






👉 欢迎加入小哈的星球,你将获得: 专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
新项目:《从零手撸:仿小红书(微服务架构)》 已完结,基于 Spring Cloud Alibaba + Spring Boot 3.x + JDK 17..., 点击查看项目介绍;演示地址:http://116.62.199.48:7070/
《从零手撸:前后端分离博客项目(全栈开发)》 2期已完结,演示链接:http://116.62.199.48/;
专栏阅读地址:https://www.quanxiaoha.com/column
截止目前,累计输出 90w+ 字,讲解图 3713+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,Spring Cloud Alibaba 等等,戳我加入学习,解锁全部项目,已有3300+小伙伴加入

这个问题看起来挺常见的,但是非常考验面试者的综合经验和综合技术能力,以及逻辑语言的组织思维。
首先,系统变慢可能有很多原因,比如CPU、内存、磁盘I/O、网络或者应用程序本身的问题。
所以应该从这些方面入手,逐一排查。不过具体步骤该怎么安排呢?
可能应该先检查整体的资源使用情况,然后根据哪个指标异常再深入分析。
比如,先看看CPU使用率是不是很高,如果CPU很高,可能是某个进程占用了太多资源。
这时候可以用top或者htop这样的工具来查看进程的CPU占用情况。
找到占用高的进程后,再进一步分析,比如用strace或者perf来查看系统调用或者性能瓶颈。
当系统突然变慢时,可以按照以下步骤逐步排查问题,结合工具快速定位瓶颈:
整体资源监控(快速定位瓶颈方向)
工具:
top、htop、vmstat、dstatLoad Average:1/5/15分钟负载。若负载值接近或超过CPU核心数,说明系统过载。
%CPU:用户态(us)、内核态(sy)、I/O等待(wa)。若
wa高,可能是磁盘瓶颈。%MEM 和 Swap:内存不足时,
si/so(swap in/out)会频繁变化。
运行
top,观察:vmstat 1:查看上下文切换(cs)、内存交换(si/so)、磁盘块读写(bi/bo)等实时指标。
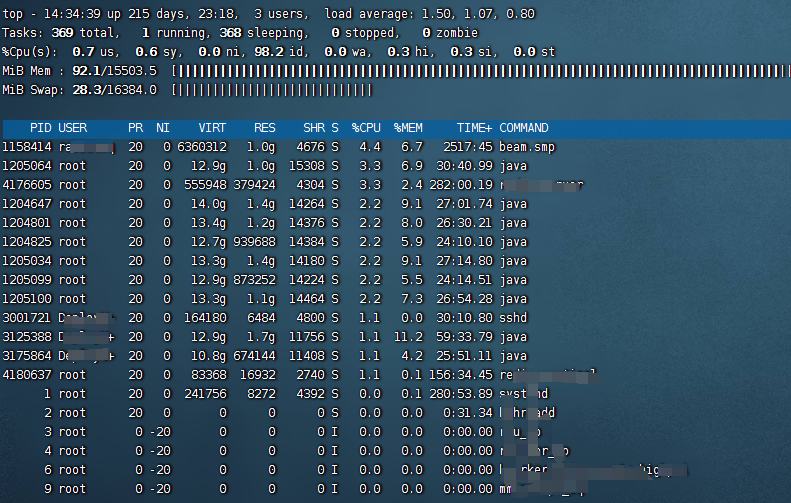
如果是内存的问题,比如内存不足导致swap频繁使用,系统就会变慢。
这时候可以用free -h或者vmstat来查看内存使用情况,特别是swap的使用情况。
如果发现内存不够,可能需要优化程序的内存使用,或者增加内存。
当系统突然变慢时,可以按照以下步骤逐步排查问题,结合工具快速定位瓶颈:
内存瓶颈
确认内存使用:
free -h:查看物理内存和Swap使用,若available极低,可能触发OOM。vmstat 1:观察si/so,频繁交换会导致性能下降。
分析内存泄漏:
pmap -x <PID>:查看进程内存映射。Java应用用
jmap -heap <PID>或jstat -gcutil <PID>观察GC情况。工具:
Valgrind(C/C++)、MAT(Java堆分析)。

磁盘I/O也是一个常见的问题,特别是当有大量读写操作时。可以用iostat或者iotop来监控磁盘的I/O情况,看看是否有进程在频繁读写磁盘。
如果磁盘使用率很高,可能需要检查文件系统是否有问题,或者是否有日志文件过大,数据库查询没优化导致大量磁盘操作。
当系统突然变慢时,可以按照以下步骤逐步排查问题,结合工具快速定位瓶颈:
磁盘I/O瓶颈
查看磁盘负载:
iostat -x 1:关注%util(利用率)和await(I/O等待时间),若接近100%说明磁盘饱和。iotop:定位高I/O进程。
文件系统分析:
df -h:检查磁盘空间是否耗尽。du -sh /*逐层查找大文件。lsof +L1:查看被删除但未释放空间的文件(未关闭句柄)。
网络问题也可能导致系统变慢,比如网络带宽被占满,或者有大量TCP连接。
可以用iftop或者nethogs来查看网络流量,确定是哪个进程在占用带宽。
另外,检查是否有大量的TIME_WAIT状态的连接,或者是否有DDoS攻击的情况。
当系统突然变慢时,可以按照以下步骤逐步排查问题,结合工具快速定位瓶颈:
网络瓶颈
带宽与连接数:
iftop或nethogs:查看实时带宽占用。sar -n DEV 1:统计网络接口流量。
连接状态分析:
netstat -antp或ss -s:检查TIME_WAIT、CLOSE_WAIT过多等问题。tcpdump抓包分析异常流量(如DDoS或异常请求)。
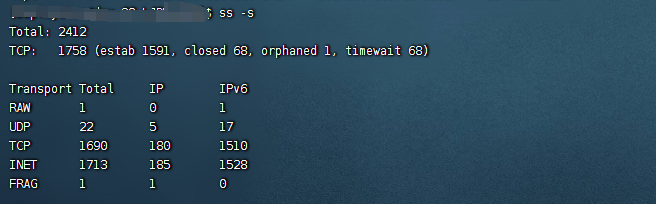
接下来是应用程序层面,比如代码中的死锁、死循环、数据库慢查询等。
