





介绍 (Introduction)
If you are new to Reddit, Reddit is basically a large group of public forums where users can pretty much talk about anything. Since there is a wide range of these public forums Reddit has been dubbed the “front page of the internet.” Being the front page of the internet comes with a lot of people posting in these public forums also called subreddits. According to Reddit’s blog they had 199 million posts in 2019 alone and approximately 138,000 active subreddits. With so much information, how do they make sure people are posting in the right subreddits? Well they don’t. So, how can Reddit ensure that posts are going into the proper subreddit’s? Through a recommendation system!
如果您是Reddit的新手,那么Reddit基本上是一整套公共论坛,用户可以在其中谈论任何事情。 由于存在众多此类公共论坛,因此Reddit被称为“互联网首页”。 作为互联网的首页,有很多人在这些公共论坛上发帖,也称为subreddits。 根据Reddit的博客 ,仅在2019年,他们就有1.99亿个帖子和大约138,000个活跃的subreddit。 拥有如此多的信息,他们如何确保人们在正确的子目录中发布内容? 好吧,他们没有。 那么,Reddit如何确保帖子进入正确的subreddit呢? 通过推荐系统!
什么是推荐系统? (What is a Recommendation System?)
A recommendation system is an important class of algorithms in machine learning that offers relevant suggestions to a user. How does this apply to Reddit? When a user is creating a post they need to decide what subreddit the post should belong to. With 138,000 active subreddit’s this could be a hard choice since the post could potentially belong to a couple different subreddits. A solution to this problem would be by implementing a recommendation system. When a user is writing their post instead of having to pick the subreddit they want to post in, there could be a suggested button that recommends which subreddit that post should belong to.
推荐系统是机器学习中的一类重要算法,可为用户提供相关建议。 这如何适用于Reddit? 用户创建帖子时,他们需要确定帖子应属于哪个子目录。 拥有138,000个活跃的subreddit,这可能是一个艰难的选择,因为该职位可能会属于几个不同的subreddit。 解决该问题的方法是实施推荐系统。 当用户编写其帖子而不需要选择他们要发布的子reddit时,可能会有一个建议按钮,建议该帖子应属于哪个子reddit。
What are the benefits of Reddit implementing a recommendation system?
Reddit实施推荐系统的好处是什么?
- Cleaner subreddits. 清洁subreddits。
- More accurate advertising. 更准确的广告。
- Reduce the workload for reddit moderators. 减少Reddit版主的工作量。
- Easier posting for users. 便于用户发布。
- Accumulating massive amounts of text data. 积累大量的文本数据。
Now that we have an understanding of Reddit and a high level overview of what a recommendation is and what they could do in this case let’s move onto the coding!
现在,我们对Reddit有了一个了解,并对建议是什么以及在这种情况下他们可以做什么进行了高级概述,让我们继续进行编码!
数据 (Data)
For the recommendation system to give an accurate suggestion on where the post should go we will need a lot of data. I scraped 31,299 posts using the Pushshift API from the subreddits r/MachineLearning and r/artificial totaling 62,598 posts, which included the title of the post and the content of the post.
为了使推荐系统能够准确地建议该职位应该去哪里,我们将需要大量数据。 我使用子目录 r / MachineLearning和r / artificial使用Pushshift API抓取了31,299条帖子,总共62,598条帖子,包括帖子的标题和帖子的内容。
I chose these two subreddits since they are very related topics with a lot of overlapping content. If the recommendation system could perform decently well on topics such as these I am confident it can be applied to a lot more subreddits in the future.
我选择了这两个子主题,因为它们是非常相关的主题,内容很多。 如果推荐系统在诸如此类的主题上能够表现出色,我相信将来可以将其应用于更多细分项目。
After scraping all of the posts I now have to prepare this data for natural language processing!
抓取所有帖子后,我现在必须准备此数据以进行自然语言处理!
Since I am pulling this data from the “front page of the internet,” there were a couple of cleaning steps I had to conduct before moving on to the modeling process. Since a lot of my posts contained links, images, emojis, and other text that I could not use I had to remove these and I did this by using regex. Regex is a tool that enables you to do many things but I used it for text replacement. Since character such as “/(){}\[\]\|@,;,” would not help in classifying a post. I removed these and simply replaced them with a space.
