







来源:juejin.cn/post/7498559283576422411
👉 欢迎加入小哈的星球,你将获得: 专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
新项目:《从零手撸:仿小红书(微服务架构)》 收尾中,基于 Spring Cloud Alibaba + Spring Boot 3.x + JDK 17..., 点击查看项目介绍;演示地址:http://116.62.199.48:7070/
《从零手撸:前后端分离博客项目(全栈开发)》 2期已完结,演示链接:http://116.62.199.48/;
专栏阅读地址:https://www.quanxiaoha.com/column
截止目前,累计输出 90w+ 字,讲解图 3713+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,Spring Cloud Alibaba 等等,戳我加入学习,解锁全部项目,已有3200+小伙伴加入
一、为什么需要批处理?
1. 应用场景解析
场景1:银行每日利息计算
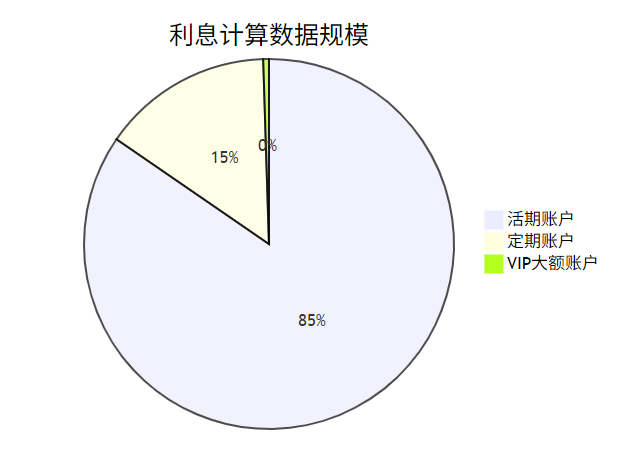
痛点: 凌晨时段需扫描百万级账户数据,手工计算容易遗漏
Spring Batch方案: 分片读取账户数据,批量计算利息,失败自动重试
实际案例: 某银行系统改造后,利息计算时间从4小时缩短至23分钟
场景2:电商订单归档
// 传统SQL示例(存在性能问题)
DELETE FROM active_orders
WHERE create_time < '2023-01-01'
LIMIT 5000; // 需循环执行直到无数据问题: 直接删除百万级数据会导致数据库锁表
正确做法: 使用Spring Batch分页读取→写入历史表→批量删除
场景3:日志分析
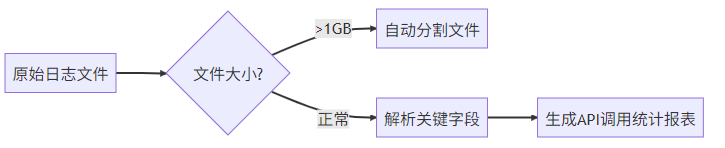
典型需求: 分析Nginx日志中的API响应时间分布
特殊挑战: 处理GB级文本文件时的内存控制
场景4:医疗数据迁移

特殊要求: 迁移过程中老系统仍需正常使用
解决方案: 使用Spring Batch的增量迁移模式
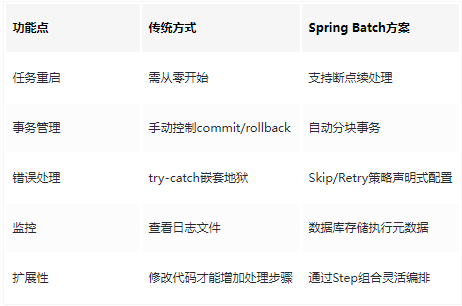
2. 传统方式痛点

详细解释每个痛点:
资源管理复杂
// 典型的多线程错误示例
ExecutorService executor = Executors.newFixedThreadPool(8);
try {
while(hasNextPage()) {
List<Data> page = fetchNextPage();
executor.submit(() -> processPage(page)); // 可能引发内存泄漏
}
} finally {
executor.shutdown(); // 忘记调用会导致线程堆积
}常见问题:线程池配置不当导致OOM、数据库连接泄露
容错性黑洞
// 伪代码:脆弱的错误处理
for (int i=0; i<3; i++) {
try {
processBatch();
break;
} catch (Exception e) {
if (i == 2) sendAlert(); // 简单重试无法处理部分成功场景
}
}真实案例:某支付系统因未处理部分失败,导致重复出款
维护噩梦
# 典型硬编码配置
batch.size=1000
input.path=/data/in
output.path=/data/out问题根源:参数修改需要重新部署、不同环境配置混杂
监控盲区
# 开发人员常用的临时方案
nohup java -jar batch.jar > log.txt 2>&1 &
tail -f log.txt # 无法获知实时进度关键缺陷:无法回答"处理到哪了?"、"还剩多少?"等业务问题
Spring Batch对比优势表
二、Spring Batch核心架构
1. 四大金刚组件深度解析
组件1:Job(作业工厂)

核心作用: 定义完整的批处理流水线(如月度报表生成流程)
真实案例: 某银行的日终对账Job包含三个Step
@Bean
public Job reconciliationJob() {
return jobBuilderFactory.get("dailyReconciliation")
.start(downloadBankFileStep())
.next(validateDataStep())
.next(generateReportStep())
.build();
}组件2:Step(装配流水线)
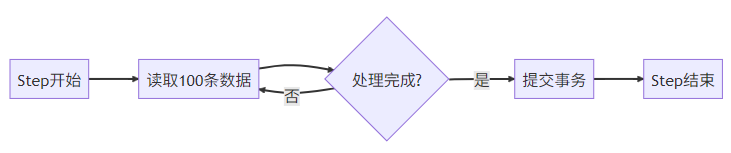
设计模式:采用分块(Chunk)处理机制
配置示例:
@Bean
public Step importStep() {
return stepBuilderFactory.get("csvImport")
.<User, User>chunk(500) // 每500条提交一次
.reader(csvReader())
.processor(validationProcessor())
.writer(dbWriter())
.faultTolerant()
.skipLimit(10)
.skip(DataIntegrityViolationException.class)
.build();
}组件3:ItemReader(数据搬运工)
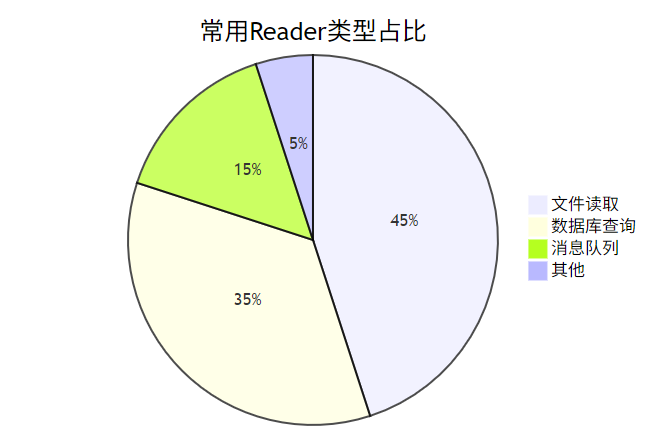
典型实现:
// 读取CSV文件示例
@Bean
