList维护的是E[]数组,而ArrayList维护的是Object[]数组。因此要特别注意Arrays.ArrayList.toArray和ArrayList.toArray获取的数组类型是不一样的。
字符串
还有一种线性结构叫字符串,字符串的逻辑结构和线性表极为类似,字符串具有线性表所有的特性,但字符串中的数据对象只能是字符集,同时扩展了字符集操作特性。Java有三种字符串的实现:
最早出现的是String和StringBuffer,从jdk1.0开始就已存在。String内部使用一个final char数组来保存字符串,final修饰保证了数据不可变。每一次change操作都会生成新的对象,不会对原对象产生影响。因为String不可变,所以不存在数组扩容的问题,不存在线程安全问题。其他需要注意的是,String是final类,表明了String类是不可继承的,并且默认它的成员方法都final方法。使用final,一方面是为了锁定方法,另一方面在早期版本中jvm会将final方法转为内嵌调用以提升效率,但从jdk1.6开始淡化这种转换。因此在现在的Java SE版本中,不需要考虑用final去提升方法调用效率。只有在确定不想让该方法被覆盖时,才将方法设置为final。String实现了Serializable、Comparable、CharSequence,因此可序列化、可比较、可进行char数组操作。
StringBuilder内部也使用一个char数组,但这个数组是可以变的,如append方法对字符串追加。数组可变涉及到扩容问题,StringBuilder内部动态维护char数组的大小。其他需要注意的是,StringBuilder是final类,表明了StringBuilder类是不可继承的,并且默认它的成员方法都final方法。StringBuilder继承AbstractStringBuilder,实现Serializable、CharSequence。AbstractStringBuilder实现了Appendable、CharSequence。
StringBuffer是jdk5出现的,内部也使用一个char数组,数组也是可以变的,也内部动态维护char数组的大小,也是final类,也继承AbstractStringBuilder,实现Serializable、CharSequence。更重要的是,StringBuffer还解决了一个很重要的问题,多个线程同时操作char数组时,会出现线程安全问题,StringBuffer对所有方法加同步锁保证了操作char数组的线程安全性。
总的来说,三者内部都维护着char数组,区别在于:
(1)从线程安全性上来看,String和StringBuffer是线程安全的。String是不可变的,每次更新操作都产生新的对象,因此线程安全。StringBuffer通过对方法加同步锁实现线程安全。StringBuilder内部char数组可变,同时方法未加同步锁,因此非线程安全。
(2)从性能上来说,每次对String类型进行改变的时候,都会生成一个新的String对象,然后将指针指向新的String对象。StringBuffer每次都会对 StringBuffer对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用StirngBuilder相比使用StringBuffer仅能获得10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
容器
Java的容器就是对逻辑结构的封装,内部持有对象,实现对象的逻辑关系。从接口的角度来看,Java的容器主要分成了Map和Collection两个大的类别。
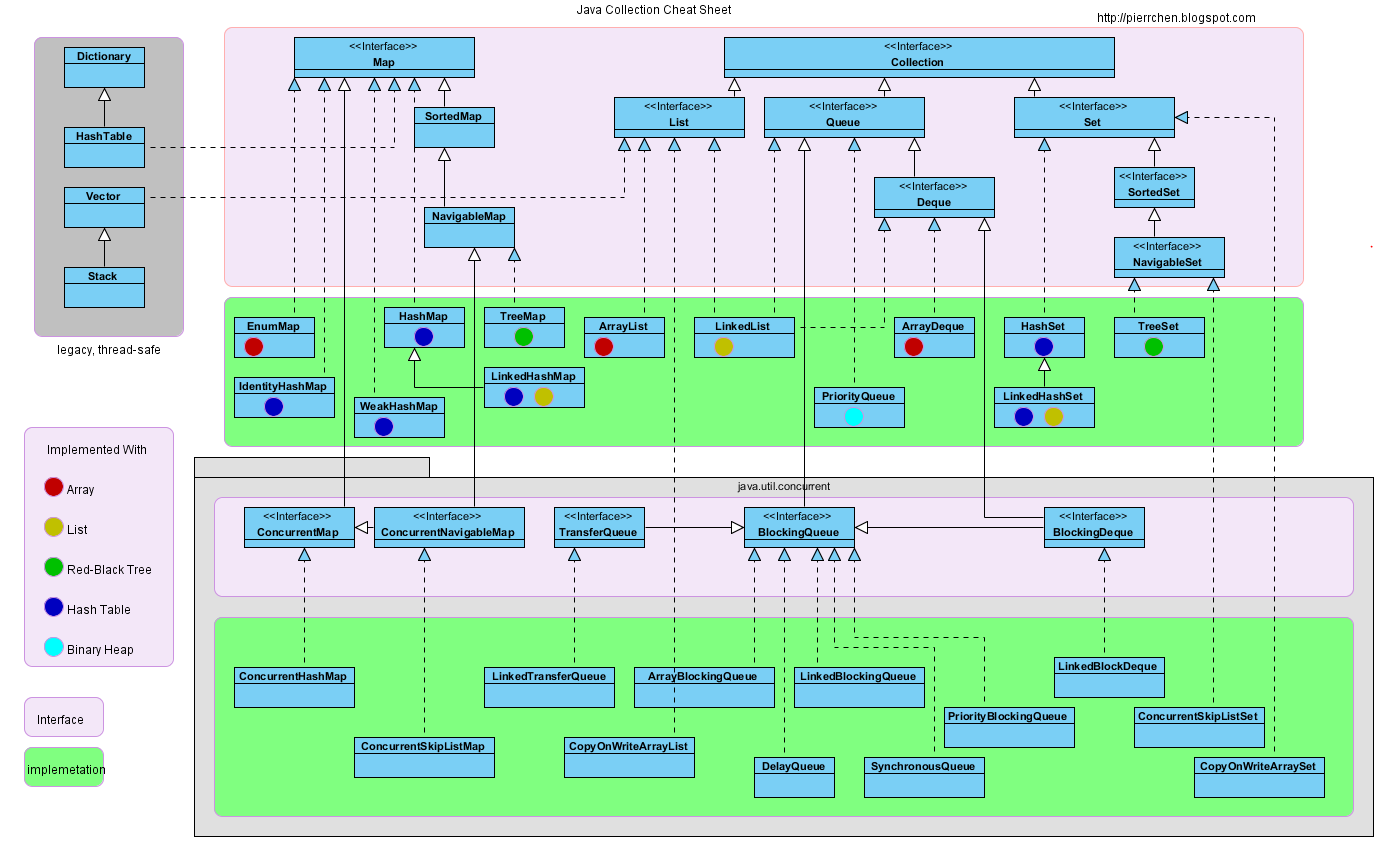
图片左上角的那一块灰色里面的四个类(Dictionary、HashTable、Vector、Stack)都是线程安全的,但是它们都是JDK的老的遗留类,现在基本都不怎么使用了,都有了对应的取代类。其中Map是用来代替图片中左上角的那个Dictionary抽象类(Map的官方文档里面有说明)。官方推荐使用Map接口来代替它。同样对于HashTable,官方推荐ConcurrentHashMap来代替。接着下面的Vector是List下面的一个实现类。