由于我是从“互联网首页”提取这些数据的,因此在进入建模过程之前,我必须执行几个清理步骤。 由于我的很多帖子都包含我无法使用的链接,图像,表情符号和其他文本,因此必须删除它们,并使用正则表达式进行了此操作。 正则表达式是使您能够执行许多操作的工具,但我将其用于替换文本。 由于诸如“ /() {} \ [\] \ | @,;,”之类的字符将无助于对帖子进行分类。 我删除了这些,只是用空格替换了它们。
Another common NLP task is to remove stop words and that’s exactly what I did. Stop words are words that do not add much meaning to a sentence such as “the”, “they”, “is”, etc.
NLP的另一个常见任务是删除停用词,而这正是我所做的。 停用词是对句子没有多大意义的词,例如“ the”,“ they”,“ is”等。
Since we just removed all of the words and characters that do not add much to a sentence let’s take a look at some of the most common words in each subreddit.
由于我们只删除了不会对句子增加太多的所有单词和字符,因此让我们看一下每个subreddit中一些最常用的单词。
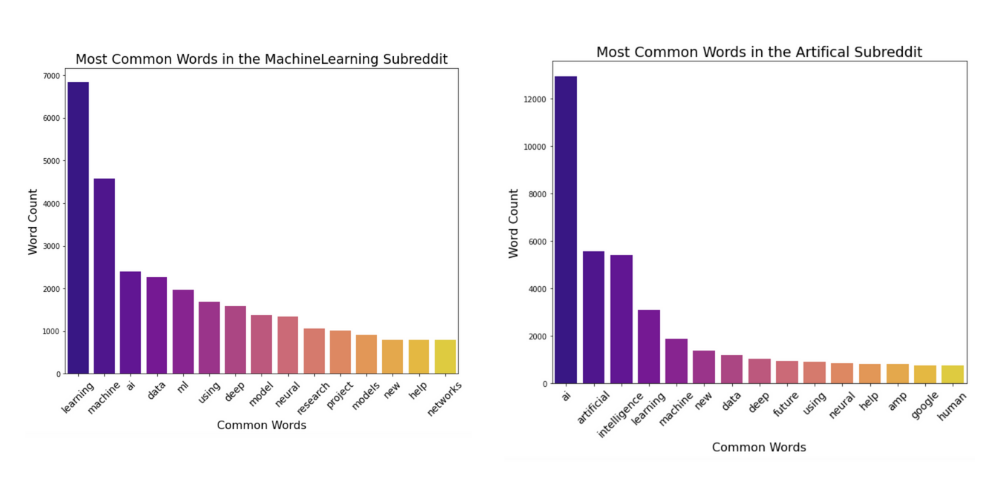
We can see above that there were a lot of overlapping words that I thought could potentially have a big impact on model performance since these topics are so similar.
在上面我们可以看到,由于这些主题是如此相似,我认为有很多重叠的词可能会对模型性能产生重大影响。
I repeated this process for the title of the post and the content of the post. After doing these necessary tasks to prepare my data and analyzing the words we can finally move onto the fun stuff (at least to me)!
我对帖子标题和帖子内容重复了此过程。 完成这些必要的任务以准备我的数据并分析了单词之后,我们终于可以使用有趣的东西了(至少对我而言)!
造型 (Modeling)
The data is now clean and ready to be modeled. Before jumping right into modeling we have to vectorize our words. Using CountVectorizer I was able to turn my boring text data that I couldn’t use into tokenized versions of that text that I can use! I won’t go in depth into what CountVectorizer does here but this is a great blog post that explains it thoroughly.
现在,数据已清除,可以进行建模了。 在进入建模之前,我们必须向量化单词。 使用CountVectorizer,我可以将我无法使用的无聊文本数据转换为可以使用的文本的标记化版本! 我不会在这里深入了解CountVectorizer的功能,但这是一篇很棒的博客文章 ,对它进行了详尽的解释。
Since the data has now been vectorized I can now begin modeling. Before modeling I had to establish my baseline accuracy score. This score was 50% since I had perfectly balanced classes. This was the score to beat!
由于数据已被矢量化,因此我现在可以开始建模。 在建模之前,我必须建立基准精度得分。 由于我的课堂完全平衡,所以该分数为50%。 这是要击败的分数!
I chose three different classification models to use for this project. Logistic regression, multinomial naive bayes and a long short term memory neural network (LSTM RNN). One of the goals of this project was to see if the content of the post had any affect on the accuracy score so I ran the models on just the title and then on the title and content of the post.
我为该项目选择了三种不同的分类模型。 Logistic回归,多项式朴素贝叶斯和长期短期记忆神经网络(LSTM RNN)。 该项目的目标之一是查看帖子的内容是否对准确性得分产生影响,因此我仅对标题进行了建模,然后对帖子的标题和内容进行了建模。
We can see below the accuracy scores for the models I ran:
我们可以在下面看到我运行的模型的准确性得分:

The grid searched multinomial naive bayes model had the highest accuracy coming in at 86.15%! This was an increase of 36.15% .