public FlatFileItemReader<User> csvReader() {
return new FlatFileItemReaderBuilder<User>()
.name("userReader")
.resource(new FileSystemResource("data/users.csv"))
.delimited().delimiter(",")
.names("id", "name", "email")
.fieldSetMapper(new BeanWrapperFieldSetMapper<User>() {{
setTargetType(User.class);
}})
.linesToSkip(1) // 跳过标题行
.build();
}组件4:ItemWriter(数据收纳师)
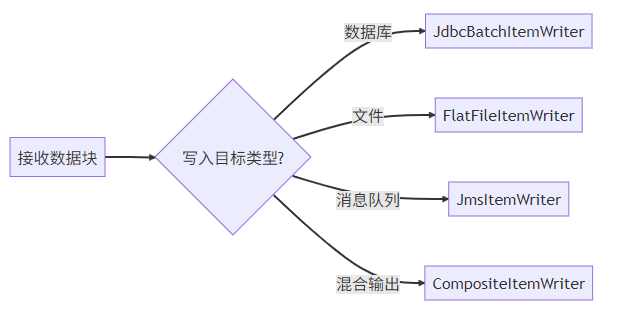
复合写入示例:
@Bean
public CompositeItemWriter<User> compositeWriter() {
returnnew CompositeItemWriterBuilder<User>()
.delegates(dbWriter(), logWriter(), mqWriter())
.build();
}
// 数据库写入组件
private JdbcBatchItemWriter<User> dbWriter() {
returnnew JdbcBatchItemWriterBuilder<User>()
.dataSource(dataSource)
.sql("INSERT INTO users (name,email) VALUES (:name,:email)")
.beanMapped()
.build();
}2. 架构示意图

3. 隐藏BOSS:ItemProcessor(数据变形金刚)

典型应用:数据脱敏处理
public class DataMaskProcessor implements ItemProcessor<User, User> {
@Override
public User process(User user) {
// 手机号脱敏
String phone = user.getPhone();
user.setPhone(phone.replaceAll("(\\d{3})\\d{4}(\\d{4})", "$1****$2"));
// 邮箱转小写
user.setEmail(user.getEmail().toLowerCase());
return user;
}
}4. 组件生命周期探秘
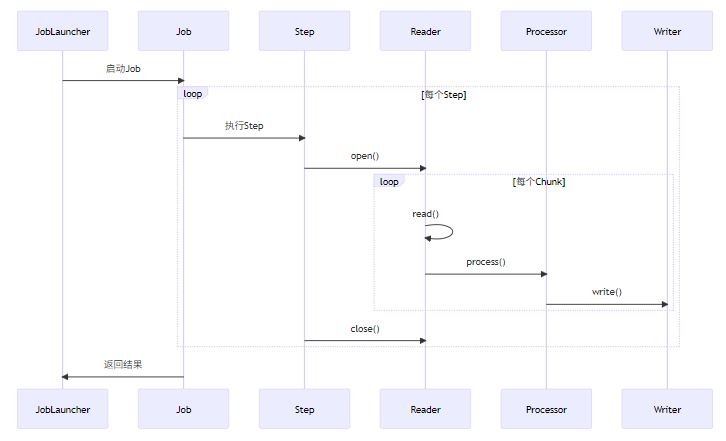
三、手把手开发指南
1. 环境搭建
<!-- 完整POM配置 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.1.5</version>
</parent>
<dependencies>
<!-- Batch核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<!-- 内存数据库(生产环境可更换为MySQL等) -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Lombok简化代码 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
# application.properties
spring.batch.jdbc.initialize-schema=always # 自动创建Batch元数据表
spring.datasource.url=jdbc:h2:mem:testdb
spring.datasource.driverClassName=org.h2.Driver2. 第一个批处理任务
领域模型类:
@Data // Lombok注解
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String name;
private int age;
private String email;
}完整Job配置:
@Configuration
@EnableBatchProcessing
publicclass BatchConfig {
@Autowiredprivate JobBuilderFactory jobBuilderFactory;
@Autowiredprivate StepBuilderFactory stepBuilderFactory;
// 定义Job
@Bean
public Job importUserJob() {
return jobBuilderFactory.get("importUserJob")
.start(csvProcessingStep())
.build();
}
// 定义Step
@Bean
public Step csvProcessingStep() {
return stepBuilderFactory.get("csvProcessing")
.<User, User>chunk(100) // 每处理100条提交一次
.reader(userReader())
.processor(userProcessor())
.writer(userWriter())
.build();
}
// CSV文件读取器
@Bean
public FlatFileItemReader<User> userReader() {
returnnew FlatFileItemReaderBuilder<User>()