过时的容器
Vector
Vector是最早的List,jdk1.0出现,内部实现:
1. 底层为数组,Object[] elementData,初始容量为10。
2. 扩容:容量是可以动态变化的(当然扩容也是有最大容量限制的),默认情况下,每次扩容到当前容量大小的一倍,但不超过MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8。扩容时会发生信息数据拷贝,性能会受影响。
3. 线程安全:数组元素的操作是同步的,保证了数据的安全。但同步会有大量的性能的损失,在单线程使用过程中不需要这一措施,这是ArrayList等非线程安全容器出现的一个原因。
4. 序列化时会序列化整个数组,包括未存储数据的区域。
Stack
Java里有一个叫做Stack的类,却没有叫做Queue的类(它是个接口名字)。当需要使用栈时,Java已不推荐使用Stack,而是推荐使用更高效的ArrayDeque;既然Queue只是一个接口,当需要使用队列时也就首选ArrayDeque了(次选是LinkedList)。
Hashtable
Hashtable源自jdk1.0,继承Dictionary,实现Map、Cloneable、Serializable。其内部实现是:
1. 内部维护private transient Entry< ?,?>[] table。默认容量为11,默认负载因子为0.75。
2. 散列:通过散列的方法将元素散列到表的不同行上,table的每一行都是一个链表。相同hashcode的元素在同一行,通过链表链接,Entry是链表的一个节点。
3. 再哈希:当table元素个数超过threshold = (int)Math.min(currentCapacity * loadFactor, MAX_ARRAY_SIZE + 1)时,会进行再哈希,再hash后table大小为newCapacity = (oldCapacity << 1) + 1,但不能超过MAX_ARRAY_SIZE。
4. 线程安全:因为和table相关的方法都是synchronized的,所以线程安全。
5. 序列化时会取出所有数据元素进行序列化。
常用非并发容器
图片最上面的粉红色部分是集合类所有接口关系图。其中Map的结构比较简单,而Collection的结构就相对复杂一些。Collection有三个继承接口:List、Queue和Set。接下来绿色部分则是集合类的主要实现类了。这也是我们最经常使用的集合类了。
- List接口: ArrayList、LinkedList
- Queue接口:PriorityQueue、LinkedList、ArrayQueue
- Set接口: HashSet、LinkedHashSet、TreeSet
- Map接口: HashMap、LinkedHashMap、WeakHashMap、TreeMap、EnumMap、IdentityHashMap
ArrayList
ArrayList源自jdk1.2,和Vector有些类似,区别主要在同步、数据序列化方面,内部实现:
1. 底层数组Object[] elementData,初始容量10。
2. 扩容:容量可以动态变化,扩容为newCapacity = oldCapacity + (oldCapacity >> 1)。扩容时会发生信息数据拷贝,性能会受影响。
3. 有效序列化:elementData是transient修饰的,表示序列化时不序列化elementData。在序列化的时候会调用writeObject,直接将size和element写入ObjectOutputStream;反序列化时调用readObject,从ObjectInputStream获取size和element,再恢复到elementData。使用这种序列化的原因在于,elementData是一个缓存数组,通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用序列化方式,可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