网格搜索的多项朴素贝叶斯模型具有最高的准确率,为86.15%! 增长了36.15%。
In the picture below we can see the accuracy score I was able to achieve with the LSTM RNN:
在下面的图片中,我们可以看到我使用LSTM RNN可以达到的精度得分:

Although this accuracy score was 4.55% less than my best model this will be the model I use for my production model. I believe the model performed slightly worse because I only used the titles of the post for this model. LSTM RNN’s shine when they can fully understand the sequential nature of the data. So, I believe that adding the content of each post would greatly increase this score. I couldn’t test this theory out due to computing constraints and time restrictions
尽管此准确性得分比我的最佳模型低4.55%,但这将是我用于生产模型的模型。 我相信该模型的效果会稍差一些,因为我只使用了该模型的帖子标题。 当LSTM RNN可以完全理解数据的顺序性质时,它们将大放异彩。 因此,我相信添加每个帖子的内容将大大提高该分数。 由于计算限制和时间限制,我无法验证该理论
Choosing this model is very important because when trying to create the recommendation system I will need a model that can take in massive amounts of data and provide a great accuracy score with a low misclassification rate. This model has a lot of room to be optimized and fed more data so this is why I chose it as the production model.
选择此模型非常重要,因为在尝试创建推荐系统时,我将需要一个模型,该模型可以接收大量数据,并以较低的误分类率提供较高的准确性得分。 该模型有很大的空间可以优化并提供更多数据,因此这就是我选择它作为生产模型的原因。
结论 (Conclusions)
Since I verified that even with very close topics I can achieve an accuracy score of 81.60% on a model that has a lot of room for growth, I believe that this is a high enough accuracy score to continue with future developments of this project.
由于我已经验证了即使主题非常接近,在具有很大增长空间的模型上我也可以达到81.60%的准确性得分,因此我相信这是一个足够高的准确性得分,可以继续该项目的未来发展。
Although I got a pretty decent accuracy score for these two subreddits it is very important to remember that this model was only trained on only these two subreddits. So, this begs the question if this is truly possible to do with all of the subreddits?
尽管我在这两个子redredit上获得了相当不错的准确性得分,但是记住此模型仅在这两个子reddits上进行训练非常重要。 因此,这就引出了一个问题,即是否真的有可能对所有子项进行处理?
未来的步骤 (Future Steps)
To be able to self classify the post as it is being written I will need a lot of data. In the future I plan to scrape Reddit and pull 2,000 posts from each active subreddit. According to Reddit there are only 138,000 active subreddits so if I only pulled 2,000 posts from those subreddits I will have in total 276 million posts to work with. Scraping these posts will take some time and storage. Scraping the 276 million posts and gathering 2,000 posts from each subreddit would take approximately 24 hours using a multi threading scraping process. The final file would approximately be around 150 GB as well.
为了能够对正在撰写的帖子进行自我分类,我将需要大量数据。 将来,我计划删除Reddit,并从每个活动的subreddit中提取2,000个帖子。 根据Reddit的介绍,只有138,000个活跃的subreddit,因此,如果我仅从这些subreddit中撤出2,000个帖子,我总共将有2.76亿个帖子可以使用。 删除这些帖子将需要一些时间和存储空间。 使用多线程抓取过程,要刮掉2.76亿个帖子并从每个subreddit收集2,000个帖子,大约需要24小时。 最终文件也将约为150 GB。
Once this data is collected I plan to develop a better version of my LSTM RNN so it can learn over time with all of that collected data. However, before trying to run a model on all of the data I will take 10 different subreddits and see if my model can predict with a satisfactory accuracy score. If this model cannot beat the baseline accuracy score we now will know that this project is not possible. If it does pass this score we can continue adding subreddits and scaling up the model.