.name("userReader")
.resource(new ClassPathResource("users.csv")) // 文件路径
.delimited()
.delimiter(",")
.names("name", "age", "email") // 字段映射
.targetType(User.class)
.linesToSkip(1) // 跳过标题行
.build();
}
// 数据处理(示例:年龄校验)
@Bean
public ItemProcessor<User, User> userProcessor() {
return user -> {
if (user.getAge() < 0) {
thrownew IllegalArgumentException("年龄不能为负数: " + user);
}
return user.toBuilder() // 使用Builder模式创建新对象
.email(user.getEmail().toLowerCase())
.build();
};
}
// 数据库写入器
@Bean
public JdbcBatchItemWriter<User> userWriter(DataSource dataSource) {
returnnew JdbcBatchItemWriterBuilder<User>()
.dataSource(dataSource)
.sql("INSERT INTO users (name, age, email) VALUES (:name, :age, :email)")
.beanMapped()
.build();
}
}CSV文件示例(
src/main/resources/users.csv):
name,age,email
张三,25,zhangsan@example.com
李四,30,lisi@example.com
王五,-5,wangwu@example.com启动类:
@SpringBootApplication
publicclass BatchApplication implements CommandLineRunner {
@Autowired
private JobLauncher jobLauncher;
@Autowired
private Job importUserJob;
public static void main(String[] args) {
SpringApplication.run(BatchApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
JobParameters params = new JobParametersBuilder()
.addLong("startAt", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(importUserJob, params);
}
}3. 执行流程可视化
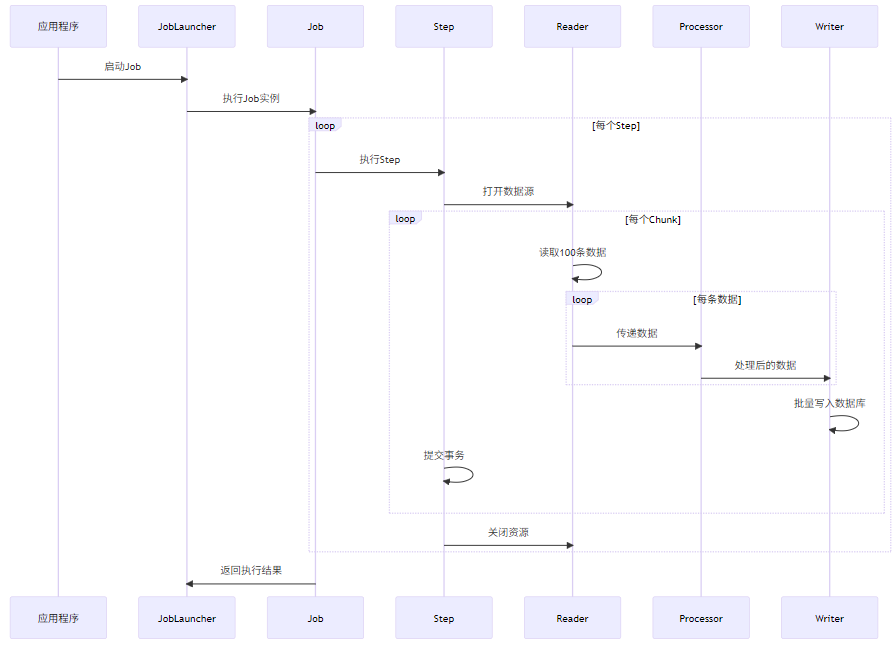
4. 运行效果验证
控制台输出:
2023-10-01 10:00:00 INFO o.s.b.c.l.support.SimpleJobLauncher - Job: [SimpleJob: [name=importUserJob]] launched
2023-10-01 10:00:05 INFO o.s.batch.core.job.SimpleStepHandler - Executing step: [csvProcessing]
2023-10-01 10:00:15 ERROR o.s.batch.core.step.AbstractStep - Encountered an error executing step csvProcessing
org.springframework.batch.item.validator.ValidationException: 年龄不能为负数: User(name=王五, age=-5, email=wangwu@example.com)数据库结果:
SELECT * FROM users;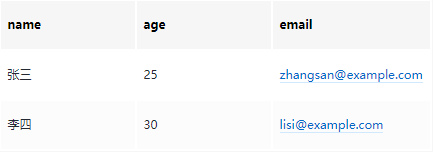
5. 调试技巧
查看元数据:
SELECT * FROM BATCH_JOB_INSTANCE;
SELECT * FROM BATCH_STEP_EXECUTION;重试失败任务:
// 在Job配置中添加容错机制
@Bean
public Step csvProcessingStep() {
return stepBuilderFactory.get("csvProcessing")
.<User, User>chunk(100)
.reader(userReader())
.processor(userProcessor())
.writer(userWriter())
.faultTolerant()
.skipLimit(3) // 最多跳过3条错误
.skip(IllegalArgumentException.class)
.build();
}日志监控配置:
logging.level.org.springframework.batch=DEBUG
logging.level.org.hibernate.SQL=WARN四、实战案例:银行交易对账
1. 场景需求增强说明
核心流程:
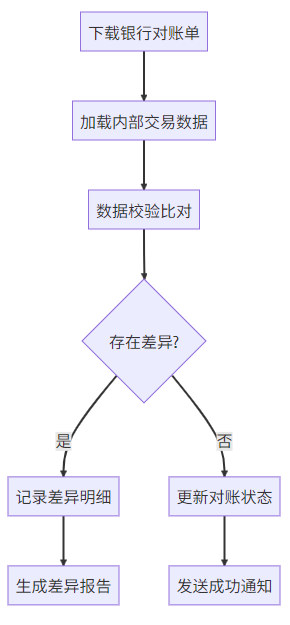
技术挑战:
双数据源读取(文件+数据库)
千万级数据高效比对
差异记录快速入库
分布式环境运行
2. 完整架构设计