4. 高效随机访问,依靠的是数组的特性。
5. 添加操作没有效率,这个操作可能会引起ArrayList的扩容,扩容的时候会copy数组浪费点时间,而LinkedList扩容没有问题。
6. 删除操作需要移动数组,按照index进行删除时耗时只在移动数组上,按对象进行删除时耗时在两方面,一方面需要从头比较元素,另一方面进行删除并移动数组。
7.
8. 非线程安全:数组元素不是final,同时数组元素的操作也未考虑线程安全,因此ArrayList非线程安全。
9. 线程安全化:要让ArrayList变的线程安全,可使用Collections.synchronizedLis获取ArrayList线程安全封装类。这个封装类实际上是对操作数据的方法进行了synchronized的包装。
LinkedList
LinkedList源自jdk1.2,也是一个线性表,但是是链式线性表,内部实现为:
1. 内部维护一个链表,Node< E> first是链表头节点,Node< E> last是链表尾节点,这两个变量只是链表的标识,没有实际的数据意义,因此被transient修饰,不序列化。
2. 有效序列化:在序列化时会调用writeObject,将size和遍历得到的数据进行序列化。
3. 随机访问效率低,大于size>>1的位置,从表头依次查找,小于size>>1的位置,表尾依次查找。
4. 添加操作比较高效,没有扩容问题。
5. 删除操作的耗时主要在数据查找,需要找到指定index的元素或者指定value的元素,删除Node的耗时很小。
6. 非线程安全:由于LinkedList的Node,既不是final的,操作Node的部分也不是线程安全的,因此LinkedList是非线程安全的。
7. LinkedList还实现了Queue接口,具有先进先出的特性。
ArrayDeque
ArrayDeque源自jdk1.6,需要使用队列特性时,首选ArrayDeque,内部实现:
1. 内部是循环数组结构,数组的任何一点都可能被看作起点head或者终点tail,使用(tail = (tail + 1) & (elements.length - 1)) == head判断是否越界。
2. 扩容:可以动态扩容,默认扩容为当前容量的一倍。扩容时会发生信息数据拷贝,性能会受影响。
3. 有效序列化:和ArrayList类似,序列化时只序列化有效数据。
4. 非线程安全:数组元素即非final,同时数组元素的操作也未考虑线程安全,因此ArrayDeque非线程安全。
5. 用途:作为堆栈时,它比Stack快;作为队列时,它比LinkedList快。
PriorityQueue
PriorityQueue源自jdk1.5,队列中元素按照优先级进行存储,保证每次取出的元素都是队列中权值最小的,内部实现:
1. 内部是数组实现的小根堆,每一次数据添加和删除都会进行堆的调整。
2. 大小关系:元素大小的评判可以通过元素本身的自然顺序(natural ordering),也可以通过构造时传入的比较器。
2. 扩容:扩容大小newCapacity = oldCapacity + ((oldCapacity < 64) ? (oldCapacity + 2) : (oldCapacity >> 1));。扩容时会发生信息数据拷贝,性能会受影响。
3. 非线程安全:数据元素操作也是非线程安全的,因此PriorityQueue也是非线程安全的。
HashSet
HashSet源自jdk1.2,内部实现:
1. 内部维护着HashMap,是一个key-value结构。Set的数据是map的key,因此创建一个private static final Object PRESENT = new Object()作为value。
2. 操作基本都是围绕map的key进行操作。
3. 和HashMap一样,非线程安全。
4. 有两种HashMap的实现,一种是HashMap,一种是LinkedHashMap.