可以用jstack(如果是Java应用)来检查线程状态,看是否有死锁。
数据库方面,可以用慢查询日志来分析哪些SQL语句执行时间过长,然后进行优化。
另外,系统日志也很重要,比如/var/log/messages或者dmesg,看看有没有硬件错误或者其他系统级别的错误信息。
具体的步骤顺序。比如,先快速检查CPU、内存、磁盘、网络这四个方面,确定哪里是瓶颈,然后再深入分析相关部分。使用top命令的话,可以按1看各个CPU核心的使用情况,按M按内存排序,按P按CPU排序,这样快速定位问题。
比如,假设运行top后发现某个Java进程CPU使用率特别高,这时候可以用ps -mp [pid] -o THREAD,tid,time查看线程的情况,找到占用高的线程ID,再转换成16进制,用jstack导出线程栈,看看具体在执行什么代码,是否有死循环或者频繁的GC。
应用程序与日志分析
应用日志:
查看应用日志(如
tail -f /var/log/app/error.log),搜索异常堆栈或高频错误。
JVM分析:
jstat -gc <PID>观察GC频率和耗时。jstack <PID>检查死锁或线程阻塞。
比如Redis的大Key、热Key、慢查询,以及MySQL大事务和慢SQL,特别是在高负载或复杂系统中常见的Redis和MySQL问题。
首先,对于Redis的大Key和热Key,大Key可能导致内存不均、阻塞请求,而热Key可能导致某个实例负载过高。比如使用redis-cli的--bigkeys选项,或者使用monitor命令结合分析工具。另外,热Key可能需要通过缓存拆分、本地缓存或使用Redis的集群模式来分散压力。
然后是Redis的慢查询,需要检查慢查询日志,使用slowlog get命令,并分析原因,比如复杂命令、数据量过大等,并给出优化建议,如拆分命令、使用批量操作等。
对于MySQL,大事务可能导致锁竞争、主从延迟等问题,需要检查长时间运行的事务,使用SHOW PROCESSLIST或查询information_schema.innodb_trx表。慢SQL则需要开启慢查询日志,使用EXPLAIN分析执行计划,优化索引或查询结构。
此外,还需要考虑MySQL的锁和死锁情况,使用SHOW ENGINE INNODB STATUS检查锁信息,以及连接数是否过高等问题,这些都可能影响系统性能。
如果是内存问题,可能要看是否有内存泄漏,用jmap或者VisualVM之类的工具分析堆内存。如果是磁盘I/O问题,可能需要检查是否在大量写日志,或者数据库的索引没优化导致全表扫描。
中间件(如Redis、MySQL)的影响非常关键!实际排查中,这些组件的问题往往是系统变慢的核心原因。以下补充 中间件专项排查 的思路和工具:
中间件专项排查
Redis 问题分析
常见问题:大Key、热Key、慢查询、连接数激增、内存不足等。
大Key检测:
# 扫描大Key(可能阻塞生产环境,建议在从节点执行) redis-cli --bigkeys输出结果中的
Largest string、Largest list等即为大Key。风险:大Key导致内存不均、网络阻塞、持久化延迟。
热Key定位:
监控工具:
redis-cli --hotkeys(需开启maxmemory-policy为 LFU)。代理层统计:如 Codis、Twemproxy 可记录Key访问频率。
代码埋点:在客户端记录高频访问的Key。
慢查询分析:
# 查看慢查询日志(需提前配置 slowlog-log-slower-than) redis-cli slowlog get 10 # 获取最近10条慢查询常见原因:
KEYS *、复杂Lua脚本、大范围HGETALL等。
内存与淘汰策略:
redis-cli info memory # 查看内存使用详情关注
used_memory、maxmemory、evicted_keys(因内存不足被淘汰的Key数)。内存碎片:
mem_fragmentation_ratio> 1.5 需重启或使用memory purge(Redis 4+)。
MySQL 问题分析
常见问题:慢SQL、锁竞争、大事务、连接数过载、主从延迟等。
慢SQL排查:
开启慢查询日志:
SET GLOBAL slow_query_log = ON; SET GLOBAL long_query_time = 1; -- 定义慢查询阈值(秒)分析工具:
mysqldumpslow -s t /path/to/slow.log # 按耗时排序 pt-query-digest /path/to/slow.log # Percona Toolkit 详细分析
大事务与锁竞争:
查看运行中的事务:
SELECT * FROM information_schema.innodb_trx; -- 事务详情 SHOW ENGINE INNODB STATUS; -- 锁信息(关注 TRANSACTIONS 段)长事务监控:
SELECT * FROM sys.session WHERE time > 60; -- 查询执行超60秒的会话
连接数过载:
SHOW STATUS LIKE 'Threads_connected'; -- 当前连接数 SHOW VARIABLES LIKE 'max_connections'; -- 最大连接数若连接数接近
max_connections,需检查连接泄漏或考虑扩容。
主从延迟:
SHOW SLAVE STATUS\G关注
Seconds_Behind_Master(主从延迟秒数)。原因:大事务、从库性能差、网络抖动。
消息队列(如Kafka、RocketMQ)
积压监控:
kafka-consumer-groups.sh --describe --group <group_id> # Kafka查看消费延迟积压风险:消费者处理能力不足、消息分区不均。
消息堆积处理:
扩容消费者实例。
优化消费逻辑(如批量处理、异步化)。
中间件优化案例
场景1:Redis变慢
现象:Redis响应时间波动,CPU使用率不高但延迟高。
排查:
redis-cli info stats查看total_net_input_bytes和total_net_output_bytes,确认是否因大Key导致网络阻塞。redis-cli monitor抽样请求,发现频繁执行HGETALL操作大Hash。
解决:拆分大Hash为多个小Key,改用
HMGET按需获取字段。场景2:MySQL批量插入卡顿
现象:批量插入数据时,系统卡顿,磁盘I/O飙升。
排查:
SHOW PROCESSLIST发现大量INSERT ... VALUES (...), (...)语句。iostat -x 1显示磁盘%util持续100%。
解决:
调整批量插入的批次大小(减少单次写入量)。
关闭
autocommit,合并事务提交。
排查工具补充
Redis:
redis-cli --stat:实时监控Redis状态。redis-rdb-tools:分析RDB文件,统计大Key分布。
MySQL:
pt-query-digest:分析慢查询日志。sysbench:压力测试数据库性能。
另外,系统变慢还可能是因为最近有更新或者配置变更,这时候可以检查最近的变更记录,或者用系统性能监控工具(如Prometheus+Grafana)查看历史数据,对比变化前后的指标。
不过,可能还需要考虑外部因素,比如被攻击,或者依赖的服务变慢,导致整个系统卡顿。这时候需要检查网络连接和外部服务状态。
总结一下,我的思路应该是:
整体资源监控(top, vmstat, iostat, iftop)
确定资源瓶颈(CPU、内存、磁盘、网络)
针对具体瓶颈深入分析(进程、线程、代码)
检查系统日志和应用程序日志
中间件(数据库、redis、消息队列)
考虑外部因素和近期变更
总之,整个过程需要有条理地逐步缩小问题范围,结合多个工具的数据综合分析,找到根本原因。
👉 欢迎加入小哈的星球,你将获得: 专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
新项目:《从零手撸:仿小红书(微服务架构)》 已完结,基于 Spring Cloud Alibaba + Spring Boot 3.x + JDK 17..., 点击查看项目介绍;演示地址:http://116.62.199.48:7070/
《从零手撸:前后端分离博客项目(全栈开发)》 2期已完结,演示链接:http://116.62.199.48/;
专栏阅读地址:https://www.quanxiaoha.com/column
截止目前,累计输出 90w+ 字,讲解图 3713+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,Spring Cloud Alibaba 等等,戳我加入学习,解锁全部项目,已有3300+小伙伴加入


1. 我的私密学习小圈子,从0到1手撸企业实战项目~ 2. SpringBoot 公共字段自动填充的6种神技,开发效率飙升! 3. 循环中使用 Thread.sleep,代码评审被老板喷了 4. Java 21 新特性的实践,确实很丝滑!最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。 获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。PS:因公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。 点“在看”支持小哈呀,谢谢啦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