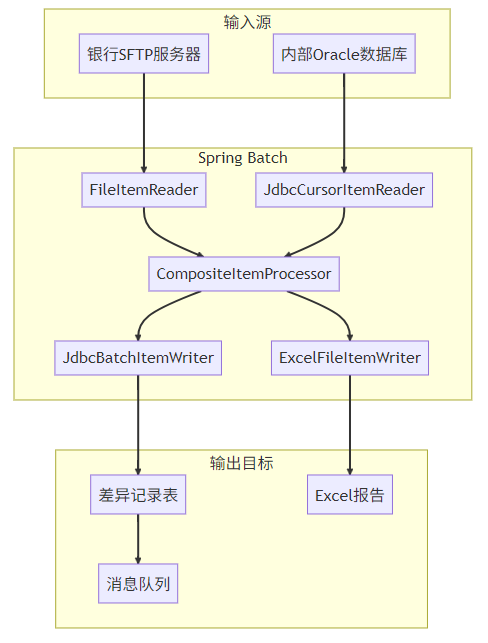
3. 领域模型定义
@Data
@AllArgsConstructor
@NoArgsConstructor
publicclass Transaction {
// 公共字段
private String transactionId;
private LocalDateTime tradeTime;
private BigDecimal amount;
// 银行端数据
private String bankSerialNo;
private BigDecimal bankAmount;
// 内部系统数据
private String internalOrderNo;
private BigDecimal systemAmount;
// 对账结果
private ReconStatus status;
private String discrepancyType;
}
publicenum ReconStatus {
MATCHED, // 数据一致
AMOUNT_DIFF, // 金额不一致
STATUS_DIFF, // 状态不一致
ONLY_IN_BANK, // 银行单边账
ONLY_IN_SYSTEM // 系统单边账
}4. 完整Job配置
@Configuration
@EnableBatchProcessing
publicclass BankReconJobConfig {
// 主Job定义
@Bean
public Job bankReconciliationJob(Step downloadStep, Step reconStep, Step reportStep) {
return jobBuilderFactory.get("bankReconciliationJob")
.start(downloadStep)
.next(reconStep)
.next(reportStep)
.build();
}
// 文件下载Step
@Bean
public Step downloadStep() {
return stepBuilderFactory.get("downloadStep")
.tasklet((contribution, chunkContext) -> {
// 实现SFTP下载逻辑
sftpService.download("/bank/recon/20231001.csv");
return RepeatStatus.FINISHED;
})
.build();
}
// 核心对账Step
@Bean
public Step reconStep() {
return stepBuilderFactory.get("reconStep")
.<Transaction, Transaction>chunk(1000)
.reader(compositeReader())
.processor(compositeProcessor())
.writer(compositeWriter())
.faultTolerant()
.skipLimit(100)
.skip(DataIntegrityViolationException.class)
.retryLimit(3)
.retry(DeadlockLoserDataAccessException.class)
.build();
}
// 组合数据读取器
@Bean
public CompositeItemReader<Transaction> compositeReader() {
returnnew CompositeItemReaderBuilder<Transaction>()
.delegates(bankFileReader(), internalDbReader())
.build();
}
// 银行文件读取器
@Bean
public FlatFileItemReader<Transaction> bankFileReader() {
returnnew FlatFileItemReaderBuilder<Transaction>()
.name("bankFileReader")
.resource(new FileSystemResource("recon/20231001.csv"))
.delimited()
.names("transactionId","tradeTime","amount","bankSerialNo")
.fieldSetMapper(fieldSet -> {
Transaction t = new Transaction();
t.setTransactionId(fieldSet.readString("transactionId"));
t.setBankSerialNo(fieldSet.readString("bankSerialNo"));
t.setBankAmount(fieldSet.readBigDecimal("amount"));
return t;
})
.build();
}
// 内部数据库读取器
@Bean
public JdbcCursorItemReader<Transaction> internalDbReader() {
returnnew JdbcCursorItemReaderBuilder<Transaction>()
.name("internalDbReader")
.dataSource(internalDataSource)
.sql("SELECT order_no, amount, status FROM transactions WHERE trade_date = ?")