LinkedHashSet
LinkedHashSet源自jdk1.4,内部实现:
1. extends HashSet< E> implements Set<E>, Cloneable, java.io.Serializable。
2. 区别只在内部HashMap的实现上,用的是LinkedHashMap,默认容量为16,默认负载因子为0.75。
3. 其他操作和HashSet一样。
4. 非线程安全
TreeSet
TreeSet源自jdk1.2,内部实现:
1. extends AbstractSet< E> implements NavigableSet< E>, Cloneable, java.io.Serializable。
2. 和其他Set内部实现类似,维护一个map,但这个map是 NavigableMap<E,Object>。map的key是Set的数据,map的value都是new Object()。
3. 默认使用new TreeMap< E,Object>()实现NavigableMap。
4. 非线程安全。
HashMap
HashMap源自jdk1.2,存储键值对,可接受null键和值,速度快,非线程安全,内部实现:
1. extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
2. 内部维护transient Node<K,V>[] table,存储的是Map.Entry,默认容量16,最大容量1 << 30,默认负载因子0.75。
3. put操作。根据key的hashCode()计算Entry在bucket中的位置,将Entry写入相应的位置。
4. 碰撞。如果两个key的hashCode()相同,它们在bucket中的位置相同,使用链表存储Entry。比较key的equals(),如果相同就用当前的Entry覆盖原来的Entry,如果不相同就把当前的Entry加入到链表
5. get操作。根据key的hashCode()计算Entry在bucket中的位置,然后获取值对象。如果有两个值对象储存在同一个bucket,将会遍历链表,通过key的equals()寻找链表中正确的节点,最终找到值对象。
6. 扩容。默认大小为16,默认负载因子大小为0.75。如果HashMap的大小超过了负载因子定义的容量,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。
7. 再哈希。扩容时会发生rehasing,旧的bucket数组中的对象会被放入新的bucket数组中,这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
8. 再哈希死循环。当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。这也是线程安全性问题,因此不能在多线程环境下使用HashMap。
9. 键的不可变性。String, Interger这样的wrapper类作为HashMap的键是再适合不过了,而且String最为常用。因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
10. 自定义键。当然你可能使用任何对象作为键,只要它遵守了equals()和hashCode()方法的定义规则,并且当对象插入到Map中之后将不会再改变了。如果这个自定义对象时不可变的,那么它已经满足了作为键的条件,因为当它创建之后就已经不能改变了。
LinkedHashMap
LinkedHashMap源自jdk1.4,继承HashMap,实现Map。内部是Hash表和双向链表的实现,并依靠双向链表保证迭代顺序是插入的顺序。table相关操作未加线程安全,因此非线程安全。
链表的维护是依靠重写HashMap的三个函数:
afterNodeAccess(Node< K,V> p)
afterNodeInsertion(boolean evict)
afterNodeRemoval(Node< K,V> p)
WeakHashMap
WeakHashMap源自jdk1.2,和HashMap一样,WeakHashMap 也是一个散列表。具有弱键特性,当某个键不再正常使用时,会被从WeakHashMap中被自动移除。更精确地说,对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。某个键被终止时,它对应的键值对也就从映射中有效地移除了。非线程安全。