收集完这些数据后,我计划开发一个更好的LSTM RNN版本,以便它可以随着时间的推移学习所有收集到的数据。 但是,在尝试对所有数据运行模型之前,我将采用10个不同的子reddit,并查看我的模型是否可以以令人满意的准确性得分进行预测。 如果该模型不能超过基准精度分数,我们现在将知道该项目是不可能的。 如果它确实超过了此分数,我们可以继续添加子reddit并扩大模型。
If Reddit implements this idea this is an example mockup of what it could potentially look like:
如果Reddit实现了这个想法,那么这就是它可能看起来像的示例样机:
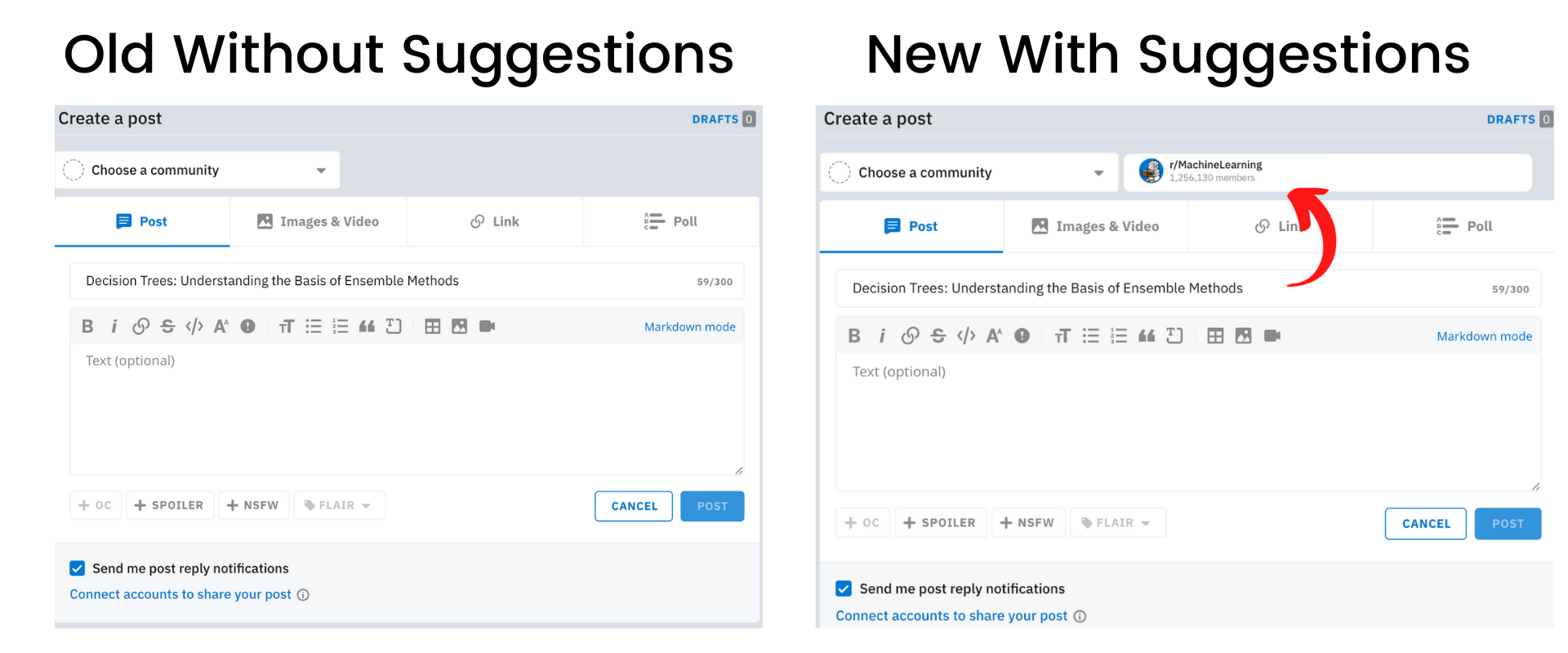
Adding a clean suggestion box such as the one above will allow users to see the suggestion and either click that subreddit if they are unsure or they can still specify which subreddit they would like to post in.
添加一个干净的建议框(例如上面的那个)将使用户看到该建议,并在不确定时单击该子Reddit,或者仍然可以指定要在其中张贴的子Reddit。
In the future I plan to add a lot more models such as a random forest, SVM, and optimizing the current LSTM RNN that I have. After adding these models I will be able to determine which is the best production NLP text classification model for the task of creating an efficient and accurate subreddit recommendation system.
将来,我计划添加更多模型,例如随机森林,SVM,并优化现有的LSTM RNN。 添加这些模型后,我将能够确定哪种是最佳的生产NLP文本分类模型,以创建高效,准确的subreddit推荐系统。
结语 (Wrapping Up)
I will be adding the GitHub link when the code is completed and finalized!
代码完成并完成后,我将添加GitHub链接!
Hopefully you enjoyed this read and any feedback would be greatly appreciated. If you enjoyed reading this article, drop me a comment or maybe connect with me on LinkedIn!
希望您喜欢这篇阅读,任何反馈将不胜感激。 如果您喜欢阅读本文,请给我留言或在LinkedIn上与我联系!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