.rowMapper((rs, rowNum) -> {
Transaction t = new Transaction();
t.setInternalOrderNo(rs.getString("order_no"));
t.setSystemAmount(rs.getBigDecimal("amount"));
return t;
})
.preparedStatementSetter(ps -> ps.setString(1, "2023-10-01"))
.build();
}
// 组合处理器
@Bean
public CompositeItemProcessor<Transaction> compositeProcessor() {
List<ItemProcessor<?, ?>> delegates = new ArrayList<>();
delegates.add(new DataMatchingProcessor());
delegates.add(new DiscrepancyClassifier());
returnnew CompositeItemProcessorBuilder<>()
.delegates(delegates)
.build();
}
// 组合写入器
@Bean
public CompositeItemWriter<Transaction> compositeWriter() {
returnnew CompositeItemWriterBuilder<Transaction>()
.delegates(
discrepancyDbWriter(),
alertMessageWriter()
)
.build();
}
}5. 核心处理器实现
public class DataMatchingProcessor implements ItemProcessor<Transaction, Transaction> {
@Override
public Transaction process(Transaction item) {
// 双数据源匹配逻辑
if (item.getBankSerialNo() == null) {
item.setStatus(ReconStatus.ONLY_IN_SYSTEM);
} elseif (item.getInternalOrderNo() == null) {
item.setStatus(ReconStatus.ONLY_IN_BANK);
} else {
compareAmounts(item);
compareStatuses(item);
}
return item;
}
private void compareAmounts(Transaction t) {
if (t.getBankAmount().compareTo(t.getSystemAmount()) != 0) {
t.setDiscrepancyType("AMOUNT_MISMATCH");
t.setStatus(ReconStatus.AMOUNT_DIFF);
BigDecimal diff = t.getBankAmount().subtract(t.getSystemAmount());
t.setAmount(diff.abs());
}
}
private void compareStatuses(Transaction t) {
// 假设从数据库获取内部状态
String internalStatus = transactionService.getStatus(t.getInternalOrderNo());
if(!"SETTLED".equals(internalStatus)){
t.setDiscrepancyType("STATUS_MISMATCH");
t.setStatus(ReconStatus.STATUS_DIFF);
}
}
}
publicclass DiscrepancyClassifier implements ItemProcessor<Transaction, Transaction> {
@Override
public Transaction process(Transaction item) {
if (item.getStatus() != ReconStatus.MATCHED) {
// 添加告警标记
item.setAlertLevel(calculateAlertLevel(item));
}
return item;
}
private AlertLevel calculateAlertLevel(Transaction t) {
if (t.getAmount().compareTo(new BigDecimal("1000000")) > 0) {
return AlertLevel.CRITICAL;
}
return AlertLevel.WARNING;
}
}6. 差异报告生成Step
@Bean
public Step reportStep() {
return stepBuilderFactory.get("reportStep")
.<Transaction, Transaction>chunk(1000)
.reader(discrepancyReader())
.writer(excelWriter())
.build();
}
@Bean
public JdbcPagingItemReader<Transaction> discrepancyReader() {
returnnew JdbcPagingItemReaderBuilder<Transaction>()
.name("discrepancyReader")
.dataSource(reconDataSource)
.selectClause("SELECT *")
.fromClause("FROM discrepancy_records")
.whereClause("WHERE recon_date = '2023-10-01'")
.sortKeys(Collections.singletonMap("transaction_id", Order.ASCENDING))
.rowMapper(new BeanPropertyRowMapper<>(Transaction.class))
.build();
}
@Bean
public ExcelFileItemWriter<Transaction> excelWriter() {