关于弱键,大致上通过WeakReference和ReferenceQueue实现的。eakHashMap的key是“弱键”,即是WeakReference类型的;ReferenceQueue是一个队列,它会保存被GC回收的“弱键”。当某“弱键”不再被其它对象引用,并被GC回收时。在GC回收该“弱键”时,这个“弱键”也同时会被添加到ReferenceQueue(queue)队列中。当下一次我们需要操作WeakHashMap时,会先同步table和queue。table中保存了全部的键值对,而queue中保存被GC回收的键值对;同步它们,就是删除table中被GC回收的键值对。
TreeMap
TreeMap源自jdk1.2,内部实现:
1. 内部维护红黑树,要更好的理解TreeMap还是需要学习下红黑树算法,需要学习详细实现的,请看源码。红黑树是一种平衡排序二叉树。树中的任何节点的值大于它的左子节点,且小于它的右子节点,同时任何节点左右两个子树的高度差的绝对值不超过1。
2. 值比较。根据comparator进行值比较,保证数据的顺序。如果需要按自然顺序或自定义顺序遍历键,它是不错的选择,从其中取出来是排序后的键值对。每次put操作内部插入数据后,进行红黑树的再平衡。非线程安全。
3. put操作。put操作主要分为两个步骤,第一:构建排序二叉树,第二:平衡二叉树。
4. 对于排序二叉树的创建,其添加节点的过程如下:
(1)以根节点为初始节点进行检索。
(2)与当前节点进行比对,若新增节点值较大,则以当前节点的右子节点作为新的当前节点。否则以当前节点的左子节点作为新的当前节点。
(3)循环递归2步骤知道检索出合适的叶子节点为止。
(4)将新增节点与3步骤中找到的节点进行比对,如果新增节点较大,则添加为右子节点;否则添加为左子节点。
5. 普通的排序二叉树可能会出现失衡的情况,所以下一步就是要进行调整。fixAfterInsertion(e); 调整的过程会涉及到红黑树的左旋、右旋、着色三个基本操作。
EnumMap
EnumMap源自jdk1.5,是一个键为枚举类型的Map,内部使用数组来实现的。put方法通过key的ordinal将值存储到对应的地方,get方法则根据key的ordinal获取对应的值。遍历时,通过hasNext跳过空的数组,也就是说,保证了遍历顺序与Enum中key的先后顺序一致。
EnumMap主要解决在使用枚举数组时的问题,封装了用序数索引数组的操作,运行速度基本和序数索引数组相同,但更加安全。但非线程安全。
IdentityHashMap
IdentityHashMap源自jdk1.4,内部使用数组实现,transient Object[] table。key的比较的基于引用相等。扩容同样为原数组复制到新数组,扩容后大小为newLength = newCapacity * 2。非线程安全。基于引用相等的特性,常用在序列化、深度复制或者记录对象代理等场景。
并发容器
最下方的一个整块都是java.util.concurrent包里面的类,按照包名我们就可以知道这个包里面的类都是用来处理Java编程中各种并发场景的并发容器,jdk8共提供了4类14个并发容器:
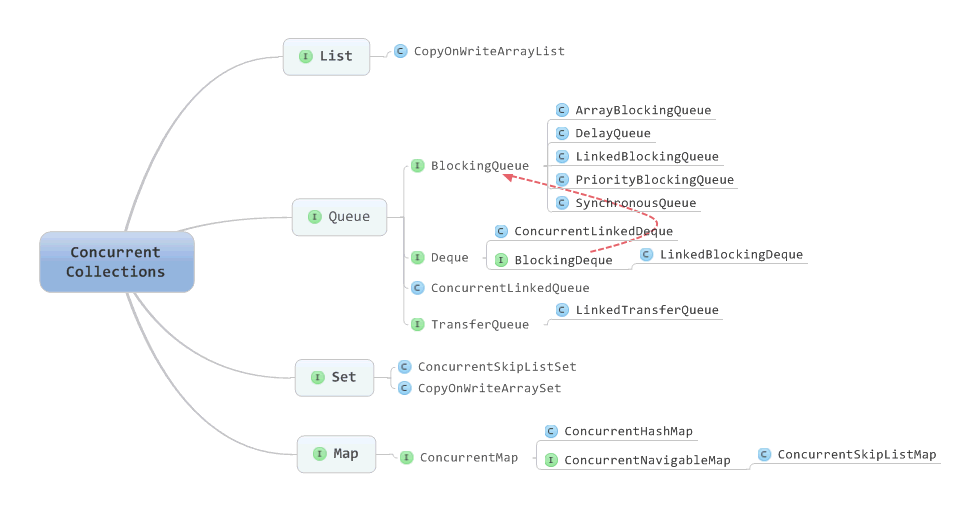
【1】CopyOnWriteArrayList
【1】CopyOnWriteArrayList源自jdk1.5,通常被认为是ArrayList的线程安全变体。
1. 内部由可变数组实现,和ArrayList的区别在于CopyOnWriteArrayList的数组内部均为有效数据。
2. 可变性操作在添加或删除数据的时候,会对数组进行扩容或减容。扩容或减容的过程是:产生新数组,然后将有效数据复制到新数组,这也是“CopyOnWrite”的语义。但复制操作的效率比较低。
3. 每次获取数组都是final类型的,数组引用不可变。同时在add、set、remove、clear、subList、sort等可变性操作内部加锁,保证了数组操作的线程安全性。get操作不加锁。
4. 使用COWIterator进行遍历,内部为CopyOnWriteArrayList的数据数组的final快照,保证了遍历时数据的不变性。不支持remove操作。
5. 综合上述特性,CopyOnWriteArrayList多线程安全,写操作复制和加锁导致效率较低,读操作序号读取效率高,适合使用在多线程、读操作远远大于写操作的场景里,比如缓存。
【2】ArrayBlockingQueue
BlockingQueue源自jdk1.5,在Queue的基础上增加了2个操作:
* put操作,队列满时,存储元素的线程会阻塞,等待队列可用。
* take操作,队列为空时,获取元素的线程会阻塞,等待队列变为非空。
ArrayBlockingQueue是一个用数组实现的有界阻塞队列。
1. 内部有一个ReentrantLock是生产和消费公用的,保证线程安全。