returnnew ExcelFileItemWriterBuilder<Transaction>()
.name("excelWriter")
.resource(new FileSystemResource("reports/2023-10-01.xlsx"))
.sheetName("差异报告")
.headers(new String[]{"交易ID", "差异类型", "金额差异", "告警级别"})
.fieldExtractor(item -> new Object[]{
item.getTransactionId(),
item.getDiscrepancyType(),
item.getAmount(),
item.getAlertLevel()
})
.build();
}7. 性能优化配置
# 应用配置
spring.batch.job.enabled=false # 禁止自动启动
spring.batch.initialize-schema=never # 生产环境禁止自动建表
# 性能调优参数
spring.batch.chunk.size=2000 # 根据内存调整
spring.datasource.hikari.maximum-pool-size=20
spring.jpa.properties.hibernate.jdbc.batch_size=10008. 执行监控看板

五、生产级特性
1. 容错机制
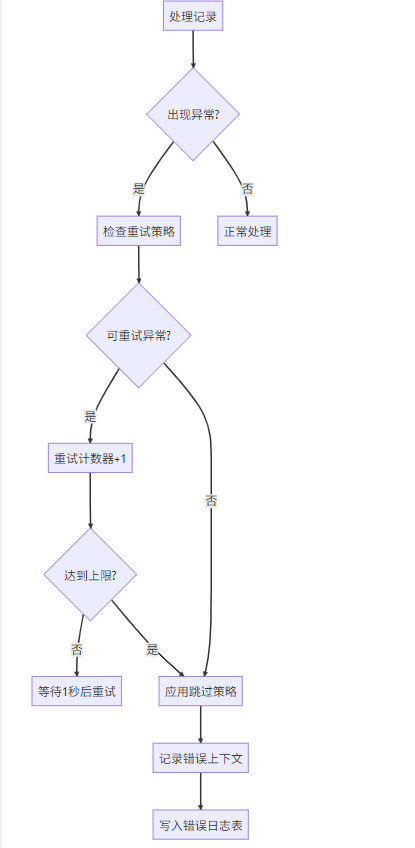
完整容错配置示例:
@Bean
public Step secureStep() {
return stepBuilderFactory.get("secureStep")
.<Input, Output>chunk(500)
.reader(jdbcReader())
.processor(secureProcessor())
.writer(restApiWriter())
.faultTolerant()
.retryLimit(3)
.retry(ConnectException.class) // 网络问题重试
.retry(DeadlockLoserDataAccessException.class) // 数据库死锁重试
.skipLimit(100)
.skip(DataIntegrityViolationException.class) // 数据问题跳过
.skip(InvalidDataAccessApiUsageException.class)
.noRollback(ValidationException.class) // 验证异常不回滚
.listener(new ErrorLogListener()) // 自定义监听器
.build();
}
// 错误日志监听器示例
publicclass ErrorLogListener implements ItemProcessListener<Input, Output> {
@Override
public void onProcessError(Input item, Exception e) {
ErrorLog log = new ErrorLog();
log.setItemData(item.toString());
log.setErrorMsg(e.getMessage());
errorLogRepository.save(log);
}
}2. 性能优化策略(千万级数据处理)
策略1:并行Step执行
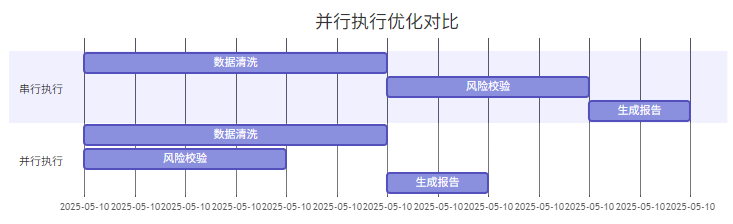
配置代码:
@Bean
public Job parallelJob() {
return jobBuilderFactory.get("parallelJob")
.start(step1())
.split(new SimpleAsyncTaskExecutor()) // 启用异步执行器
.add(step2(), step3())
.build();
}策略2:分区处理(Partitioning)
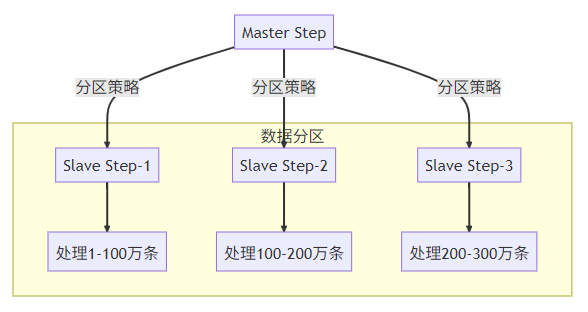
分区处理器实现:
@Bean
public Step masterStep() {
return stepBuilderFactory.get("masterStep")
.partitioner("slaveStep", partitioner())
.gridSize(10) // 分区数量=CPU核心数*2
.taskExecutor(new ThreadPoolTaskExecutor())
.build();
}
@Bean
public Partitioner partitioner() {
returnnew Partitioner() {
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> result = new HashMap<>();
long total = getTotalRecordCount();
long range = total / gridSize;
for (int i = 0; i < gridSize; i++) {
ExecutionContext context = new ExecutionContext();
context.putLong("min", i * range);
context.putLong("max", (i+1) * range);
result.put("partition"+i, context);
}
return result;
}
};
}
// Slave Step配置
@Bean
public Step slaveStep() {
return stepBuilderFactory.get("slaveStep")
.<Record, Result>chunk(1000)
.reader(rangeReader(null, null))
.processor(processor())
.writer(writer())
.build();
}
@StepScope
@Bean
public ItemReader<Record> rangeReader(
@Value("#{stepExecutionContext[min]}") Long min,
@Value("#{stepExecutionContext[max]}") Long max) {
returnnew JdbcCursorItemReaderBuilder<Record>()
.sql("SELECT * FROM records WHERE id BETWEEN ? AND ?")
.preparedStatementSetter(ps -> {
ps.setLong(1, min);
ps.setLong(2, max);
})
// 其他配置...
.build();
}策略3:异步ItemProcessor
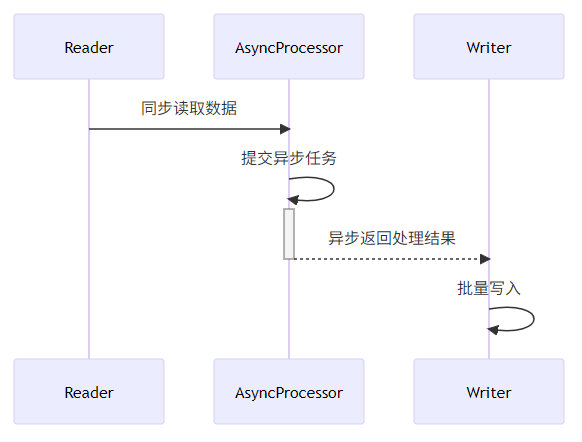
异步处理配置:
@Bean
public Step asyncStep() {
return stepBuilderFactory.get("asyncStep")
.<Input, Output>chunk(1000)
.reader(reader())
.processor(asyncItemProcessor())
.writer(writer())
.build();
}
@Bean
public AsyncItemProcessor<Input, Output> asyncItemProcessor() {
AsyncItemProcessor<Input, Output> asyncProcessor = new AsyncItemProcessor<>();
asyncProcessor.setDelegate(syncProcessor()); // 同步处理器
asyncProcessor.setTaskExecutor(new ThreadPoolTaskExecutor());
return asyncProcessor;
}
@Bean
public AsyncItemWriter<Output> asyncItemWriter() {
AsyncItemWriter<Output> asyncWriter = new AsyncItemWriter<>();
asyncWriter.setDelegate(syncWriter()); // 同步写入器
return asyncWriter;
}3. 性能对比测试数据
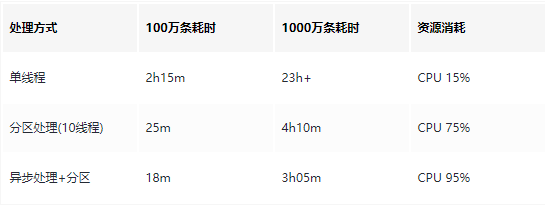
优化技巧:
数据库连接池调优:
spring.datasource.hikari.maximum-pool-size=20
spring.datasource.hikari.minimum-idle=5JVM参数优化:
java -jar -Xmx4g -XX:+UseG1GC -XX:MaxGCPauseMillis=200 ...批处理参数调整:
.chunk(2000) // 根据内存容量调整
.setQueryTimeout(60) // 数据库查询超时六、监控与管理(生产级方案)
1. 监控方案升级(Spring Batch Admin替代方案)
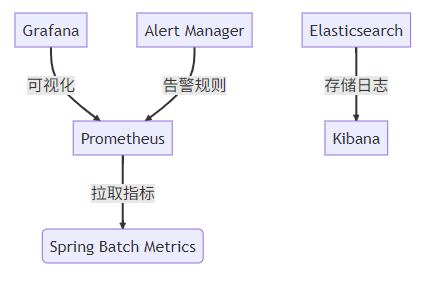
现代监控栈配置:
// 添加监控依赖
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
// 暴露监控端点
@Bean
public MeterRegistryCustomizer<MeterRegistry> metricsCommonTags() {
return registry -> registry.config().commonTags("application", "batch-service");
}
// 自定义Batch指标
publicclass BatchMetricsListener extends JobExecutionListenerSupport {
privatefinal Counter processedRecords = Counter.builder("batch.records.processed")
.description("Total processed records")
.register(Metrics.globalRegistry);
@Override
public void afterStep(StepExecution stepExecution) {
processedRecords.increment(stepExecution.getWriteCount());
}
}2. 元数据表结构详解
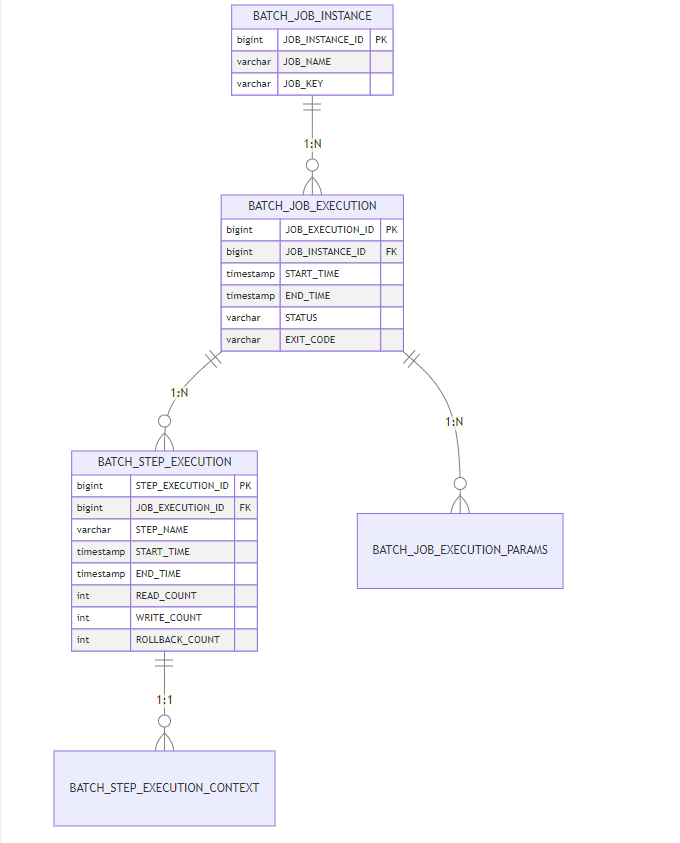
关键表用途:
BATCH_JOB_INSTANCE:作业指纹库(相同参数只能存在一个实例)BATCH_JOB_EXECUTION_PARAMS:存储每次运行的参数BATCH_STEP_EXECUTION_CONTEXT:保存步骤上下文数据(重启恢复的关键)
3. 自定义监控看板
-- 常用监控SQL示例
-- 最近5次作业执行情况
SELECT j.JOB_NAME, e.START_TIME, e.END_TIME,
TIMEDIFF(e.END_TIME, e.START_TIME) AS DURATION,
s.READ_COUNT, s.WRITE_COUNT
FROM BATCH_JOB_EXECUTION e
JOIN BATCH_JOB_INSTANCE j ON e.JOB_INSTANCE_ID = j.JOB_INSTANCE_ID
JOIN BATCH_STEP_EXECUTION s ON e.JOB_EXECUTION_ID = s.JOB_EXECUTION_ID
ORDER BY e.START_TIME DESC LIMIT 5;七、常见问题Q&A(终极指南)
1. 内存溢出问题深度解决方案
场景:处理10GB CSV文件时OOM
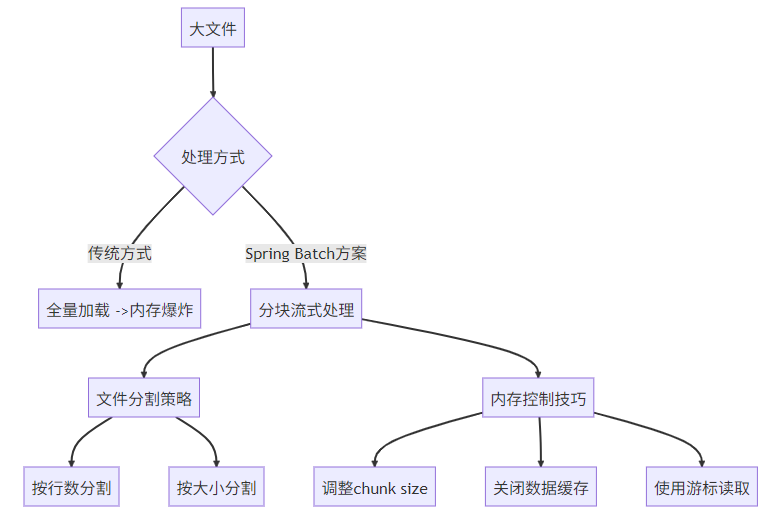
优化代码示例:
@Bean
@StepScope
public FlatFileItemReader<LargeRecord> largeFileReader(
@Value("#{jobParameters['filePath']}") String filePath) {
returnnew FlatFileItemReaderBuilder<LargeRecord>()
.resource(new FileSystemResource(filePath))
.lineMapper(new DefaultLineMapper<>() {{