2. 阻塞由两个Condition(notEmpty和notFull)控制。取数据时,队列空,则notEmpty.await();添加数据时,队列满,则notFull.await()。取出数据后,notFull.signal();;添加数据后,notEmpty.signal()。队列元素位置计数由变量takeIndex、putIndex和count控制。
3. 默认情况下不保证访问者公平的访问队列,所谓公平访问队列是指阻塞的所有生产者线程或消费者线程,当队列可用时,可以按照阻塞的先后顺序访问队列,即先阻塞的生产者线程,可以先往队列里插入元素,先阻塞的消费者线程,可以先从队列里获取元素。通常情况下为了保证公平性会降低吞吐量。我们可以使用以下代码创建一个公平的阻塞队列:
ArrayBlockingQueue fairQueue = new ArrayBlockingQueue(1000,true);
【3】LinkedBlockingQueue
LinkedBlockingQueue源自jdk1.5:
1. 利用链表实现的有界阻塞队列,默认和最大长度为Integer.MAX_VALUE。
2. 生产和消费使用不同的锁(ReentrantLock takeLock和ReentrantLock putLock),对于put和offer采用一把锁,对于take和poll则采用另外一把锁,避免了读写时互相竞争锁的情况,分离了读写线程安全,因此LinkedBlockingQueue在高并发读写操作都多的情况下,性能会较ArrayBlockingQueue好很多,在遍历以及删除元素则要两把锁都锁住。
3. 阻塞由两个Condition(notEmpty和notFull)控制。队列元素位置计数由变量(AtomicInteger count)控制。
put操作,在putLock锁内,若队列满,则阻塞notFull.await(),该阻塞在队列不满时由notFull.signal()唤醒。
take操作,在takeLock锁内,若队列空,则阻塞notEmpty.await(),该阻塞在队列非空时由notEmpty.signal()唤醒。
offer是无阻塞的enqueue或时间范围内阻塞enqueue,poll是无阻塞的dequeue或时间范围内阻塞dequeue。
【4】DelayQueue
【4】DelayQueue源自jdk1.5,是一个支持延时获取元素的无界阻塞队列。
1. 队列使用PriorityQueue来实现,优先队列的比较基准值是时间。
2. 队列中的元素必须实现Delayed接口,Delayed扩展了Comparable接口,比较的基准为延时的时间值,Delayed接口的实现类getDelay的返回值应为固定值(final)。在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。
3. 具体实现为:当调用DelayQueue的offer方法时,把Delayed对象加入到优先队列中。DelayQueue的take方法,把优先队列的first拿出来(peek),如果没有达到延时阀值,则进行await处理。
4. 我们可以将DelayQueue运用在以下应用场景:
* 缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。
* 定时任务调度。使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,从比如TimerQueue就是使用DelayQueue实现的。
【5】SynchronousQueue
【5】SynchronousQueue源自jdk1.5,是一个不存储元素的阻塞队列。
1. 每一个put操作必须等待一个take操作,否则不能继续添加元素。SynchronousQueue可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。
2. 可以认为SynchronousQueue是一个缓存值为1的阻塞队列,不能调用peek()方法来看队列中是否有数据元素,因为数据元素只有当你试着取走的时候才可能存在,不取走而只想偷窥一下是不行的,当然遍历这个队列的操作也是不允许的。 isEmpty()方法永远返回是true,remainingCapacity() 方法永远返回是0,remove()和removeAll() 方法永远返回是false,iterator()方法永远返回空,peek()方法永远返回null。
3. 队列本身并不存储任何元素,非常适合于传递性场景,比如在一个线程中使用的数据,传递给另外一个线程使用,SynchronousQueue的吞吐量高于LinkedBlockingQueue 和 ArrayBlockingQueue。
4. SynchronousQueue的一个使用场景是在线程池里。Executors.newCachedThreadPool()就使用了SynchronousQueue,这个线程池根据需要(新任务到来时)创建新的线程,如果有空闲线程则会重复使用,线程空闲了60秒后会被回收。
【6】PriorityBlockingQueue
【6】PriorityBlockingQueue源自jdk1.5,是一个按照优先级排列的阻塞队列:
1. 内部维护一个数组实现的平衡二叉树,里面存储的对象必须实现Comparable接口。队列通过这个接口的compare方法确定对象的优先级。
2. 添加新元素时候不是将全部元素进行顺序排列,而是从某个指定位置开始将新元素与之比较,一直比到队列头,这样既能保证队列头一定是优先级最高的元素。
3. 每取一个头元素时候,都会对剩余的元素做一次调整,这样就能保证每次队列头的元素都是优先级最高的元素。
【7】ConcurrentLinkedDeque
【7】ConcurrentLinkedDeque源自jdk1.7,是一个非阻塞式并发双向无界队列,同时支持FIFO和FILO两种操作方式。
【8】LinkedBlockingDeque
BlockingDeque源自jdk1.6,是一种阻塞式并发双向队列,同时支持FIFO和FILO两种操作方式。所谓双向是指可以从队列的头和尾同时操作,并发只是线程安全的实现,阻塞允许在入队出队不满足条件时挂起线程,这里说的队列是指支持FIFO/FILO实现的链表。
【8】LinkedBlockingDeque源自jdk1.6,
1. 使用链表实现双向并发阻塞队列,根据构造传入的容量大小决定有界还是无界,默认不传的话,大小Integer.Max。
2. 要想支持阻塞功能,队列的容量一定是固定的,否则无法在入队的时候挂起线程。也就是capacity是final类型的。
3. 既然是双向链表,每一个结点就需要前后两个引用,这样才能将所有元素串联起来,支持双向遍历。也即需要prev/next两个引用。
4. 双向链表需要头尾同时操作,所以需要first/last两个节点,当然可以参考LinkedList那样采用一个节点的双向来完成,那样实现起来就稍微麻烦点。
5. 既然要支持阻塞功能,就需要锁和条件变量来挂起线程。这里使用一个锁两个条件变量来完成此功能。
6. 由于采用一个独占锁,因此实现起来也比较简单。所有对队列的操作都加锁就可以完成。同时独占锁也能够很好的支持双向阻塞的特性。但由于独占锁,所以不能同时进行两个操作,这样性能上就大打折扣。从性能的角度讲LinkedBlockingDeque要比LinkedBlockingQueue要低很多,比CocurrentLinkedQueue就低更多了,这在高并发情况下就比较明显了。
【9】ConcurrentLinkedQueue
【9】ConcurrentLinkedQueue源自jdk1.5,是一种非阻塞式并发链表。
1. 采用先进先出的规则对节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部,当我们获取一个元素时,它会返回队列头部的元素。
2. 由head节点和tair节点组成,每个节点(Node)由节点元素(item)和指向下一个节点的引用(next)组成,节点与节点之间就是通过这个next关联起来,从而组成一张链表结构的队列。默认情况下head节点存储的元素为空,tair节点等于head节点。
3. 使用的wait-free算法解决并发问题。
【10】LinkedTransferQueue
TransferQueue源自jdk1.7,是一种BlockingQueue,增加了transfer相关的方法。transfer的语义是,生产者会一直阻塞直到transfer到队列的元素被某一个消费者所消费(不仅仅是添加到队列里就完事)。使用put时不等待消费者消费。
【10】LinkedTransferQueue
1. 采用的一种预占模式。意思就是消费者线程取元素时,如果队列为空,那就生成一个节点(节点元素为null)入队,然后消费者线程park住,后面生产者线程入队时发现有一个元素为null的节点,生产者线程就不入队了,直接就将元素填充到该节点,唤醒该节点上park住线程,被唤醒的消费者线程拿货走人。
2. 使用链表实现TransferQueue接口。
【11】CopyOnWriteArraySet
【11】CopyOnWriteArraySet源自jdk1.5,
1. 内部持有一个CopyOnWriteArrayList引用。
2. 所有操作都是基于对CopyOnWriteArrayList的操作。
【12】ConcurrentSkipListSet
【12】ConcurrentSkipListSet源自jdk1.6,
1. 内部持有ConcurrentSkipListMap。
2. Set的数据value都被封装成< value, Boolean.TRUE>放入ConcurrentSkipListMap。