setLineTokenizer(new DelimitedLineTokenizer());
setFieldSetMapper(new BeanWrapperFieldSetMapper<>() {{
setTargetType(LargeRecord.class);
}});
}})
.linesToSkip(1)
.strict(false) // 允许文件结尾空行
.saveState(false) // 禁用状态保存
.build();
}
// JVM参数建议
// -XX:+UseG1GC -Xmx2g -XX:MaxGCPauseMillis=2002. 定时任务高级配置
多任务调度方案:
@Configuration
@EnableScheduling
publicclass ScheduleConfig {
@Autowiredprivate JobLauncher jobLauncher;
@Autowiredprivate Job reportJob;
// 工作日凌晨执行
@Scheduled(cron = "0 0 2 * * MON-FRI")
public void dailyJob() throws Exception {
JobParameters params = new JobParametersBuilder()
.addString("date", LocalDate.now().toString())
.toJobParameters();
jobLauncher.run(reportJob, params);
}
// 每小时轮询
@Scheduled(fixedRate = 3600000)
public void pollJob() {
if(checkNewDataExists()) {
jobLauncher.run(dataProcessJob, new JobParameters());
}
}
// 优雅停止示例
public void stopJob(Long executionId) {
JobExecution execution = jobExplorer.getJobExecution(executionId);
if(execution.isRunning()) {
execution.setStatus(BatchStatus.STOPPING);
jobRepository.update(execution);
}
}
}3. 高频问题集锦
Q:如何重新运行失败的任务?
-- 步骤1:查询失败的任务ID
SELECT * FROM BATCH_JOB_EXECUTION WHERE STATUS = 'FAILED';
-- 步骤2:使用相同参数重新启动
JobParameters params = new JobParametersBuilder()
.addLong("restartId", originalExecutionId)
.toJobParameters();
jobLauncher.run(job, params);Q:处理过程中断电怎么办?
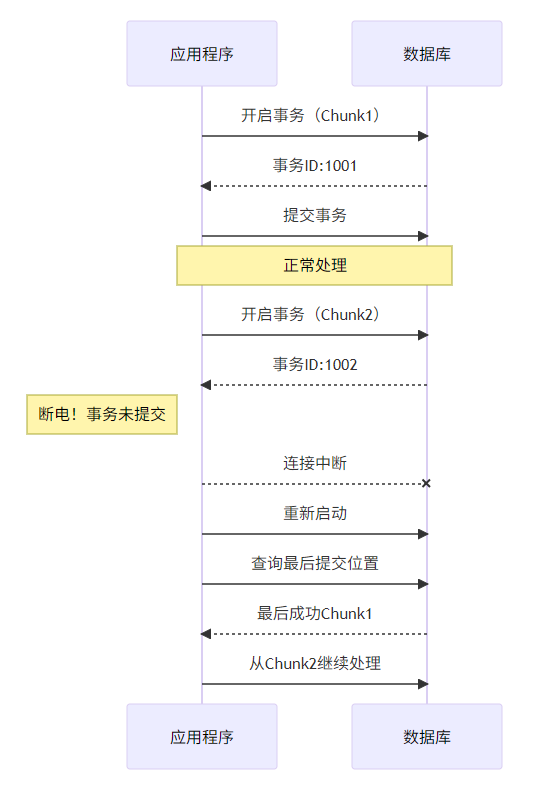
Q:如何实现动态参数传递?
// 命令行启动方式
java -jar batch.jar --spring.batch.job.name=dataImportJob date=2023-10-01
// 编程式参数构建
public void runJobWithParams(Map<String, Object> params) {
JobParameters jobParams = new JobParametersBuilder()
.addString("mode", "forceUpdate")
.addLong("timestamp", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(importJob, jobParams);
}4. 性能调优检查清单
数据库优化
添加批量处理索引
配置连接池参数
启用JDBC批处理模式
JVM优化
-XX:+UseStringDeduplication
-XX:+UseCompressedOops
-XX:MaxMetaspaceSize=512mBatch配置
spring.batch.jdbc.initialize-schema=never
spring.batch.job.enabled=false
spring.jpa.open-in-view=false👉 欢迎加入小哈的星球,你将获得: 专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
新项目:《从零手撸:仿小红书(微服务架构)》 收尾中,基于 Spring Cloud Alibaba + Spring Boot 3.x + JDK 17..., 点击查看项目介绍;演示地址:http://116.62.199.48:7070/
《从零手撸:前后端分离博客项目(全栈开发)》 2期已完结,演示链接:http://116.62.199.48/;
专栏阅读地址:https://www.quanxiaoha.com/column
截止目前,累计输出 90w+ 字,讲解图 3713+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,Spring Cloud Alibaba 等等,戳我加入学习,解锁全部项目,已有3200+小伙伴加入

1. 我的私密学习小圈子,从0到1手撸企业实战项目~ 2. 求求你们别再用 kill -9 了,这才是 Spring Boot 停机的正确方式!!! 3. Elasticsearch 最佳生产实践,推荐收藏! 4. 美团一面:为什么线程崩溃崩溃不会导致 JVM 崩溃

最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。 获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。PS:因公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。 点“在看”支持小哈呀,谢谢啦

















 720
720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