3. 所有操作都是基于对ConcurrentSkipListMap的操作。
4. 需要注意的是value必须是Comparable类型的。
在jdk5之前,线程安全的Map内置实现只有Hashtable和Properties(注:不考虑Collections.synchronizedMap)。Properties基于Hashtable实现,前面已经讨论过Hashtable,已经过时,现在基本不再使用。jdk5开始,新增加了2个线程安全的Map:ConcurrentHashMap和ConcurrentSkipListMap。
【13】ConcurrentHashMap
【13】ConcurrentHashMap是HashMap的线程安全版本。
**jdk8之前**,ConcurrentHashMap使用锁分段技术,不仅保证了线程安全性,同时提高了并发访问效率。锁分段的原理是:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap实现时,由Segment数组和HashEntry数组组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
**jdk8开始**,ConcurrentHashMap实现线程安全的思想完全改变,摒弃了Segment(锁段)的概念,启用CAS算法实现。它沿用了与它同时期的HashMap版本的思想,底层依然由“数组+链表+红黑树”的方式思想,但是为了做到并发,又增加了很多辅助的类,例如TreeBin、Traverser等内部类。
ConcurrentHashMap实现时,内部维护着一个table,里面存放着Node< K, V>,所有数据都在Node里面。Node和HashMap类型,差别在于Node对value和next属性设置了volatile同步锁,不允许调用setValue方法直接改变Node的value域,它增加了find方法辅助map.get()方法。put操作时,根据Key计算hash值,选择table中相应的Node,然后对Node加synchronized锁,将数据封装到Node中,插入到链表头部。如果该链表长度超过TREEIFY_THRESHOLD,将该链表上所有Node转换成TreeNode,并将该链表转换成TreeBin,由TreeBin完成对红黑树的包装,加入到table中。也就是说在实际的ConcurrentHashMap“数组”中,此位置存放的是TreeBin对象,而不是TreeNode对象,这是与HashMap的区别。
【14】ConcurrentSkipListMap
【14】ConcurrentSkipListMap是TreeMap的线程安全版本,使用CAS算法实现线程安全,适用于多线程情况下对Map的键值进行排序。
对于键值排序需求,非多线程情况下,应当尽量使用TreeMap;对于并发性相对较低的并行程序,可以使用Collections.synchronizedSortedMap将TreeMap进行包装,也可以提供较好的效率。对于高并发程序,应当使用ConcurrentSkipListMap,能够提供更高的并发度。和ConcurrentHashMap相比,ConcurrentSkipListMap 支持更高的并发。ConcurrentSkipListMap 的存取时间是log(N),和线程数几乎无关。也就是说在数据量一定的情况下,并发的线程越多,ConcurrentSkipListMap越能体现出他的优势。
ConcurrentSkipListMap由跳表(Skip list)实现,默认是按照Key值升序的。内部主要由Node和Index组成。同ConcurrentHashMap的Node节点一样,key为final,是不可变的,value和next通过volatile修饰保证内存可见性。Index封装了跳表需要的结构,首先node包装了链表的节点,down指向下一层的节点(不是Node,而是Index),right指向同层右边的节点。node和down都是final的,说明跳表的节点一旦创建,其中的值以及所处的层就不会发生变化(因为down不会变化,所以其下层的down都不会变化,那他的层显然不会变化)。
Skip list是一个"空间来换取时间"的算法:
> 1. 最底层(level1)是已排序的完整链表结构;
> 2. level1上元素以0-1随机数决定是否攀升到level2,同时level2上每个节点中增加了向前的指针;
> 3. level2上元素继续进行随机攀升到level3,并且level3上每个节点中增加了向前的指针。














 1721
1721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









